dog@dog:~/swift/usr/bin$ lldb --version lldb version 17.0.0 (https://github.com/swiftlang/llvm-project.git revision 3a02857b159678d97e33f8c5032541c3ddd5f1f6) Swift version 6.2-dev (LLVM 3a02857b159678d, Swift c91e29523420c00)
Vscode调试swift项目时会存在BUG,调试时无法获取变量的值,也无法获得任何有用信息。即鼠标悬停在变量时,出现Unable to determine byte size,解决方案:Codelldb Debugging problems
以下是使用vscode调试时的launch.json文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version":"0.2.0", "configurations":[
CodeGenerator("FunctionCallGenerator") { b in let function = b.randomVariable() let arguments = [b.randomVariable(), b.randomVariable(), b.randomVariable()] b.callFunction(f, with: arguments) }
CodeGenerator("FunctionCallGenerator") { b in let function = b.randomVariable(ofType: .function()) let arguments = b.randomArguments(forCalling: function) b.callFunction(f, with: arguments) }
let v0 = "foobar"; // .string + .object(...) + .array // the object part contains all the standard string methods and properties
let v0 = { valueOf() { ...; return13.37; }}; // .object(...) + .float // The object can be used for numerical operations since it has a meaningful // conversion operator defined (a custom valueOf method with known signature). // Note: this is not yet implemented, currently the type would just be .object
let v0 = [...]; // .array + .object(...) // the JavaScript array is clearly an array (can be iterated over) but also // exposes properties and methods and as such is also an object
classv0 { ... foo() { ... }; bar() { ... } }; // .constructor([...] => .object(...)) // The variable v0 is a constructor with the parameters indicated by its // constructor and which returns an object of the v0 "group" with certain // properties and methods (e.g. foo and bar)
请注意,生成器如何小心地生成正确且有意义的代码,同时又不对其输入要求过于严格。 它的做法是声明它“希望”接收数字作为输入(这意味着如果有可用的变量,则应使用数字调用它,但也可以使用不同类型的变量调用),然后检查其中一个输入是否可能是 BigInts(在这种情况下,很可能会出现运行时异常:“TypeError: Cannot mix BigInt and other types, use explicit conversions”),如果是,则将操作标记为受保护的(导致在运行时使用 try-catch)。
CodeGenerator("BuiltinGenerator") { b in b.loadBuiltin(b.randomBuiltin()) },
CodeGenerator("FunctionCallGenerator", inputs: .preferred(.function())) { b, f in let arguments = b.randomArguments(forCalling: f) let needGuard = b.type(of: f).MayNotBe(.function()) // 技术上,如果参数类型与签名不匹配,也需要保护 b.callFunction(f, withArgs: arguments, guard: needGuard) },
CodeGenerator("ComputedPropertyAssignmentGenerator", inputs: .preferred(.object())) { b, obj in let propertyName = b.randomVariable() let value = b.randomVariable() let needGuard = b.type(of: obj).MayBe(.nullish) b.setComputedProperty(propertyName, of: obj, to: value, guard: needGuard) },
funcloadCorpus(fromdirPath: String) -> [Program] { var isDir: ObjCBool=false guardFileManager.default.fileExists(atPath: dirPath, isDirectory: &isDir) && isDir.boolValue else { logger.fatal("Cannot import programs from \(dirPath), it is not a directory!") }
var programs = [Program]() let fileEnumerator =FileManager.default.enumerator(atPath: dirPath) // 遍历目录的每个文件 whilelet filename = fileEnumerator?.nextObject() as?String { guard filename.hasSuffix(".fzil") else { continue } let path = dirPath +"/"+ filename do { let data =tryData(contentsOf: URL(fileURLWithPath: path)) let pb =tryFuzzilli_Protobuf_Program(serializedBytes: data) let program =tryProgram.init(from: pb) if!program.isEmpty { programs.append(program) } } catch { logger.error("Failed to load program \(path): \(error). Skipping") } }
// 为各个变异器分配权重,如(ExplorationMutator权重为3,更频繁使用)。 // mutator负责根据语料库变异程序并且评估结果 var mutators =WeightedList([ (ExplorationMutator(), 3), (CodeGenMutator(), 2), (SpliceMutator(), 2), (ProbingMutator(), 2), (InputMutator(typeAwareness: .loose), 2), (InputMutator(typeAwareness: .aware), 1), // Can be enabled for experimental use, ConcatMutator is a limited version of CombineMutator // (ConcatMutator(), 1), (OperationMutator(), 1), (CombineMutator(), 1), // Include this once it does more than just remove unneeded try-catch // (FixupMutator()), 1), ])
前面的文档中提及过的FuzzEngine:
1 2 3 4 5 6 7 8 9 10
switch engineName { case"hybrid": engine =HybridEngine(numConsecutiveMutations: consecutiveMutations) case"multi": let mutationEngine =MutationEngine(numConsecutiveMutations: consecutiveMutations) let hybridEngine =HybridEngine(numConsecutiveMutations: consecutiveMutations) let engines =WeightedList<FuzzEngine>([ (mutationEngine, 1), (hybridEngine, 1), ])
// Install signal handlers to terminate the fuzzer gracefully. var signalSources: [DispatchSourceSignal] = [] for sig in [SIGINT, SIGTERM] { // Seems like we need this so the dispatch sources work correctly? signal(sig, SIG_IGN)
// 当主fuzzer完全停止时, 退出这个进程 fuzzer.registerEventListener(for: fuzzer.events.ShutdownComplete) { reason in if resume, let path = storagePath { // Check if we have an old_corpus directory on disk, this can happen if the user Ctrl-C's during an import. ifFileManager.default.fileExists(atPath: path +"/old_corpus") { logger.info("Corpus import aborted. The old corpus is now in \(path +"/old_corpus").") logger.info("You can recover the old corpus by moving it to \(path +"/corpus").") } } exit(reason.toExitCode()) // 整个进程退出, 所有线程被kill } ... }
/// List of all events that can be dispatched in a fuzzer. publicclassEvents { /// Signals that the fuzzer is fully initialized. fuzzer被完全初始化 publicletInitialized=Event<Void>()
/// Signals that a this instance is shutting down. fuzzer即将被关闭 publicletShutdown=Event<ShutdownReason>()
/// Signals that this instance has successfully shut down. fuzzer被成功关闭 /// Clients are expected to terminate the hosting process when handling this event. publicletShutdownComplete=Event<ShutdownReason>()
/// Signals that a log message was dispatched. 一个日志信息被发送 /// The origin field contains the UUID of the fuzzer instance that originally logged the message. publicletLog=Event<(origin: UUID, level: LogLevel, label: String, message: String)>()
/// Signals that a new (mutated) program has been generated. 一个新的(变异后的)程序被生成 publicletProgramGenerated=Event<Program>()
/// Signals that a valid program has been found. 一个合法程序被发现 publicletValidProgramFound=Event<Program>()
// Store samples to disk if requested. iflet path = storagePath { // 把生成的样本保存在磁盘中, 参数--storagePath被设置时 if resume { // 恢复模式:将旧语料库移动到old_corpus,并后续导入 // Move the old corpus to a new directory from which the files will be imported afterwards // before the directory is deleted. ifFileManager.default.fileExists(atPath: path +"/old_corpus") { logger.fatal("Unexpected /old_corpus directory found! Was a previous import aborted? Please check if you need to recover the old corpus manually by moving to to /corpus or deleting it.") } do { tryFileManager.default.moveItem(atPath: path +"/corpus", toPath: path +"/old_corpus") } catch { logger.info("Nothing to resume from: \(path)/corpus does not exist") resume =false } } elseif overwrite { // 覆盖模式:清空存储目录 logger.info("Deleting all files in \(path) due to --overwrite") try?FileManager.default.removeItem(atPath: path) } else { // The corpus directory must be empty. We already checked this above, so just assert here let directory = (try?FileManager.default.contentsOfDirectory(atPath: path +"/corpus")) ?? [] assert(directory.isEmpty) } // 添加存储模块 fuzzer.addModule(Storage(for: fuzzer, storageDir: path, statisticsExportInterval: exportStatistics ?Double(statisticsExportInterval) * Minutes : nil )) }
// Initialize the script runner first so we are able to execute programs. // 初始化脚本执行器,这样就可以执行js脚本了 runner.initialize(with: self)
// Then initialize all components. 初始化所有组件 engine.initialize(with: self) evaluator.initialize(with: self) environment.initialize(with: self) corpus.initialize(with: self) minimizer.initialize(with: self) corpusGenerationEngine.initialize(with: self)
// Finally initialize all modules. 初始化所有模块 for module in modules.values { module.initialize(with: self) }
// Install a watchdog to monitor the utilization of this instance. 安装一个watchdog监控这个实例的使用情况 var lastCheck =Date() timers.scheduleTask(every: 1*Minutes) { // Monitor responsiveness let now =Date() let interval = now.timeIntervalSince(lastCheck) lastCheck = now if interval >180 { self.logger.warning("Fuzzer appears unresponsive (watchdog only triggered after \(Int(interval))s instead of 60s).") } }
// Install a timer to monitor for faulty code generators and program templates. 安装一个计时器来监视错误的代码生成器和程序模板 timers.scheduleTask(every: 5*Minutes) { for generator inself.codeGenerators { if generator.totalSamples >=100&& generator.correctnessRate <0.05 { self.logger.warning("Code generator \(generator.name) might be broken. Correctness rate is only \(generator.correctnessRate *100)% after \(generator.totalSamples) generated samples") } } for template inself.programTemplates { if template.totalSamples >=100&& template.correctnessRate <0.05 { self.logger.warning("Program template \(template.name) might be broken. Correctness rate is only \(template.correctnessRate *100)% after \(template.totalSamples) generated samples") } } }
// Determine our initial state if necessary. assert(state == .uninitialized || state == .corpusImport) if state == .uninitialized { let isChildNode = modules.values.contains(where: { $0isDistributedFuzzingChildNode }) if isChildNode { // We're a child node, so wait until we've received some kind of corpus from our parent node. // We'll change our state when we're synchronized with our parent, see updateStateAfterSynchronizingWithParentNode() below. changeState(to: .waiting) } else { // Start with corpus generation. assert(corpus.isEmpty) changeState(to: .corpusGeneration) } }
// 创建多个从(子)Fuzzer对象 for_in1..<numJobs { let worker = makeFuzzer(with: workerConfig) // 为其子worker创建Fuzzer对象 worker.async { // 子worker异步初始化 // Wait some time between starting workers to reduce the load on the main instance. // If we start the workers right away, they will all very quickly find new coverage // and send lots of (probably redundant) programs to the main instance. // 启动从Fuzzer对象(主进程的是主Fuzzer对象)前随机等待 let minDelay =1*Minutes let maxDelay =10*Minutes let delay =Double.random(in: minDelay...maxDelay) // 随机延迟(1 ~ 10min) Thread.sleep(forTimeInterval: delay)
if [ "$(uname)" == "Linux" ]; then # See https://v8.dev/docs/compile-arm64 for instructions on how to build on Arm64 gn gen out/fuzzbuild --args='is_debug=false dcheck_always_on=true v8_static_library=true v8_enable_verify_heap=true v8_fuzzilli=true sanitizer_coverage_flags="trace-pc-guard" target_cpu="x64"' else echo"Unsupported operating system" fi
# Value for -fsanitize-coverage flag. Setting this causes # use_sanitizer_coverage to be enabled. 设置它会使use_sanitizer_coverage被启用。 # This flag is not used for libFuzzer (use_libfuzzer=true). Instead, we use: # -fsanitize=fuzzer-no-link 这个标志不用于libFuzzer。相反,我们使用:-fsanitize=fuzz-no-link # Default value when unset and use_fuzzing_engine=true: # trace-pc-guard 未设置且use_fuzzing_engine时的默认值:trace-pc-guard # Default value when unset and use_sanitizer_coverage=true: # trace-pc-guard,indirect-calls # 未设置且use_sanitizer_coverage=true时的默认值:trace-pc-guard,indirect-calls sanitizer_coverage_flags = ""
config("coverage_flags") { cflags = [] if (use_sanitizer_coverage) { # Used by sandboxing code to allow coverage dump to be written on the disk. defines = [ "SANITIZER_COVERAGE" ]
if (use_libfuzzer) { ... } else { cflags += [ "-fsanitize-coverage=$sanitizer_coverage_flags", "-mllvm", "-sanitizer-coverage-prune-blocks=1", ] if (current_cpu == "arm") { ... } } ... } if (use_centipede) { ... } }
// The guards are [start, stop). 它的执行区间是[start, stop),也就是stop地址处是不会被初始化的 // This function will be called at least once per DSO and may be called // more than once with the same values of start/stop. // 该函数将在每个DSO(动态库)中至少调用一次,并且可以使用相同的start/stop值多次调用。 __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop);
// This callback is inserted by the compiler as a module constructor // into every DSO. 'start' and 'stop' correspond to the // beginning and end of the section with the guards for the entire // binary (executable or DSO). The callback will be called at least // once per DSO and may be called multiple times with the same parameters. /* 这个回调会被编译器作为一个模块构造函数插入到每一个DSO中 start和stop对应整个二进制文件(可执行文件 or 动态库)中guard段的开始和结束 每一个动态库这个callback至少被调用一次, 并且有可能以相同的参数调用多次 */ extern"C"void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop) { staticuint64_t N; // Counter for the guards. if (start == stop || *start) return; // Initialize only once. 只初始化一次 printf("INIT: %p %p\n", start, stop); for (uint32_t *x = start; x < stop; x++) *x = ++N; // Guards should start from 1. 给[start, stop)中的guard_variable赋值,从1开始。 }
// This callback is inserted by the compiler on every edge in the // control flow (some optimizations apply). // Typically, the compiler will emit the code like this: // if(*guard) // __sanitizer_cov_trace_pc_guard(guard); // But for large functions it will emit a simple call: // __sanitizer_cov_trace_pc_guard(guard); /* 这个回调函数会被编译器插入到控制流的每一个边中 通常来说编译器会生成如下代码 if(*guard) __sanitizer_cov_trace_pc_guard(guard); 但是对于某些大函数会生成一个简单的调用, 所以callbak内部需要进行二次检查 __sanitizer_cov_trace_pc_guard(guard); */ extern"C"void __sanitizer_cov_trace_pc_guard(uint32_t *guard) { if (!*guard) return; // Duplicate the guard check. // If you set *guard to 0 this code will not be called again for this edge. // Now you can get the PC and do whatever you want: // store it somewhere or symbolize it and print right away. // The values of `*guard` are as you set them in // __sanitizer_cov_trace_pc_guard_init and so you can make them consecutive // and use them to dereference an array or a bit vector. /* 如果设置*guard为0, 那么对于这个边该代码就不会被调用了。 现在你可以得到PC并做任何你想做的事情:将它存储在某个地方或将其标记并立即打印。 *guard就是之前__sanitizer_cov_trace_pc_guard_init()中设置的值 */ void *PC = __builtin_return_address(0); char PcDescr[1024]; // This function is a part of the sanitizer run-time. // To use it, link with AddressSanitizer or other sanitizer. /* 这是sanitizer run-time函数的一部分, 可以获取pc相关信息 为了使用它需要与AddressSanitizer或者其他sanitizer链接到一起 */ __sanitizer_symbolize_pc(PC, "%p %F %L", PcDescr, sizeof(PcDescr)); printf("guard: %p %x PC %s\n", guard, *guard, PcDescr); }
INIT: 0x71bcd0 0x71bce0 guard: 0x71bcd4 2 PC 0x4ecd5b in main trace-pc-guard-example.cc:2 guard: 0x71bcd8 3 PC 0x4ecd9e in main trace-pc-guard-example.cc:3:7
INIT: 0x71bcd0 0x71bce0 guard: 0x71bcd4 2 PC 0x4ecd5b in main trace-pc-guard-example.cc:3 guard: 0x71bcdc 4 PC 0x4ecdc7 in main trace-pc-guard-example.cc:4:17 guard: 0x71bcd0 1 PC 0x4ecd20 in foo() trace-pc-guard-example.cc:2:14
extern"C" void __sanitizer_cov_8bit_counters_init(char *start, char *end) { // [start,end) is the array of 8-bit counters created for the current DSO. // Capture this array in order to read/modify the counters. // [start,end]是为当前DSO创建的8位计数器数组。捕获该数组以便读取/修改计数器。 }
voidsanitizer_cov_reset_edgeguards(){ uint32_t N = 0; for (uint32_t* x = edges_start; x < edges_stop && N < MAX_EDGES; x++) *x = ++N; }
extern"C"void __sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop) { // We should initialize the shared memory region only once. We can initialize // it multiple times if it's the same region, which is something that appears // to happen on e.g. macOS. If we ever see a different region, we will likely // overwrite the previous one, which is probably not intended and as such we // fail with an error. /* 我们应该只初始化共享内存区域一次。如果它在同一个区域,我们可以对它进行多次初始化,这在macOS上似乎是会发生的。 如果我们看到一个不同的区域,我们可能会覆盖之前的区域,这可能不是我们想要的,因此我们会失败并出现错误。 */ if (shmem) { ... // Already initialized. 已经初始化过了就返回。 return; } // Map the shared memory region // 通过环境变量获取共享内存key constchar* shm_key = getenv("SHM_ID"); if (!shm_key) { //如果没有,则自己映射一片内存自己用 fprintf(stderr, "[COV] no shared memory bitmap available, skipping\n"); shmem = (struct shmem_data*)v8::base::Malloc(SHM_SIZE); } else { // 存在SHM_ID int fd = shm_open(shm_key, O_RDWR, S_IREAD | S_IWRITE); // 获取共享内存的fd if (fd <= -1) { // 错误处理 fprintf(stderr, "[COV] Failed to open shared memory region\n"); _exit(-1); } // 映射到本进程的地址空间中 shmem = (struct shmem_data*)mmap(0, SHM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); if (shmem == MAP_FAILED) { fprintf(stderr, "[COV] Failed to mmap shared memory region\n"); _exit(-1); } }
extern"C"void __sanitizer_cov_trace_pc_guard(uint32_t* guard) { // There's a small race condition here: if this function executes in two // threads for the same edge at the same time, the first thread might disable // the edge (by setting the guard to zero) before the second thread fetches // the guard value (and thus the index). However, our instrumentation ignores // the first edge (see libcoverage.c) and so the race is unproblematic. /* 这里有一个小的竞争条件:如果这个函数在两个线程中同时对同一条边执行,那么在第二个线程获取保护值(从而获取索引)之前, 第一个线程可能会禁用该边(通过将保护设置为零)。然而,我们的检测忽略了第一条边(参见libcoverage.c), 因此竞争是没有问题的。 */ uint32_t index = *guard; // 获取边对应的唯一标识 shmem->edges[index / 8] |= 1 << (index % 8); // 设置shmem->edges中第index个bit为1,表示该边已被执行 *guard = 0; // 再将这条边置为0,因此再次执行时,就不会触发callback了。 }
// This function is ran once per REPRL loop. In case of crash the coverage of // crash will not be stored in shared memory. Therefore, it would be useful, if // we could store these coverage information into shared memory in real time. /* 这个函数在每个REPRL循环中运行一次。在崩溃的情况下,崩溃的覆盖将不会存储在共享内存中。因此,如果我们能够实时地将这些覆盖 率信息存储到共享内存中,这将是非常有用的。 */ voidcov_update_builtins_basic_block_coverage( const std::vector<bool>& cov_map){ if (cov_map.size() != builtins_edge_count) { fprintf(stderr, "[COV] Error: Size of builtins cov map changed.\n"); exit(-1); } for (uint32_t i = 0; i < cov_map.size(); ++i) { if (cov_map[i]) { constuint32_t byteIndex = (i + builtins_start) >> 3; constuint32_t bitIndex = (i + builtins_start) & 7;
extern"C"void __sanitizer_cov_trace_pc_guard(uint32_t* guard) { // There's a small race condition here: if this function executes in two threads for the same // edge at the same time, the first thread might disable the edge (by setting the guard to zero) // before the second thread fetches the guard value (and thus the index). However, our // instrumentation ignores the first edge (see libcoverage.c) and so the race is unproblematic.
SUPPRESS_COVERAGE voidFuzzilli::initializeCoverage(uint32_t* start, uint32_t* stop) { RELEASE_ASSERT_WITH_MESSAGE(!edgesStart && !edgesStop, "Coverage instrumentation is only supported for a single module");
edgesStart = start; edgesStop = stop;
if (constchar* shmKey = getenv("SHM_ID")) { int32_t fd = shm_open(shmKey, O_RDWR, S_IREAD | S_IWRITE); RELEASE_ASSERT_WITH_MESSAGE(fd >= 0, "Failed to open shared memory region: %s", strerror(errno));
publicclassProgramCoverageEvaluator: ComponentBase, ProgramEvaluator { ... publicinit(runner: ScriptRunner) { // In order to keep clean abstractions, any corpus scheduler requiring edge counting // needs to call EnableEdgeTracking(), via downcasting of ProgramEvaluator self.shouldTrackEdgeCounts =false
super.init(name: "Coverage") // 设置实例id let id =ProgramCoverageEvaluator.instances ProgramCoverageEvaluator.instances +=1
context.id =Int32(id) guard libcoverage.cov_initialize(&context) ==0else { fatalError("Could not initialize libcoverage") } #if os(Windows) runner.setEnvironmentVariable("SHM_ID", to: "shm_id_\(GetCurrentProcessId())_\(id)") #else runner.setEnvironmentVariable("SHM_ID", to: "shm_id_\(getpid())_\(id)") #endif
// Initialize the script runner first so we are able to execute programs. // 首先初始化脚本运行器,以便我们能够执行程序 runner.initialize(with: self)
// Then initialize all components. engine.initialize(with: self) evaluator.initialize(with: self) environment.initialize(with: self) corpus.initialize(with: self) minimizer.initialize(with: self) corpusGenerationEngine.initialize(with: self)
// Finally initialize all modules. ... // Install a watchdog to monitor the utilization of this instance. ... // Determine our initial state if necessary. ...
// A unidirectional communication channel for larger amounts of data, up to a maximum size (REPRL_MAX_DATA_SIZE). // 用于更大数据量的单向通信通道,直至最大大小(REPRL_MAX_DATA_SIZE)。 // Implemented as a (RAM-backed) file for which the file descriptor is shared with the child process and which is mapped into our address space. // 实现为一个(RAM支持的)文件,其文件描述符与子进程共享,并映射到我们的地址空间。 structdata_channel { // File descriptor of the underlying file. Directly shared with the child process. // 底层文件的文件描述符。直接与子进程共享。 // 父进程中的文件描述符,会连接到子进程的fd上 int fd; // Memory mapping of the file, always of size REPRL_MAX_DATA_SIZE. // 文件的内存映射,大小始终为REPRL_MAX_DATA_SIZE // 上述文件映射到父进程地址空间的地址 char* mapping; }; // data_channel是一个用于大量数据通讯的单向信道 // 通过内存映射文件实现, fd与子进程共享并映射到REPRL进程的地址空间中
intreprl_execute(struct reprl_context* ctx, constchar* script, uint64_t script_size, uint64_t timeout, uint64_t* execution_time, int fresh_instance) { ... // Reset file position so the child can simply read(2) and write(2) to these fds. // 重置数据信道的fd,以方便子进程使用 lseek(ctx->data_out->fd, 0, SEEK_SET); lseek(ctx->data_in->fd, 0, SEEK_SET); if (ctx->child_stdout) { lseek(ctx->child_stdout->fd, 0, SEEK_SET); } if (ctx->child_stderr) { lseek(ctx->child_stderr->fd, 0, SEEK_SET); }
// Spawn a new instance if necessary. // 如有必要,生成一个新实例。 // 实际就是,如果此时没有子进程的话,那么会创建一个。因为初始化时pid没有做任何修改,此时应该为空。 if (!ctx->pid) { int r = reprl_spawn_child(ctx); if (r != 0) return r; } ... }
staticintreprl_spawn_child(struct reprl_context* ctx) { // This is also a good time to ensure the data channel backing files don't grow too large. // 这也是确保数据通道备份文件不会变得太大的好时机。 ftruncate(ctx->data_in->fd, REPRL_MAX_DATA_SIZE); // 调整data_in通道文件大小 ftruncate(ctx->data_out->fd, REPRL_MAX_DATA_SIZE); // 调整data_out通道文件大小 if (ctx->child_stdout) ftruncate(ctx->child_stdout->fd, REPRL_MAX_DATA_SIZE); if (ctx->child_stderr) ftruncate(ctx->child_stderr->fd, REPRL_MAX_DATA_SIZE); // 初始化pipefd数组为0 int crpipe[2] = { 0, 0 }; // 子进程 -> REPRL(读端在父进程,写端在子进程) int cwpipe[2] = { 0, 0 }; // REPRL -> 子进程(写端在父进程,读端在子进程)
if (pipe(crpipe) != 0) { // 创建父进程读,子进程写的管道 return reprl_error(ctx, "Could not create pipe for REPRL communication: %s", strerror(errno)); } if (pipe(cwpipe) != 0) { // 创建父进程写,子进程读的管道 close(crpipe[0]); close(crpipe[1]); return reprl_error(ctx, "Could not create pipe for REPRL communication: %s", strerror(errno)); }
intreprl_execute(struct reprl_context* ctx, constchar* script, uint64_t script_length, uint64_t timeout, uint64_t* execution_time, int fresh_instance) { ... // Copy the script to the data channel. // 将Script文件写入到共享内存中 memcpy(ctx->data_out->mapping, script, script_size);
// Tell child to execute the script. // 发送控制信息让子进程执行测试程序 if (write(ctx->ctrl_out, "exec", 4) != 4 || // 执行脚本 write(ctx->ctrl_out, &script_size, 8) != 8) { // Script脚本长度的地址写入共享内存 // These can fail if the child unexpectedly terminated between executions. // Check for that here to be able to provide a better error message. int status; if (waitpid(ctx->pid, &status, WNOHANG) == ctx->pid) { // 使用`WNOHANG`进行非阻塞地检查子进程是否已经终止。若终止则返回值为子进程的pid,此处为错误处理,若子进程意外终止,那么进行下面代码执行进行error告知 reprl_child_terminated(ctx); ... } return reprl_error(ctx, "Failed to send command to child process: %s", strerror(errno)); } ... }
// Poll succeeded, so there must be something to read now (either the status or EOF). // poll成功后, 通过控制管道获取子进程的输出的执行状态 int status; ssize_t rv = read(ctx->ctrl_in, &status, 4); if (rv < 0) { ... } elseif (rv != 4) { // 错误处理 ... } // The status must be a positive number, see the status encoding format below. // We also don't allow the child process to indicate a timeout. If we wanted, // we could treat it as an error if the upper bits are set. // 返回子进程输出的执行状态, 之后子进程会重置状态做好下一次执行的准备 status &= 0xffff; return status; }
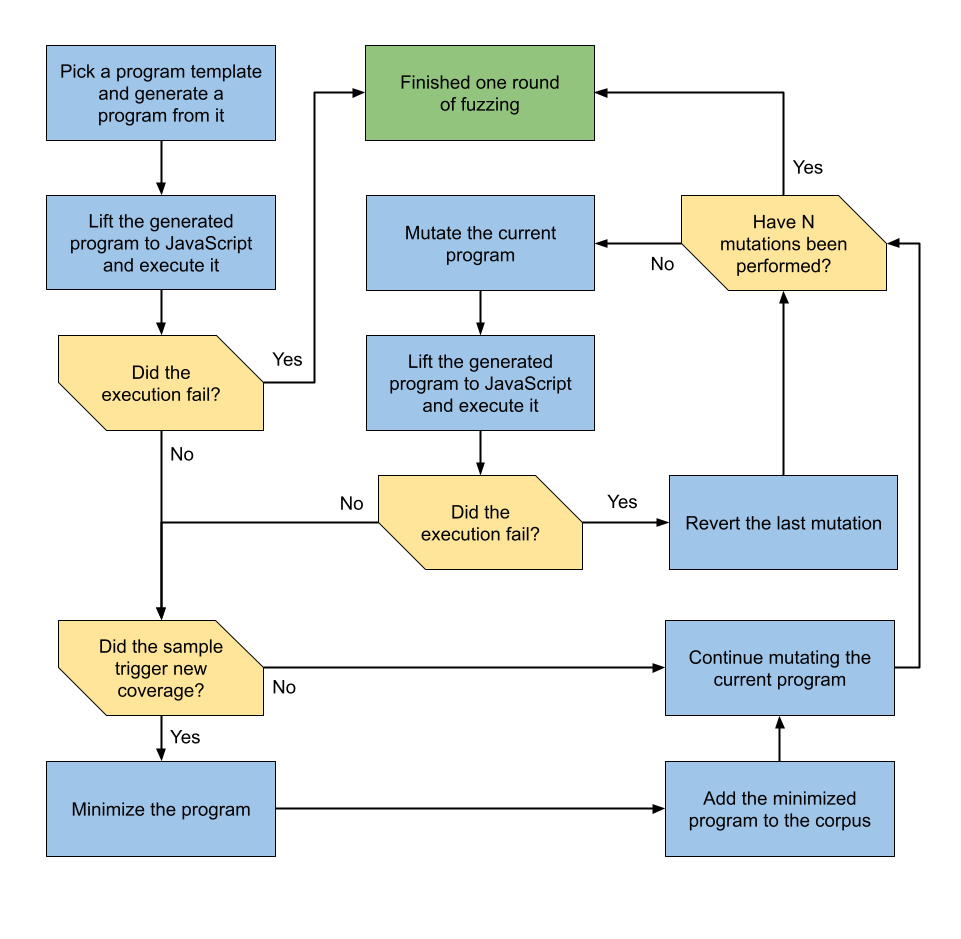
funcmakeFuzzer(withconfiguration: Configuration) -> Fuzzer { ... // Engines to execute programs. let engine: FuzzEngine switch engineName { case"hybrid": engine =HybridEngine(numConsecutiveMutations: consecutiveMutations) case"multi": let mutationEngine =MutationEngine(numConsecutiveMutations: consecutiveMutations) let hybridEngine =HybridEngine(numConsecutiveMutations: consecutiveMutations) let engines =WeightedList<FuzzEngine>([ (mutationEngine, 1), (hybridEngine, 1), ]) // We explicitly want to start with the MutationEngine since we'll probably be finding // lots of new samples during early fuzzing. The samples generated by the HybridEngine tend // to be much larger than those from the MutationEngine and will therefore take much longer // to minimize, making the fuzzer less efficient. // For the same reason, we also use a relatively larger iterationsPerEngine value, so that // the MutationEngine can already find most "low-hanging fruits" in its first run. engine =MultiEngine(engines: engines, initialActive: mutationEngine, iterationsPerEngine: 10000) default: engine =MutationEngine(numConsecutiveMutations: consecutiveMutations) }
// Add a post-processor if the profile defines one. iflet postProcessor = profile.optionalPostProcessor { engine.registerPostProcessor(postProcessor) } ... }
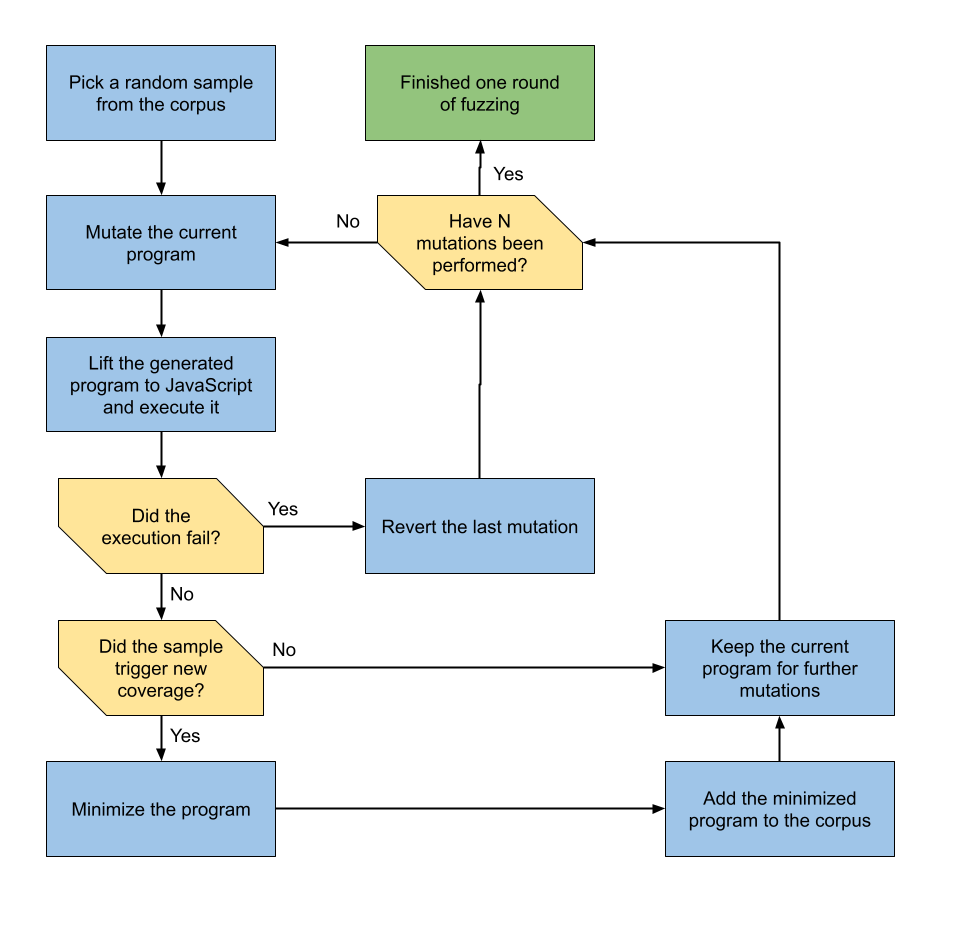
/// The core fuzzer responsible for generating and executing programs. // 负责生成和执行程序的核心fuzzer。 publicclassMutationEngine: FuzzEngine { // The number of consecutive mutations to apply to a sample. // 其实质控制变异时生成测试样例的数量,默认为5,则说明一次FuzzOne会变异生成5个样本去执行,每个样本是某个种子应用10次变异算子。 privatelet numConsecutiveMutations: Int
// 出于统计目的,跟踪插入的explore操作的平均数量。 privatevar averageNumberOfInsertedExploreOps =MovingAverage(n: 1000) publicinit() { super.init("ExplorationMutator", verbose: ExplorationMutator.verbose) if verbose { for op inActionOperation.allCases { actionUsageCounts[op] =0 } } } ... }
接下来是CodeGenMutator():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/// A mutator that generates new code at random positions in a program. // 在程序中的随机位置生成新代码的mutator publicclassCodeGenMutator: BaseInstructionMutator { // DeadCodeAnalyzer是确定当前指令之后的代码是否为死代码(永远不会执行的部分,如return后面的代码)。 privatevar deadCodeAnalyzer =DeadCodeAnalyzer() // VariableAnalyzer是在程序构造期间跟踪当前可见的变量(确保生成的代码能正确引用已有变量)。 privatevar variableAnalyzer =VariableAnalyzer() privatelet minVisibleVariables =3// 最小可见变量数量为3,即最少3个可见变量才开始生成新代码
// 在MutatorSettings.swift中一些全局变量定义如下 // 单次测试用例变异时,最多同时应用7种不同的基础变异(变异算子)操作 let defaultMaxSimultaneousMutations =7 // 单次测试用例变异时,最多插入3次全新生成的代码块,也就是最多执行3次CodeGenMutator let defaultMaxSimultaneousCodeGenerations =3 // 每次调用CodeGenMutator时,生成指令的数量 let defaultCodeGenerationAmount =5// This must be at least ProgramBuilder.minBudgetForRecursiveCodeGeneration
/// A large bit of the logic of this mutator is located in the lifter code that implements Probe operations /// in the target language. For JavaScript, that logic can be found in JavaScriptProbeLifting.swift. // 这个mutator的大部分逻辑位于用目标语言实现Probe的lifter代码中。对于JavaScript,该逻辑可以在JavaScriptProbeLifting.swift中找到。 publicclassProbingMutator: RuntimeAssistedMutator { ... publicinit() { super.init("ProbingMutator", verbose: ProbingMutator.verbose) } ... }
publicclassInputMutator: BaseInstructionMutator { ... publicinit(typeAwareness: TypeAwareness) { // 初始化参数 self.typeAwareness = typeAwareness self.logger =Logger(withLabel: "InputMutator \(String(describing: typeAwareness))") var maxSimultaneousMutations = defaultMaxSimultaneousMutations // A type aware instance can be more aggressive. Based on simple experiments and // the mutator correctness rates, it can very roughly be twice as aggressive. switchself.typeAwareness { case .aware: // 当typeAwareness为.aware时,将单个测试用例变异次数扩大到原先两倍:7*2 maxSimultaneousMutations *=2 default: break } super.init(name: "InputMutator (\(String(describing: self.typeAwareness)))", maxSimultaneousMutations: maxSimultaneousMutations) } ... }