CVE-2020-9802 JSC编译优化漏洞复现
如果不是实力有限,我真想把它拿下哇。/(ToT)/~~
CVE-2020-9802 复现
翻译自Project Zero的博客:JITSpoitation
JITSpoitation I : 一个JIT漏洞
被利用的漏洞CVE-2020-9802已经在IOS 13.5中修复,而两个缓解绕过漏洞CVE-2020-9870和CVE-2020-9910已经在IOS 13.6中修复。
JIT编译器介绍
1 | |
由于JIT编译成本高昂,因此它只会针对于重复执行的代码而编译。因此,函数foo将在解释器(或者 “基线”JIT)内执行一段时间。在此期间,将收集值配置文件,对于foo来说,它看起来如下所示:
- o: JSObject with a property .x at offset 16
- x: Int32
- y: Int32
解释说明:JavaScript对象的内存布局是由JavaScript引擎管理的,具体的实现细节可能因引擎而异,但通常会有一些共同的设计原则。偏移量0-7存储的是隐藏类指针,8-15可能是对齐或元数据等。那么从16开始的8个字节就是属性x的值。
之后,当优化JIT编译器最终启动时,它首先将JavaScript源代码(或更可能是解释器字节码)翻译成JIT编译器自己的中间代码表示。在DFG(JavaScriptCore的优化JIT编译器)中,此操作由DFGByteCodeParser完成。
那么,经过DFG后的foo函数中间代码表示最初看起来像这样:
1 | |
这里,GetById和ValueAdd是相当通用(高级)的操作,能够处理不同的输入类型(例如,ValueAdd也能够用来连接字符串)。
接下来,JIT编译器检查值配置文件,并根据这些配置文件推测将来会使用类似的输入类型。在这里,它会推测 o 始终是某种JSObject,而x和y则是Int32。但是,由于无法保证推测始终正确,因此编译器**必须保护推测**,通常使用廉价的运行时类型检查:
1 | |
还请注意,GetById和ValueAdd已专门用于更高效(且不太通用)的GetByOffset和ArithAdd操作。在DFG中,这种推测性优化发生在多个地方。此时,IR代码基本上已输入,因此推测保护允许类型推断。接下来,执行大量代码优化,例如循环不变代码移动或常量折叠。DFG所做的优化概述可从DFGPlan中提取。
最后,现已优化的IR被降级为机器码。在DFG中,此操作由DFGSpeculativeJIT直接完成,而在FTL模式下,DFG IR首先被降级为另一个IR B3,该IR经过进一步优化后再降级为机器代码。
公共子表达式消除(CSE)
这个优化背后的想法是检测重复的计算(或表达式)并将它们合并为单个计算。例如,请考虑以下JavaScript代码:
1 | |
进一步假设a和b是已知原始值(例如数字),则JavaScript JIT编译器可以将代码转换为以下内容:
1 | |
这样做,可以节省一次ArithMul操作。这种优化称为公共子表达式消除(CSE)。
现在,改用以下JavaScript代码:
1 | |
而这种情况下,编译器无法消除CSE期间的第二个属性加载操作,因为中间的函数调用可能会改变.a属性的值。
在JSC中,某个操作是否可以受CSE约束(以及在什么情况下)的建模是在DFGClobberize中完成的。对于ArithMul,DFGClobberize指出:
1 | |
此处PureValue的def()表示计算不依赖于任何上下文,因此当给定相同的输入时,它将始终产生相同的结果。但是,请注意,PureValue由操作ArithMode参数化,该参数指定操作是否应处理(例如,通过转交给解释器)整数溢出。在这种情况下,参数化可以防止两个具有不同整数溢出处理方式的ArithMul操作相互替换。处理溢出的操作通常也称为“已检查”操作,“未检查”操作是不检测或不处理溢出的操作。
相比之下,对于GetByOffset(可用于属性加载),DFGClobberize包含:
1 | |
这实质上表明此操作生成的值取决于NamedProperty“抽象堆“。因此,只有在两次GetByOffset操作之间没有对NamedProperties抽象堆(即包含属性值的内存位置)进行写入的情况下,消除第二次GetByOffset才是合理的。
The BUG
DFGClobberize 没有考虑ArithNegate操作的ArithMode:
1 | |
这可能导致CSE用未检查的ArithNegate替代已检查的ArithNegate。对于ArithNegate(32位整数的取反),整数溢出仅在一种特定情况下发生:当对INT_MIN: -2147483648 取反时。这是因为2147483648不能表示32位有符号整数,因此-INT_MIN会导致整数溢出,最后的值依然为INT_MIN,即对INT_MIN取反依然得到INT_MIN。
这个错误是通过研究
DFGClobberize中的CSE def发现的,思考为什么某些PureValues(以及哪些)需要用ArithMode进行参数化,然后搜索缺少该参数化的情况。
修复这个漏洞的方法非常简单:
1 | |
现在教会CSE考虑ArithNegate操作的arithMode。因此,两个具有不同模式的ArithNegate操作不能再相互替代。
除了ArithNegate之外,DFGClobberize还错过了ArithAbs操作的ArithMode。
请注意,这种类型的错误可能很难通过模糊测试检测到,因为:
- fuzzer需要在相同的输入上创建两个
ArithNegate操作,但使用不同的ArithMode - fuzzer需要触发
ArithMode差异有影响的情况,在本例中,这意味着需要对INT_MIN取反。除非引擎有自定义的”sanitizers”(清理器)来尽早检测此类问题,并且除非进行差分模糊测试,否则fuzzer还需要以某种方式将这种情况转化为内存安全违规或断言失败。正如下一节所示,这一步可能是最困难的,并且极不可能偶然发生的。
实现越界访问
下面的JavaScript函数通过此漏洞实现了对JSArray的任意索引(在本例中为7)的越界访问:
1 | |
下面逐步解释如何构建此POC。本节末尾附上该函数的注释版本。
首先,ArithNegate仅用于对整数求反(更通用的ValueNegate操作可以对所有JavaScript值求反),但**在_JavaScript规范_中,数字通常是浮点值。**因此,有必要“提示”编译器输入值始终是整数。这很容易实现,只需首先执行按位运算即可,这将始终产生32位有符号整数值:
1 | |
在JavaScript中,数字默认是64位双精度浮点数(即IEEE754标准的
double类型)。它的整数精度有53位。为什么经过上述运算后它会变成一个32位有符号整数呢?因为JavaScript中的位运算符(如
|、&、^、~等)在设计上是针对32位有符号整数的。这意味着:
- 在执行位运算之前,JavaScript会先将操作数转换为32位有符号整数。
- 位运算的结果也是32位有符号整数
- 当执行
n | 0时,JavaScript会先将n转换为32位有符号整数,然后再与0进行按位或运算。由于0的所有位都是0,按位或运算不会改变n的值,但它的副作用是强制将n转换为32位有符号整数。
有了这些,现在就可以构造一个未经检查的ArithNegate操作(之后可以通过公共子表达式消除(CSE)将其替换成一个已检查的操作):
1 | |
这里,再DFGFixupPhase期间,n的取反将转换为未检查的ArithNeg运算。编译器可以省略溢出检查,因为取反值的唯一用途是按位或,并且对于溢出值和“正确”值的行为相同:
1 | |
接下来,需要构造一个以n作为输入的已检查ArithNegate操作。获得ArithNegate的一个有趣方法是(原因稍后会变得清晰)是让编译器将ArithAbs操作强度降低为ArithNegate操作。只有当编译器可以证明n为负数时才会发生这种情况,这很容易实现,因为DFG的IntegerRangeOptimization过程是路径敏感的:
1 | |
在这里,在字节码解析期间,对Math.abs的调用将首先被降低为ArithAbs操作,因为编译器能够证明该调用将始终导致mathAbs函数的执行,因此将其替换为ArithAbs操作,该操作具有相同的运行时语义,但不需要在运行时进行函数调用。编译器本质上是通过这种方式内联Math.abs。稍后,IntegerRangeOptimization会将ArithAbs转换为经过检查的ArithNegate(必须检查ArithNegate,因为不能排除n的INT_MIN)。因此,if语句中的两个语句本质上(在伪DFG IR中)变为:
1 | |
由于漏洞的存在,CSE稍后会变成
1 | |
此时,如果使用INT_MIN作为n来调用编译错误的函数,则会导致i也为INT_MIN,尽管它实际上应该是一个正数。
这本身是一个正确性问题,还不是安全问题。将此错误转变为安全问题的一种(也可能是唯一一种)方法是滥用安全研究人员中已经流行的JIT优化:边界检查消除(bounds-check elimination)。
回到IntegerRangeOptimization过程,i的值已被标记为正数。但是,要消除边界检查,还必须知道该值小于被索引数组的长度。这很容易实现:
1 | |
现在触发错误时,i将为INT_MIN,因此将通过比较并执行数组访问。但是,边界检查将被删除,因为IntegerRangeOptimization错误地(虽然从技术上讲不是它的错)确定i始终在边界内。
在触发该错误之前,必须对JavaScript代码进行JIT编译。这通常只需通过多次执行代码即可实现。但是,如果推测访问在范围内,则对arr的索引访问将仅被降低(通过SSALoweringPhase)到CheckInBounds和未进行边界检查的GetByVal。如果在基线JIT中解释或执行期间经常观察到访问越界,则情况并非如此。因此,在“训练”函数期间,有必要使用合理的边界索引:
1 | |
在JSC中运行此代码将会崩溃:
代码我做了一点点改进,因为我发现不加print的话,就会失效。我认为很有可能不加print的话,编译器认为没有访问内存,因此就不会尝试去访问,所以就不会出现Crash。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22function hax(arr, n) {
n = n|0;
if (n < 0) {
let v = (-n)|0;
let i = Math.abs(n);
if (i < arr.length) {
print(arr[i]);
}
}
}
var arr = [13.37, 2.2, 3.3]
const ITERATIONS = 0xc0000;
for(let i = 1; i <= ITERATIONS; i++){
let n = -2;
if(i == ITERATIONS){
n = -2147483648; // INT_MIN
}
hax(arr, n);
}最后执行即可
lldb ./jsc ./test.js然后run即可。出现crash如下所示:

1 | |
然而,不方便的是,越界索引(在rcx中)将始终是INT_MIN,因此访问数组后面的 0x80000000 * 8 = 16GB。虽然可能可以利用,但它并不是最好的利用原语。
实现任意索引的OOB访问(具有任意索引的越界访问)的最后一个技巧是从i中减去一个常数,这将使INT_MIN变成任意正数。由于DFG编译器认为i始终为正数,因此减法将不受检查,因此溢出将不会被注意到。
但是,由于减法会使有关下限的整数范围信息无效,因此之后需要进行额外的if i > 0检查,以再次触发边界检查消除。此外,由于减法会将训练期间使用的整数变成越界索引,因此只有在输入值为负数时才会有条件地执行。幸运的是,DFG编译器还不够聪明,无法确定该条件永远不应为真,在这种情况下它可以完全优化减法。
综上所述,下面再次展示了从开始时的函数,但这次带有注释。当被JIT编译并被赋予INT_MIN作为n时,它会导致一个受控值(0x0000133700001337)的越界写入,直接写入内存中紧随arr之后的JSArray的长度字段。请注意,这一步的成功取决于正确的堆布局。然而,由于这个漏洞足够强大,可以用于受控的越界读取,因此可以在触发内存损坏之前确保正确的堆布局存在。
1 | |
Addrof/Fakeobj
Addrof和fakeobj是JS引擎漏洞利用中常见的两种原语,通常用于实现地址泄露和伪造对象。
addrof是一种用于泄露 JavaScript 对象内存地址的原语。原理
- JavaScript 引擎通常会将对象的地址存储在内存中,但这些地址对 JavaScript 代码是不可见的。
- 通过某些漏洞(如类型混淆、越界访问等),攻击者可以绕过引擎的保护机制,读取对象的内存地址。
fakeobj是一种用于伪造 JavaScript 对象的原语。原理
- JavaScript 引擎通过内存中的数据结构来表示对象(如隐藏类、属性存储区等)。
- 通过某些漏洞,攻击者可以构造一个伪造的对象,并将其传递给引擎,使引擎将其视为合法的对象。
至此,可以构建两个低级别的漏洞利用原语addrof和fakeobj。原语addrof(obj)返回给定JavaScript对象在内存中的地址(作为双精度浮点数):
1 | |
fakeobj(addr)原语返回一个包含给定地址作为有效负载的JSValue:
1 | |
这些原语非常有用,因为它们基本上可以实现两件事:打破堆 ASLR,以便将受控数据放置在已知地址,并提供一种构造和“注入”假对象到引擎的方法。但有关利用的更多内容请参见第 II 节。

这两个原语可以用两个具有不同存储类型的JSArray来构造:通过重叠一个存储(unboxed/raw)双精度浮点数的JSArray与一个存储JSValue的JSArray(boxed/tagged的值,例如可以是JSObject的指针)
unboxed/raw : 这种数组直接将双精度浮点数存储在数组的连续内存空间中,没有额外的元数据或标记。这种存储效率很高,但只能存储双精度浮点数。
JSValues(boxed/tagged):boxing指将原始类型(例如数字、布尔值)包装成对象。tagging指的是在JSValue中使用一些位来表示值的类型。例如,可以使用一个位来区分整数和指针。
然后允许通过float_arr以双精度形式读取/写入obj_arr中的指针值:
1 | |
请注意noCoW变量的使用有些不直观。它用于阻止JSC将数组分配为写时复制(copy-on-write)数组,否则会导致错误的堆布局。
copy-on-write(CoW):是一种优化技术,用于延迟复制资源(例如内存页),直到其中一个 副本被修改时才真正进行复制。在多个进程或对象共享同一资源时,CoW可以节省内存和提高性能。
结论
我希望这已经是一个有趣的“非标准”JIT编译器漏洞演练。请记住,有许多(JIT)漏洞更容易被利用。另一方面,利用(到目前为止)并不简单,这也允许在此过程中触及许多JSC和JIT编译器内部。
翻译自(+了些个人理解):JITSpoitation I
JITSpoitation II : Getting Read/Write
这是关于Safari渲染器中由JIT漏洞引发的漏洞利用系列的第二部分。在第一部分中,讨论了DFG JIT在公共子表达式消除实现中的一个漏洞。第二部分从众所周知的addrof和fakeobj原语开始,展示了如何从中构建稳定、任意的内存读/写。此,将讨论并绕过 StructureID 随机化缓解措施和 Gigacage。
回顾
早在2016年,攻击者会使用 addrof 和 fakeobj 原语来伪造一个 ArrayBuffer,从而立即获得可靠的任意内存读/写原语。 但在 2018 年年中,WebKit 引入了“Gigacage”,试图阻止以这种方式滥用 ArrayBuffer。 Gigacage 的工作原理是将 ArrayBuffer 的后备存储移动到一个 4GB 的堆区域中,并使用 32 位相对偏移量而不是绝对指针来引用它们,从而(或多或少)使得使用 ArrayBuffer 访问 cage 之外的数据成为不可能。
然而,虽然 ArrayBuffer 的存储被 caged (关住)了,但包含数组元素的 JSArray Butterflies 却没有。 由于它们可以存储原始的浮点数值,攻击者可以通过伪造这样一个“未装箱的双精度” JSArray,立即获得相当强大的任意读/写能力。 过去,各种公开的漏洞利用程序就是通过这种方式绕过 Gigacage 的。 (不幸的是)WebKit 引入了一种旨在阻止攻击者完全伪造 JavaScript 对象的缓解措施:StructureID 随机化。 因此,必须首先绕过这种缓解措施。
使用
addrof原语获得一个合法的ArrayBuffer的地址。使用fakeobj原语修改一个对象的内存布局,使其对象头与ArrayBuffer的对象头一致。通过漏洞修改伪造的ArrayBuffer的backing store指针,使其指向任意内存地址。在这里,以本人的基础,后续的缓解机制都难以理解。我认为应该先复现第一批漏洞,也就是WebKit引入第一个缓解机制前(2016年-2018年的JSC漏洞),这样能够清晰这里面的漏洞产生原理,漏洞挖掘机制。后续的补丁,以及缓解机制都是一层一层增加的。那么,这种情况下,也应该一层一层进行剥离。否则难以真正理解这些缓解机制为何这么绕过,难以真正理解漏洞成因。因此就不去翻译第三篇博客了。当后续复现完前面的漏洞后,再来此进行填补。——2025.3.12
因此,这篇文章将:
- 解释 JSObject 的内存布局
- 绕过 StructureID 随机化来伪造 JSArray 对象
- 使用伪造的 JSArray 对象来设置一个(有限的)内存读/写原语
- 突破 Gigacage 以获得快速、可靠且真正任意的读/写原语
伪造对象
为了伪造对象,必须了解它们的内存布局。在JSC中,一个普通的JSObject由一个JSCell头部、紧随其后的“Butterfly”以及可能存在的内联属性组成。 Butterfly 是一个存储缓冲区,包含对象的属性和元素以及元素的数量(长度):

像 JSArrayBuffer 这样的对象会在 JSObject 布局中添加更多成员。
每个 JSCell 头部通过 StructureID 字段引用一个 Structure,StructureID 是运行时环境的 StructureIDTable 中的一个索引。 Structure 本质上是一个类型信息的 blob,包含诸如此类的信息:
- 对象的基类型,例如 JSObject、JSArray、JSString、JSUint8Array,…
- 对象的属性以及它们相对于对象的存储位置
- 对象的大小(以字节为单位)
- 索引类型,指示存储在 Butterfly 中的数组元素的类型,例如 JSValue、Int32 或未装箱的双精度浮点数,以及它们是存储为连续的数组还是以其他方式存储,例如在映射中。
- 等等。
最后,剩余的 JSCell 头部位包含诸如 GC 标记状态之类的内容,并“缓存”一些常用的类型信息位,例如索引类型。 下图总结了 64 位架构上普通 JSObject 的内存布局。

对对象执行的大多数操作都需要查看对象的 Structure,以确定如何处理该对象。 因此,在创建伪造的 JSObject 时,必须知道要伪造的对象类型的 StructureID。 以前,可以使用 StructureID 喷射 (Spraying) 来预测 StructureID。 这种方法通过简单地分配许多所需类型的对象(例如,Uint8Array)并向每个对象添加不同的属性来实现,从而导致为该对象分配唯一的 Structure,进而分配唯一的 StructureID。 这样做一千次也许几乎可以保证 1000 是 Uint8Array 对象的有效 StructureID。 这就是 StructureID 随机化(2019 年初推出的一种新的漏洞利用缓解措施)发挥作用的地方。
StructureID 随机化
这种漏洞利用缓解措施背后的想法非常简单:由于攻击者(据推测)需要知道有效的 StructureID 才能伪造对象,因此随机化 ID 将会阻碍这一点。 确切的随机化方案已在源代码中得到充分记录。 这样,现在就不可能预测 StructureID 了。
绕过 StructureID 随机化有不同的方法,包括:
- 泄漏有效的 StructureID,例如通过 OOB 读取
- 滥用不检查 StructureID 的代码,如已证明的那样
- 构建“StructureID oracle”来暴力破解有效的 StructureID
“StructureID oracle”的一个可能的想法是再次滥用 JIT。 编译器发出的一种非常常见的代码模式是 StructureCheck,用于保护类型推测。 在伪 C 代码中,它们大致如下所示:
1 | |
这可能允许构建一个“StructureID oracle”:如果可以构造一个 JIT 编译的函数,该函数检查 StructureID,但不使用该 StructureID,那么攻击者应该能够通过观察是否发生了 bailout 来确定 StructureID 是否有效。 反过来,可以通过计时,或者通过“利用” JIT 中的正确性问题来实现这一点,该问题导致相同的代码在 JIT 中运行与在解释器中运行产生不同的结果(在 bailout 后执行将继续)。 像这样的 oracle 将允许攻击者通过预测递增的索引位并暴力破解 7 个熵位来暴力破解有效的结构 ID。
然而,泄漏有效的 StructureID 和滥用不检查 StructureID 的代码似乎是更容易的选择。 特别是,在解释器中加载 JSArray 元素时,有一条代码路径永远不会访问 StructureID:
1 | |
在这里,getIndexQuickly 直接从 Butterfly 加载元素,而 canGetIndexQuickly 只查看 JSCell 头部中的索引类型(其值为已知的常量)和 Butterfly 中的长度:
1 | |
现在,这允许伪造一个看起来有点像 JSArray 的东西,将其后备存储指针指向另一个有效的 JSArray,然后读取该 JSArray 的 JSCell 头部,其中包含有效的 StructureID:
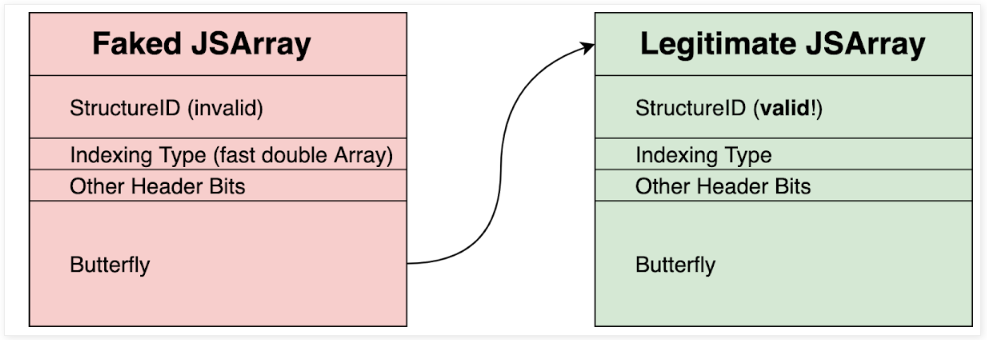
至此,StructureID 随机化已被完全绕过。
以下 JavaScript 代码实现了这一点,像往常一样通过(滥)用“容器”对象的内联属性来伪造对象:
1 | |
此代码在访问 0x414141414141 附近的内存时会崩溃。 因此,攻击者现在获得了任意内存读取/写入原语,尽管是稍微有限制的一种:
- 只能读取和写入有效的双精度浮点数值
- 由于 Butterfly 也存储了自己的长度,因此有必要定位 Butterfly 指针,使其长度看起来足够大,以访问所需的数据
关于漏洞利用稳定性的说明
运行当前的漏洞利用程序会产生内存读取/写入,但很可能在垃圾收集器下次运行时扫描所有可访问的堆对象后不久崩溃。
实现漏洞利用稳定性的通用方法是使所有堆对象保持在正常运行状态(当 GC 扫描对象并访问所有传出指针时不会导致崩溃的状态),或者,如果这不可能,则在损坏后尽快修复它们。 在此漏洞利用的情况下,fake_arr 最初是“GC 不安全的”,因为它包含无效的 StructureID。 当其 JSCell 稍后被替换为有效的 JSCell(container.jscell_header = jscell_header;)时,伪造的对象变得“GC 安全”,因为它对 GC 来说看起来像一个有效的 JSArray。
但是,某些边缘情况也可能导致损坏的数据存储在引擎的其他地方。 例如,先前 JavaScript 代码段中的数组加载(jscell_header = fake_arr[0];)将由 get_by_val 字节码操作执行。 此操作还会保留上次看到的结构 ID 的缓存,该缓存用于构建 JIT 编译器依赖的值配置文件。 这是有问题的,因为伪造的 JSArray 的结构 ID 无效,因此会导致崩溃,例如当 GC 扫描字节码缓存时。 然而,幸运的是,修复起来相当容易:执行相同的 get_by_val 操作两次,第二次使用有效的 JSArray,其 StructureID 将随后被缓存:
1 | |
这样做可以使当前的漏洞利用程序在 GC 执行期间保持稳定。
突破 (Giga-)Cage
注意:这部分主要是一个有趣的 JIT 漏洞利用练习,对于已经构建了足够强大的读/写原语的漏洞利用来说,并不是严格必需的。 然而,它可以使漏洞利用程序更快,因为从中获得的读/写性能更高,而且是真正任意的。
与本文开头描述的有些相反,JSC 中的 ArrayBuffer 实际上受到两种不同机制的保护:
- Gigacage:一个多 GB 的虚拟内存区域,其中分配了 TypedArray(以及一些其他对象)的后备存储缓冲区。 后备存储指针现在基本上是从 cage 基址开始的 32 位偏移量,而不是 64 位指针,从而防止访问 cage 之外的内容。
- PACCage:除了 Gigacage 之外,TypedArray 后备存储指针现在还通过指针身份验证代码 (PAC) 进行保护(如果可用),防止在堆上篡改它们,因为攻击者通常无法伪造有效的 PAC 签名。
用于组合 Gigacage 和 PACCage 的确切方案记录在例如 commit 205711404e 中。 这样,TypedArray 本质上受到了双重保护,因此评估是否仍然可以滥用它们进行读/写似乎是一项有价值的尝试。 寻找潜在问题的一个地方再次是 JIT,因为它具有用于提高性能的 TypedArray 的特殊处理。
DFG中的TypedArrays
考虑以下JavaScript代码:
1 | |
在DFG中进行优化时,opt函数将大致转换为以下DFG IR(省略了许多细节):
1 | |
有趣的是,对 TypedArray 的访问已被拆分为三个不同的操作:对索引的边界检查、一个 GetIndexedPropertyStorage 操作(负责获取和取消 caged 的后备存储指针)以及一个 GetByVal 操作(它本质上会转换为单个内存加载指令)。 假设 r0 包含指向 TypedArray a 的指针,则上述 IR(中间表示)将导致大致如下的机器代码:
1 | |
然而,如果没有可用的通用寄存器供 GetIndexedPropertyStorage 存储原始指针,会发生什么情况? 在这种情况下,指针将不得不溢出到堆栈。 这可能允许具有损坏堆栈内存能力的攻击者通过在由 GetByVal 或 SetByVal 操作访问内存之前修改堆栈上溢出的指针来突破两个 cage。
本博客文章的其余部分将描述如何在实践中实现这种攻击。 为此,必须解决三个主要挑战:
- 泄漏一个堆栈指针,以便找到并损坏堆栈上溢出的值
- 分离
GetIndexedPropertyStorage和GetByVal操作,以便修改溢出指针的代码可以在两者之间执行 - 强制将取消 caged 的存储指针溢出到堆栈
寻找堆栈
事实证明,在给定任意堆读取/写入的情况下,在 JSC 中查找指向堆栈的指针相当容易:VM 对象的 topCallFrame 成员实际上是指向堆栈的指针,因为 JSC 解释器使用本机堆栈,因此顶部的 JS 调用帧也基本上是主线程堆栈的顶部。 因此,找到堆栈就像从全局对象到 VM 实例遵循指针链一样容易:
1 | |
分离TypeArray访问操作
对于上面简单地在索引处访问类型化数组一次(即 a[0])的 opt 函数,GetIndexedPropertyStorage 操作将直接跟随 GetByVal 操作,因此即使它溢出到堆栈上,也无法破坏 uncaged 的指针。 然而,以下代码已经设法分离了这两个操作:
1 | |
此代码最初将生成以下DFG IR:
1 | |
然后,在优化管道中稍后,两个 GetIndexedPropertyStorage 操作将被 CSE(公共子表达式消除)为一个,从而将第二个 GetByVal 与 GetIndexedPropertyStorage 操作分离:
1 | |
但是,只有当溢出代码不修改全局状态时,才会发生这种情况,因为这可能会分离 TypedArray 的缓冲区,从而使其后备存储指针无效。 在这种情况下,编译器将被迫为第二个 GetByVal 重新加载后备存储指针。 因此,不可能运行完全任意的代码来强制溢出,但如下所示,这不是问题。 还值得注意的是,这里必须使用两个不同的索引,否则 GetByVal 也可以进行 CSE。
溢出寄存器
完成前两个步骤后,剩下的问题是如何强制溢出由 GetIndexedPropertyStorage 生成的 uncaged 指针。 一种在仍然允许 CSE 发生的同时强制溢出的方法是执行一些简单的数学计算,这些计算需要保持大量的临时值。 以下代码以一种时尚的方式完成了这一点:
1 | |
计算的序列在某种程度上类似于斐波那契数列,但需要保持中间结果的活跃,因为它们稍后会在序列中再次用到。 不幸的是,这种方法有些脆弱,因为引擎各个部分(尤其是寄存器分配器)的不相关更改很容易破坏堆栈溢出。
还有另一种更简单的方法(尽管可能性能稍差且肯定不那么赏心悦目),几乎可以保证原始存储指针将被溢出到堆栈:只需访问与通用寄存器一样多的 TypedArray,而不是只有一个。 在这种情况下,由于没有足够的寄存器来容纳所有原始后备存储指针,因此其中一些必须溢出到堆栈,在那里它们可以被找到并替换。 这种方法的原始版本如下所示:
1 | |
随着主要挑战的克服,现在可以实现攻击,并且感兴趣的读者可以在本博客文章的末尾找到概念验证。 总而言之,该技术最初实现起来非常繁琐,还有一些需要注意的陷阱 - 详见 PoC。 但是,一旦实现,生成的代码就非常可靠且速度非常快,几乎可以立即在 macOS 和 iOS 以及不同的 WebKit 版本上实现真正任意的内存读取/写入原语,而无需额外更改。
结论
这篇文章展示了攻击者如何(仍然)利用众所周知的 addrof 和 fakeobj 原语来获得 WebKit 中的任意内存读取/写入。 为此,必须绕过 StructureID 缓解措施,而绕过 Gigacage 主要是可选的(但很有趣)。 从编写此漏洞利用程序到目前为止,我个人得出以下结论:
- StructureID 随机化目前似乎非常薄弱。 由于大量的类型信息存储在 JSCell 位中,因此攻击者可以预测这些信息,因此似乎可以找到并滥用许多其他不需要有效 StructureID 的操作。 此外,可以转化为堆越界读取的错误很可能用于泄漏有效的 StructureID。
- 就目前而言,Gigacage 作为安全缓解措施的目的对我来说并不完全清楚,因为可以从不受 Gigacage 约束的普通 JSArray 构建(几乎)任意的读取/写入原语。 在这一点上,正如这里所演示的,Gigacage 也可以被完全绕过,即使这在实践中可能不是必需的。
- 我认为值得调查删除未装箱的双精度 JSArray 以及正确 caging 其余 JSArray 类型(它们都存储“已装箱”的 JSValue)的影响(包括对安全性和性能的影响)。 这可能会使 StructureID 随机化和 Gigacage 都变得更强大。 在此漏洞利用的情况下,这将首先阻止
addrof和fakeobj原语的构造(因为双精度 <-> JSValue 类型混淆将不再能够构造),以及通过 JSArray 进行的有限读取/写入,并且还将阻止通过 OOB 访问到 JSArray 中泄漏有效的 StructureID(可以说是 OOB 访问最常见的场景)。
本系列的最后一部分将展示如何在存在 PAC 和 APRR 等更多缓解措施的情况下,从读取/写入中获得 PC 控制。
翻译自(+了些个人理解):JITSpoitation II
JITSploitation III: Subverting Control Flow
TODO….