装载与动态链接
本文摘自《程序员的自我修养》
可执行文件的装载与进程
进程虚拟地址空间
程序和进程有什么区别
程序是一个静态的概念,它就是一些预编译好的指令和数据集合的一个文件;进程则是一个动态的概念,它是程序运行时的一个过程,很多时候把动态库叫做运行时(Runtime)也有一定的含义。
每个程序被运行起来以后,它将拥有自己独立的虚拟地址空间 ,这个虚拟地址空间的大小由计算机的硬件平台决定,具体地说是由CPU的位数决定的。硬件决定了地址空间的最大理论上限,即硬件的寻址空间大小,比如32位的硬件平台决定了虚拟地址空间的地址为0到2^32^-1,即0x00000000 ~ 0xFFFFFFFF,也就是常说的4GB虚拟空间大小;而64位的硬件平台具有64位寻址能力,它的虚拟地址空间达到了2^64^字节,即0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF总共17179869184GB,这个寻址能力从现在来看,几乎是无限的。
从程序的角度来看,我们可以通过判断C语言程序中的指针所占的空间来计算虚拟地址空间的大小。一般来说,C语言指针大小的位数与虚拟空间的位数相同,如32位平台下的指针为32位,即4字节;64位平台下的指针为64位,即8字节。
那么32位平台下的4GB虚拟空间,我们的程序是否可以任意使用呢?很遗憾,不行。因为程序在运行的时候处于操作系统的监管下,操作系统为了达到监控程序运行等一系列目的,进程的虚拟空间都在操作系统的掌握之中。进程只能使用那些操作系统分配给进程的地址,如果访问未经允许的空间,那么操作系统就会捕获到这些访问,将进程的这种访问当作非法操作,强制结束进程。我们经常在Windows下碰到令人讨厌的“进程非法操作需要关闭”或Linux下的“Segmentation fault”很多时候是因为进程访问了未经允许的地址。
那么到底这4GB的进程虚拟地址空间是怎样的分配状态呢?首先以Linux操作系统作为例子,默认情况下,Linux操作系统将进程的虚拟地址空间做了如下图所示的分配。
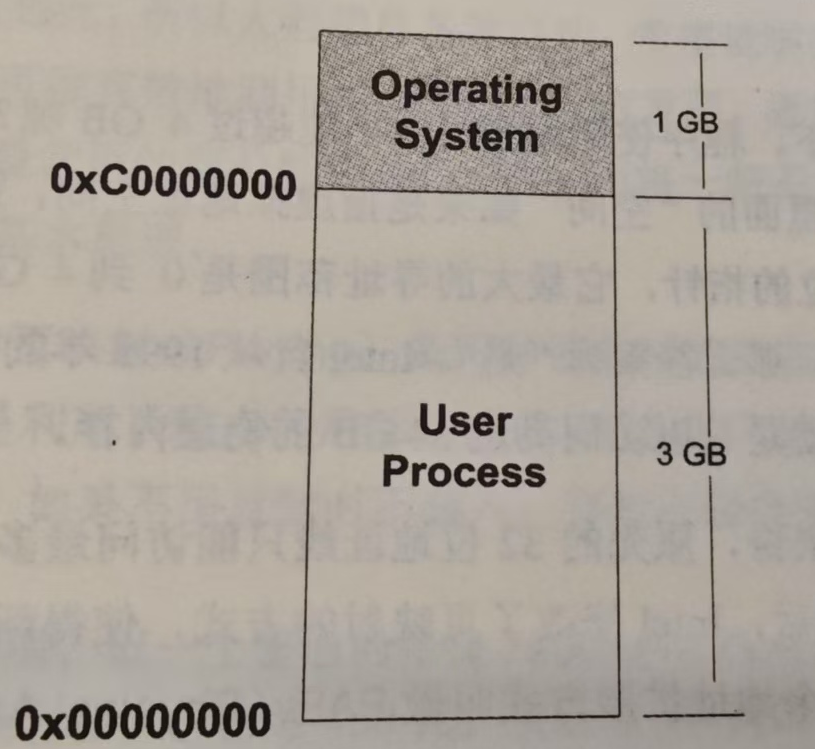
整个4GB被划分成两部分,其中操作系统本身用去了一部分:从地址0xC0000000到0xFFFFFFFF,共1GB。剩下的从0x00000000地址开始到0xBFFFFFFF共3GB的空间都是留给进程使用的。那么从原则上来讲,进程最多可以使用3GB的虚拟空间,也就是说整个进程在执行的时候,所有的代码、数据包括通过C语言malloc()等方法申请的虚拟空间之和不可以超过3GB。
PAE
内存空间:物理内存空间,指的是计算机系统中实际存在的物理内存(RAM)的总量。它是CPU通过地址总线可以直接访问的内存范围。硬件实际存在的内存,由RAM芯片组成。大小由CPU的地址总线宽度决定。例如,32位地址总线:可寻址2^32^个内存位置即4GB,36位地址总线:可寻址2^36^个内存位置,即64GB。CPU可通过物理地址直接访问内存中的数据。
虚拟地址空间:虚拟地址空间是操作系统为每个进程提供的抽象内存空间。每个进程都认为自己独享整个内存空间,而实际上这些内存可能映射到物理内存或磁盘上的交换空间(如页面文件)。虚拟地址空间是操作系统为每个进程提供的逻辑内存试图,独立于物理内存。大小由CPU的位数决定。例如,32位CPU:每个进程的虚拟地址空间为4GB(2^32^),64位CPU:每个进程的虚拟地址空间为17179869184GB,不过通常为128TB
32位地址线只能访问最多4GB物理内存。扩展至36位地址线之后,Intel修改了页映射的方式,使得新的映射方式可以访问到更多的物理内存。Intel把这个地址扩展方式叫做PAE。
扩展的物理地址空间,对于普通程序来说是感觉不到它的存在。因为这是操作系统做的事。在应用程序里,只有32位虚拟地址空间。那么应用程序该如何使用这些大于常规的内存空间呢?一个常见方法就是操作系统提供一个窗口映射的方法,把这些额外的内存映射到进程地址空间中来。应用程序可以根据需要来选择申请和映射,比如一个应用程序中0x10000000 ~ 0x20000000这一段256MB的虚拟地址空间用来做窗口,程序可以从高于4GB的物理空间中申请多个大小为256MB的物理空间,编号为A、B、C等,然后根据需要将这个窗口映射到不同的物理空间块,用到A时将0x1000000~`0x20000000`映射到A,用到B、C时再映射过去。在Windows下,这种访问内存的操作方式叫做(AWE);而像Linux等UNIX类操作系统则采用mmap()系统调用来实现。
装载的方式
程序执行时所需要的指令和数据必须在内存中才能够正常运行,最简单的办法就是将程序运行所需要的指令和数据全都装入内存,这样程序就可以顺利运行,这就是最简单的静态装入的办法。但是,很多情况下程序所需要的内存数量大于物理内存的数量,当内存的数量不够时,根本的解决办法就是添加内存。相对于磁盘来说,内存是昂贵且稀有的,这种情况自计算机磁盘诞生以来一直如此。所以要尽可能用少的内存运行更多的程序,尽可能有效地利用内存。后来,程序运行时是有局部性原理的,所以我们可以将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就是动态装入的基本原理。
覆盖装入(Overlay)和页映射(Paging)是两种很典型的动态装载方法,它们所采用的思想都差不多,原则上都是利用了程序的局部性原理。动态装入的思想是程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中。
从操作系统角度看可执行文件的装载
进程的建立
事实上,从操作系统的角度来看,一个进程最关键的特征是它拥有独立的虚拟地址空间,这使得它有别于其他进程。很多时候一个程序被执行同时都伴随着一个新的进程的创建,那么我们就来看看这种最通常的情形:创建一个进程,然后装载相应的可执行文件并且执行。在有虚拟存储的情况下, 上述过程最开始只需要做三件事情:
- 创建一个独立的虚拟地址空间
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动运行
**首先是创建虚拟地址空间。**虚拟空间由一组页映射函数将虚拟空间的各个页映射至相应的物理空间,那么创建一个虚拟空间实际上并不是创建空间而是创建映射函数所需要的相应的数据结构,在i386的Linux下,创建虚拟地址空间实际上只是分配一个页目录就可以了,甚至不设置页映射关系,这些映射关系等到后面程序发生页错误的时候再进行设置。
**读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。**上面那一步的页映射关系函数是虚拟空间到物理空间的映射关系,这一步所做的是虚拟空间与可执行文件的映射关系。当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将该“缺页”从磁盘中读取到内存中,再设置缺页的虚拟页和物理页的映射关系,这样程序才得以正常运行。但是很明显的一点是,当操作系统捕获到缺页错误时,它应当知道程序当前所需要的页在可执行文件中的哪一个位置。这就是虚拟空间与可执行文件之间的映射关系。
由于可执行文件在装载时实际上是被映射的虚拟空间,所以可执行文件很多时候又被叫做映像文件(image)。
将CPU指令寄存器设置成可执行文件入口,启动运行。 第三步其实也是最简单的一步,操作系统通过设置CPU的指令寄存器将控制权转交给进程,由此进程开始执行。这一步看似简单,实际上在操作系统层面上比较复杂,它涉及内核堆栈和用户堆栈的切换、CPU运行权限的切换。不过从进程的角度看这一步可以简单地认为操作系统执行了一条跳转指令,直接跳转到可执行文件的入口地址。ELF文件头中保存有入口地址
动态链接
要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不再将它们静态地链接在一起。简单地讲,就是不对那些组成程序的目标文件进行链接,等到程序要运行时才进行链接。也就是说,把链接这个过程推迟到了运行时再进行,这就是动态链接的基本思想。
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有的程序模块都链接成一个单独的可执行文件。在Linux系统中,ELF动态链接文件被称为动态共享对象,简称共享对象,它们一般都是以”.so”为扩展名的一些文件;而在Windows系统中,动态链接文件被称为动态链接库,它们通常就是我们平时很常见的以”.dll”为扩展名的文件。
从本质上讲,普通可执行程序和动态链接库中都包含指令和数据,这一点没有区别。在使用动态链接库的情况下,程序本身被分为了程序主要模块和动态链接库,但实际上它们都可以看作是整个程序的一个模块。
在Linux中,常用的C语言库的运行库glibc,它的动态链接形式的版本保存在“/lib”目录下, 文件名叫做”libc.so”。整个系统只保留一份C语言库的动态链接文件“libc.so”,而所有的C语言编写的、动态链接的程序都可以在运行时使用它。当程序被装载的时候,系统的动态链接器会讲程序所需要的动态链接库装载到进程的地址空间,并且将程序中所有未决议的符号绑定到相应的动态链接库中,并进行重定位工作。
延迟绑定
在动态链接下,程序模块之间包含了大量的函数引用,所以在程序执行之前,动态链接会耗费不少时间用于解决模块之间的函数引用的符号查找以及重定位,因此会减慢动态链接性能。如果一开始就把所有函数都链接好实际上是一种浪费。所以ELF采用一种叫做延迟绑定的做法,基本思想就是当函数第一次被用到时才进行绑定,如果没有用到则不进行绑定。所以程序开始执行时,模块间的函数调用都没有进行绑定,而是需要用到时才由动态链接器来负责绑定。这样的做法可以大大加快程序的启动速度,特别有利于一些有大量函数引用和大量模块的程序。
ELF使用PLT(Procedure Linkage Table)的方法来实现,这种方法使用了一些很精巧的指令序列来完成。在开始详细介绍之前,我们先从动态链接器的角度设想一下:假设liba.so需要调用libc.so中的bar()函数,那么当liba.so中第一次调用bar()函数时,这时候就需要动态链接器中的某个函数来完成地址绑定工作,假设这个函数叫做lookup(),那么lookup()需要知道哪些必要的信息才能完成这个函数地址绑定工作呢?我想答案很明显,lookup()至少需要知道这个地址绑定发生在哪个模块,哪个函数?那么我们可以假设lookup的原型为lookup(module, function),这两个参数的值在我们这个例子中分别为liba.so和bar()。在Glibc中,这里的lookup函数真正的名字叫_dl_runtime_resolve()。
当我们调用某个外部模块的函数时,如果按照通常的做法应该是通过GOT中相应的项进行间接跳转。PLT为了实现延迟绑定,在这个过程中又增加了一层间接跳转。调用函数并不直接通过GOT跳转,而是通过一个叫作PLT项的结构来进行跳转。每个外部函数在PLT中都有一个相应的项,比如bar()函数在PLT中的项的地址我们称之为bar@plt。让我们来看看bar@plt的实现:
1 | |
bar@plt的第一条指令是一条通过GOT间接跳转的指令。bar@GOT表示GOT中保存bar()这个函数相应的项。如果链接器在初始化阶段已经初始化该项,并且将bar()的地址填入该项,那么这个跳转指令的结果就是我们所期望的,跳转到bar(),实现函数正确调用。但是为了实现延迟绑定,链接器在初始化阶段并没有将bar()的地址填入到该项,而是将上面代码中第二条指令”push n”的地址填入到bar@GOT中,这个步骤不需要查找任何符号,所以代价很低。很明显,第一条指令的效果是跳转到第二条指令,相当于没有进行任何操作。第二条指令将一个数字n压入堆栈中,这个数字是bar这个符号引用在重定位表”.rel.plt”中的下标。接着又是一条push指令将模块的ID压入到堆栈,然后跳转到_dl_runtime_resolve。这实际上就是在实现我们前面提到的lookup(module, function)这个函数的调用:先将所需要决议符号的下标压入堆栈,再将模块ID压入堆栈,然后调用动态链接器的_dl_runtime_resolve函数来完成符号解析和重定位工作。_dl_runtime_resolve在进行一系列工作以后将bar()真正地址填入到bar@GOT中。
一旦bar()这个函数被解析完毕,当我们再次调用bar@plt时,第一条jmp指令就能够跳转到真正的bar()函数中,bar()函数返回的时候会根据堆栈里面保存的EIP直接返回到调用者,而不会再继续执行bar@plt中第二条指令开始的那段代码,那段代码只会在符号未被解析时执行一次。
上面描述的是PLT的基本原理,PLT真正的实现要比它的结构稍微复杂一点。