二进制安全-基础
不记得了,但是这是我初接触Pwn时记的笔记。随便看看得了,别骂我。.T_T.
Pwn
基本栈
栈(Stack)
- 后进先出(Last in First Out)
- 操作主要是压栈(push)与出栈(pop)两种操作
- 高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用这一数据结构。
每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。
需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。
C语言函数调用栈
1 寄存器分配
程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接call指令)处继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对应一个调用栈结构(call stack)。编译器使用堆栈传递函数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量。
不同处理器和编译器的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样的。
Intel 32位体系结构(简称IA32)处理器包含8个四字节寄存器,如下图所示:

最初的8086中寄存器是16位,每个都有特殊用途,寄存器名称反映其不同用途。由于IA32平台采用平面寻址模式,对特殊寄存器的需求大大降低,但由于历史原因,这些寄存器名称被保留下来。在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。某些指令可能以固定的寄存器作为源寄存器或目的寄存器(一些特殊的算术操作指令imull/mull/cltd/idivl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax(lower32-bit)中)。为避免兼容性问题,ABI规范对这组通用寄存器的具体作用加以定义。如上图。
对于寄存器%eax,%ebx,%ecx,%edx,各自可作为两个独立的16位寄存器使用,而低16位寄存器还可继续分为两个独立的8位寄存器使用。编译器会根据操作数大小选择合适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用,例如mov $5,%eax或mov eax,5,都表示将立即数5赋值给寄存器%eax。(AT&T汇编语法,在Unix和Linux系统中比较常见;Intel汇编语法,在Windows系统中比较常见)
在x86处理器中,EIP(Instruction Pointer)是指令寄存器,指向处理器下条等待执行的指令地址(代码段内的偏移量),每次执行完相应汇编指令EIP值就会增加;ESP(Stack Pointer)是堆栈指针寄存器,存放执行函数对应栈帧的栈顶地址(也是系统栈的顶部),且始终指向栈顶;EBP(Base Pointer)是栈帧基址指针寄存器,存放执行函数对应栈帧的栈底地址,用于C运行库访问栈中的局部变量和参数。
注意,EIP是个特殊寄存器,不能像访问通用寄存器那样访问它,即找不到可用来寻址EIP并对其进行读写的操作码(OpCode)。EIP可被jmp,call,ret等指令隐含地改变(事实上它一直都在改变)。
不同架构的CPU,寄存器名称被添加不同前缀以指示寄存器大小。例如x86架构用字母”e(extended)”作为名称前缀,指示寄存器大小为32位;x86_64架构用字母”r”作为名称前缀,指示各寄存器大小为64位。编译器在将C程序编译成汇编程序时,应遵循ABI所规定的寄存器功能定义。同样地,编写汇编程序时也应遵循,否则所编写的汇编程序可能无法与C程序协同工作。
【扩展】栈帧指针寄存器
为了访问函数局部变量,必须能定位每个变量。局部变量相对于堆栈指针ESP的位置在进入函数时就已确定,理论上变量可用ESP加偏移量来引用,但ESP会在函数执行期随变量的压栈和出栈而变动。尽管在某些情况下编译器能跟踪栈中的变量操作以修正偏移量,但要引入许多管理开销。而且在有些机器上(如Intel处理器),用ESP加偏移量来访问一个变量需要多条指令才能实现。
因此,许多编译器使用帧指针寄存器FP(Frame Pointer)记录栈帧基地址。局部变量和函数参数都可通过帧指针引用,因为它们到FP的距离不会受到压栈和出栈操作的影响。有些资料将帧指针称作局部基指针(LB-local base pointer)。
在Intel CPU中,寄存器BP(EBP)用作帧指针。在Motorola CPU中,除A7(堆栈指针SP)外的任何地址寄存器都可用作FP。当堆栈向下(低地址)增长,以FP地址为基准,函数参数的偏移量是正值,而局部变量的偏移量是负值。
2 寄存器使用约定
程序寄存器组是唯一能被所有函数共享的资源。虽然某一时刻只有一个函数在执行,但需保证当某个函数调用其他函数时,被调函数不会修改或覆盖主调函数稍后会使用到的寄存器值。因此,IA32采用一套统一的寄存器使用约定,所有函数(包括库函数)调用都必须遵守该约定。
根据惯例,寄存器%eax,%edx和%ecx为主调函数保存寄存器(caller-saved registers),当函数调用时,若主调函数希望保持这些寄存器的值,则必须在调用前显式地将其保存在栈中。被调函数可以覆盖这些寄存器,而不会破坏主调函数所需的数据;寄存器%ebx,%esi和%edi为被调函数保存寄存器(callee-saved registers),即被调函数在覆盖这些寄存器的值时,必须先将寄存器原值压入栈中保存起来,并在函数返回前从栈中恢复其原值,因为主调函数可能也在使用这些寄存器。此外,被调函数必须保持寄存器%ebp和%esp,并在函数返回后将其恢复到调用前的值,亦即必须恢复主调函数的栈帧。
这些工作都是由编译器在幕后进行。不过在编写汇编程序时应注意遵守上述惯例。
3 栈帧结构
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧是堆栈的逻辑片段,当调用函数时逻辑栈帧被压入堆栈,当函数返回时逻辑栈帧被压入堆栈,当函数返回时逻辑栈帧被从堆栈中弹出。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。
编译器利用栈帧,使得函数参数和函数中局部变量的分配与释放对程序员透明。编译器将控制权移交函数本身之前,插入特定代码将函数参数压入栈帧中,并分配足够的内存空间用于存放函数中的局部变量。使用栈帧的一个好处是使得递归变为可能,因为对函数的每次递归调用,都会分配给该函数一个新的栈帧,这样就巧妙地隔离当前调用与上次调用。
栈帧的边界由栈帧基地址指针EBP和堆栈指针ESP界定(指针存放在相应寄存器中)。EBP指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此,函数中对大部分数据的访问都基于EBP进行。
为更具描述性,以下称EBP为帧基指针,ESP为栈顶指针,并在引用汇编代码时分别记为%ebp和%esp。
函数调用栈的典型内存分布如下图:
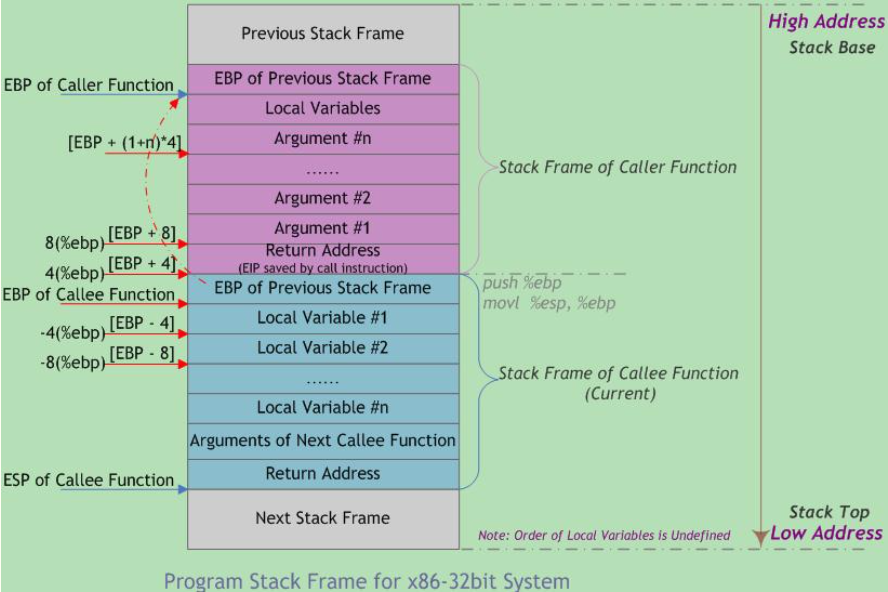
【注解】
上图是主调函数(caller)和被调函数(callee),主调函数寄存器是调用前保存变量和地址等,用来回调时还原现场。被调函数寄存器是在被调函数执行期间,对寄存器操作时,保存原值的。
“m(%ebp)”表示以EBP为基地址、偏移量为m字节的内存空间(中的内容)。该图基于两个假设:第一,函数返回值不是结构体或联合体,否则第一个参数将位于“12(%ebp)处”;第二,每个参数都是4字节大小(栈的粒度为4字节)。在本文后续章节将就参数的传递和大小问题做进一步的探讨。此外,函数可以没有参数和局部变量,故途中”Argument(参数)”和”Local Variable(局部变量)”不是函数栈帧结构的必要部分。
从图中可以看出,函数调用时入栈顺序为
主调函数帧基指针EBP→实参n~1→主调函数返回地址→被调函数帧基指针EBP→被调函数局部变量1~n其中,主调函数将参数按照调用约定依次入栈,然后将指令指针EIP入栈以保存主调函数的返回地址(下一条待执行指令的地址)。进入被调函数时,被调函数将主调函数的帧基指针EBP入栈,并将主调函数的栈顶指针ESP值赋给被调函数的EBP(作为被调函数的栈底),接着改变ESP值来为函数局部变量预留空间。此时被调函数帧基指针指向被调函数的栈底。以该地址为基准,向上(栈底方向)可获取主调函数的返回地址、参数值,向下(栈顶方向)能获取被调函数的局部变量值,而该地址处又存放着上一层主调函数的帧基指针值。本级调用结束后,将EBP指针值赋给ESP,使ESP再次指向被调函数栈底以释放局部变量;再将已压栈的主调函数帧基指针弹出到EBP,并弹出返回地址到EIP。ESP继续上移越过参数,最终回到函数调用前的状态,即恢复原来主调函数的栈帧。如此递归便形成函数调用栈。
EBP指针在当前函数运行过程中(未调用其他函数时)保持不变。在函数调用前,ESP指针指向栈顶地址,也是栈底地址。在函数完成现场保护之类的初始化工作后,ESP会始终指向当前函数栈帧的栈顶,此时,若当前函数又调用另外一个函数,则会将此时的EBP视为旧EBP压栈,而与新调用函数有关的内容会从当前ESP所指向位置开始压栈。
若需在函数中保存被调函数保存寄存器(如ESI、EDI),则编译器在保存EBP值时进行保存,或延迟保存知道局部变量空间被分配。在栈帧中并未为被调函数保存寄存器的空间指定标准的存储位置。包含寄存器和临时变量的函数调用栈布局可能如下所示。
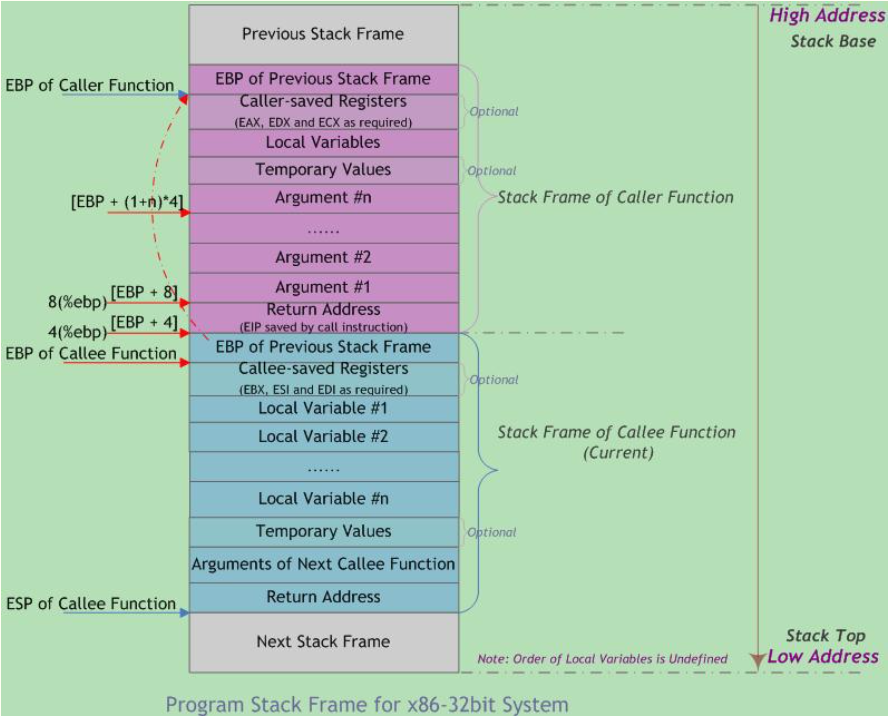
1 | |
输出结果如下:
1 | |
那么该函数栈布局示例如下图。为了直观起见,低于起始高地址0xbfc75a58的其他地址采用点记法,如0x.54表示0xbfc75a54.
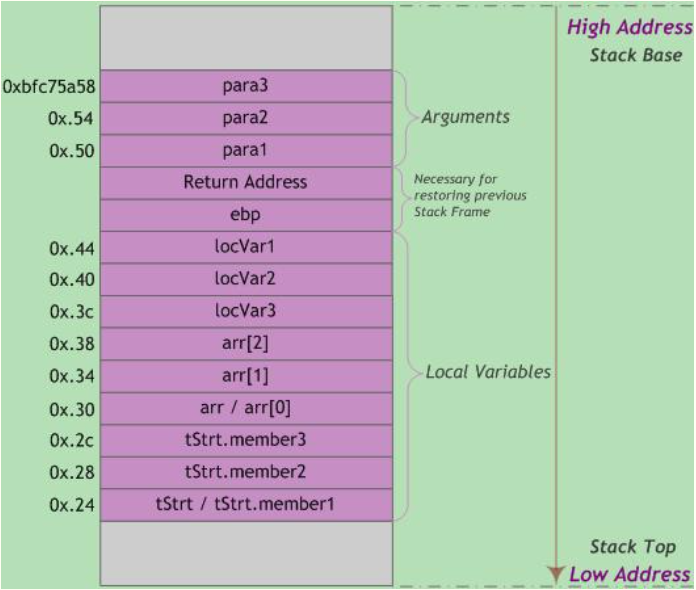
内存地址从栈底到栈顶递减,压栈就是把ESP指针逐渐往低地址移动的过程。而结构体tStrt中的成员变量memberX地址=tStrt首地址+(memberX偏移量),即越靠近tStrt首地址的成员变量其内存地址越小。因此,结构体成员变量的入栈顺序与其在结构体中的声明的顺序相反。
函数调用以值传递时,传入的实参(locMain1-3)与被调函数内操作的形参(para1-3)两者存储地址不同,因此被调函数无法直接修改主调函数实参值(对形参的操作相当于修改实参的副本)。为达到修改目的,需要向被调函数传递实参变量的指针(即变量的地址)。
此外,”[locMain1,2,3]=[0,0,3]”时因为对四字节参数locMain2调用memset函数时,会从低地址向高地址连续清零8个字节,从而误将位于高地址locMain1清零。
注意,局部变量的布局依赖于编译器实现等因素。因此,当StackFrameContent函数中删除打印语句时,变量locVar3、locVar2和locVar1可能按照从高到低的顺序一次存储!而且,局部变量并不总在栈中,有时出于性能(速度)考虑会存放在寄存器中。数组/结构体型的局部变量通常分配在栈内存中。
【扩展】函数局部变量布局方式
与函数调用约定规定参数如何传入不同,局部变量以何种方式布局并未规定。编译器计算函数局部变量所需要的空间总数,并确定这些变量存储在寄存器上还是分配在程序栈上(甚至被优化掉)——某些处理器并没有堆栈。局部变量的空间分配与主调函数和被调函数无关,仅仅从函数源代码上无法确定该函数的局部变量分布情况。
基于不同的编译器版本(gcc3.4中局部变量按照定义顺序一次入栈,gcc4及以上版本则不定)、优化级别、目标处理器架构、栈安全性等,相邻定义的两个变量在内存位置上可能相邻,也可能不相邻,前后关系也不固定。若要确保两个对象在内存上相邻且前后关系固定,可使用结构体或数组定义。
4 堆栈操作
函数调用时的具体步骤如下:
主调函数将被调函数所要求的参数根据相应的函数调用约定保存在运行时栈中。该操作会改变程序的栈指针。
注:x86平台将参数压入调用栈中。而x86_64平台具有16个通用64位寄存器,故调用函数时前6个参数通常由寄存器传递,其余参数才通过栈传递。
主调函数将控制权移交给被调函数(使用call指令)。函数的返回地址(待执行的下条指令地址)保存在程序栈中(压栈操作隐含在call指令中)。
若有必要,被调函数会设置帧基指针(EBP),并保存被调函数希望保持不变的寄存器值。
被调函数通过修改栈顶指针的值,为自己的局部变量在运行时栈中分配内存空间,并从帧基指针的位置处向低地址方向存放被调函数的局部变量和临时变量。
被调函数执行指令过程中,可能需要访问由主调函数传入的参数(从帧基指针的位置处向高地址方向存放参数)。若被调函数返回一个值,该值通常保存在一个指定寄存器中(如EAX)。
一旦被调函数完成操作,为该函数局部变量分配的栈空间将被释放。这通常是步骤4的逆向执行。
恢复步骤3中保存的寄存器值,包含主调函数的帧基指针寄存器。
被调函数将控制权交还主调函数(使用ret指令)。根据使用的函数调用约定,该操作也可能从程序栈上清除先前传入的参数。
主函数再次获得控制权后,可能需要将先前的参数从栈上清除。在这种情况下,对栈的修改需要将帧基指针恢复到步骤1之前的值。
步骤3和步骤4在函数调用之初常一同出现,统称为函数序(prologue);步骤6到步骤8在函数调用的最后常一同出现,统称为函数跋(epilogue)。函数序和函数跋是编译器自动添加的开始和结束汇编代码,其实现与CPU架构和编译器相关。除步骤5代表函数实体外,其它所有操作组成函数调用。
接下来是函数调用过程中的主要指令。
压栈(push):栈顶指针ESP减小4个字节;以字节为单位将寄存器数据(四字节,不足补零)压入堆栈,从高到低按字节依次将数据存入ESP-1、ESP-2、ESP-3、ESP-4指向的地址单元。
出栈(pop):栈顶指针ESP指向的栈中数据被取回到寄存器;栈顶指针ESP增加4个字节。
出栈与入栈操作示意图
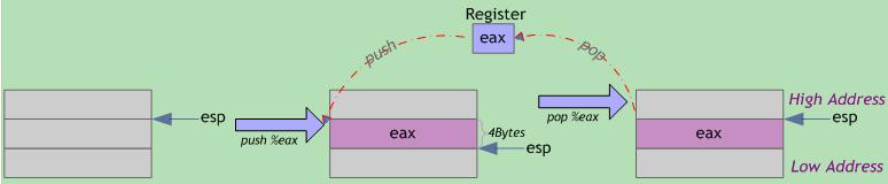
可见,压栈操作将寄存器内容存入栈内存中(寄存器原内容不变),栈顶地址减小;出栈操作从栈内存中取回寄存器内容(栈内已存数据不会自动清零),栈顶地址增大。栈顶指针ESP总是指向栈中下一个可用数据。
调用(call):将当前的指令指针EIP(该指针指向紧接在call指令后的下条指令)压入堆栈,以备返回时能恢复执行下条指令;然后设置EIP指向被调函数代码开始处,以跳转到被调函数的入口地址执行。
离开(leave):恢复主调函数的栈帧以准备返回。等价于指令序列
movl %ebp, %esp(恢复原ESP值,指向被调函数栈帧开始处)和popl %ebp(恢复原ebp的值,即主调函数帧基指针)。返回(ret):与call指令配合,用于从函数或过程返回。从栈顶弹出返回地址(之前call指令保存的下条指令地址)到EIP寄存器中,程序转到该地址处继续执行(此时ESP指向进入函数时的第一个参数)。若带立即数,ESP再加立即数(丢弃一些再执行call前入栈的参数)。使用该指令前,应使当前栈顶指针所指向位置的内容正好是先前call指令保存的返回地址。
基于以上指令,使用C调用约定的被调函数典型的函数序和函数跋实现如下:

若主调函数和被调函数均未使用局部变量寄存器EDI、ESI和EBX,则编译器无需在函数序中对其压栈,以便提高程序的执行效率。
注意,栈帧是运行时概念,若程序不运行,就不存在栈和栈帧。但通过分析目标文件中建立函数栈帧的汇编代码(尤其是函数序和函数跋过程),即使函数没有运行,也能了解函数的栈帧结构。通过分析可确定分配在函数栈帧上的局部变量空间准确值,函数中是否使用帧基指针,以及识别函数栈帧中对变量的所有内存引用。
5 函数调用约定
创建一个栈帧的最重要步骤是主调函数如何向栈中传递函数参数。主调函数必须精确存储这些参数,以便被调函数能够访问到它们。函数通过选择特定的调用约定,来表明其希望以特定方式接收参数。此外,当被调函数完成任务后,调用约定规定先前入栈的参数由主调函数还是被调函数负责清除,以保证程序的栈顶指针完整性。
函数调用与欸的那个通常规定如下几个方面内容:
函数参数的传递顺序和方式
最常见的参数传递方式是通过堆栈传递。主调函数将参数压入栈中,被调函数以相对于帧基指针的正偏移量来访问栈中的参数。对于有多个参数的函数,调用约定需规定主调函数将参数压栈的顺序(从左至右还是从右至左)。某些调用约定允许使用寄存器传参以提高性能。
栈的维护方式
主调函数将参数压栈后调用被调函数体,返回时需将被压栈的参数全部弹出,以便将栈恢复到调用前的状态。该清栈过程可由主调函数负责完成,也可由被调函数负责完成。
名字修饰(name-mangling)策略
又称函数名修饰(Decorated Name)规则。编译器在链接时为区分不同函数,对函数名作不同修饰。若函数之间的调用约定不匹配,可能会产生堆栈异常或链接错误等问题。因此,为了保证程序能正确执行,所有的函数调用均应遵守一致的调用约定。
5.1 常见调用约定
cdecl调用约定
又称C调用约定,是C/C++编译器默认的函数调用约定。函数参数按照从右到左的顺序入栈,函数调用者负责清除栈中的参数,返回值在EAX中。名字修饰约定是在函数名前添加一个下划线;但对于C++函数,使用不同的名字修饰方式。
stdcall调用约定
Pascal程序缺省调用方式,WinAPI也多采用该调用约定。函数参数按照从右向左入栈,除指针或引用类型参数外所有参数采用传值方式传递。由被调函数负责清除栈中的参数,返回值在EAX中。对于C函数,名称修饰方式是在函数名字前添加下划线,在函数名字后添加@和函数参数大小,如_functionname@number.
fastcall调用约定
通常使用ECX和EDX寄存器传递前两个DWORD(四字节双字)类型或更少字节的函数参数,其余参数按照从右向左的顺序入栈。被调函数在返回前负责清除栈中的参数,返回值在EAX中。名称修饰方式是使用两个@修饰函数名称,后跟十进制数表示的函数参数列表大小(字节数),如@function_name@number。
thiscall调用约定
C++类中的非静态函数必须接收一个指向主调对象的类指针(this指针),并可能较频繁的使用该指针。主调函数的对象地址必须由调用者提供,并在调用对象非静态成员函数时将对象指针以参数形式传递给被调函数。编译器默认使用thiscall调用约定以高效传递和存储C++类的非静态成员函数的this指针参数。
参数按照从右向左顺序入栈。若参数数目固定,则类实例的this指针通过ECX寄存器传递给被调函数,被调函数自身清理堆栈;若参数数目不定,则this指针在所有参数入栈后再入栈,主调函数清理堆栈。
注意,该调用约定特点随编译器不同而不同,g++中thiscall与cdecl基本相同,只是隐式地将this指针当作非静态成员函数的第1个参数,主调函数在调用返回后负责清理栈上参数;而在VC中,this指针存放在%eax寄存器中,参数从右至左压栈,非静态成员函数负责清理栈上参数。
naked call调用约定
对于使用naked call方式声明的函数,编译器不产生保存(prologue)和恢复(epilogue)寄存器的代码,且不能用return返回返回值(只能用内嵌汇编返回结果),故称naked call。该调用约定用于一些特殊场合,如声明处于非C/C++上下文中的函数,并由程序员自行编写初始化和清栈的内嵌汇编指令。
注意,naked call并非类型修饰符,故该调用约定必须与__declspec同时使用,如VC下定义求和函数:
1 | |
__declspec是微软关键字,其他系统上可能没有。
pascal调用约定
Pascal语言调用约定,参数按照从左至右顺序入栈。Pascal语言只支持固定参数的函数,参数的类型和数量完全可知,故由被调函数自身清理堆栈。pascal调用约定输出的函数名称无任何修饰且全部大写。
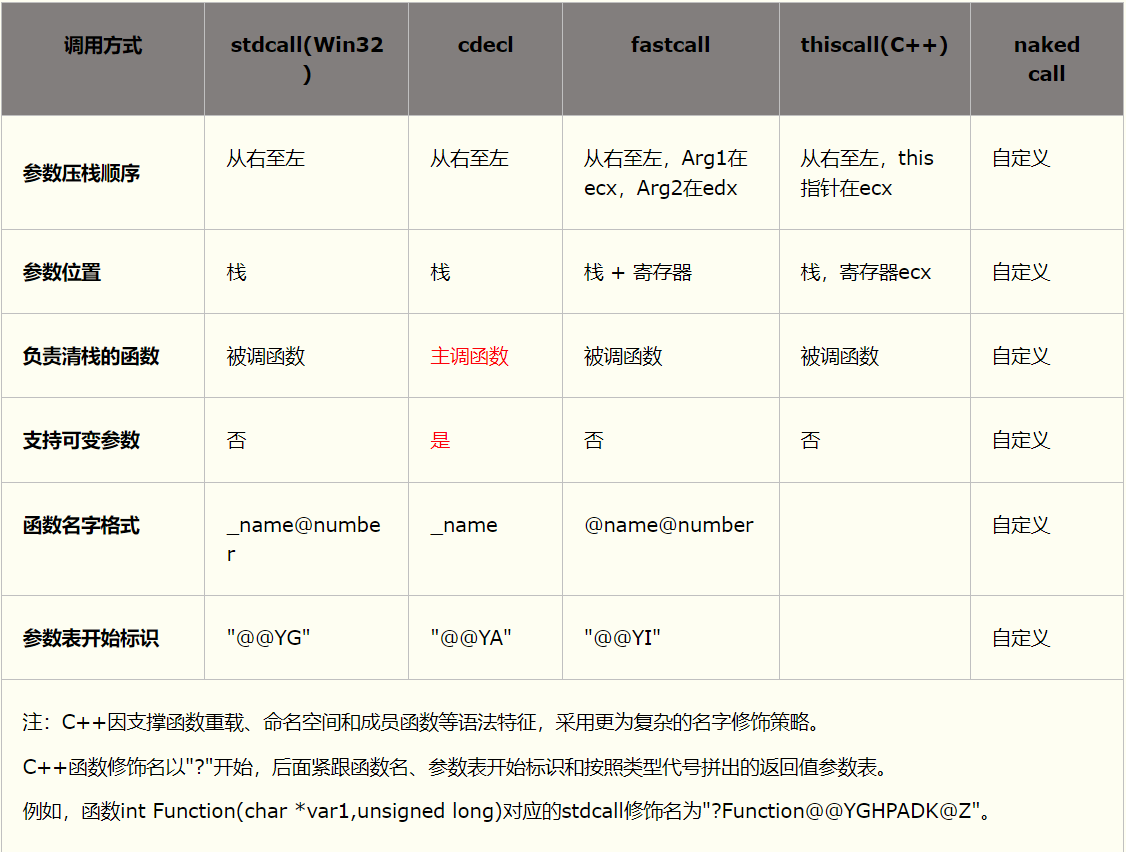
Windows下可直接在函数声明前添加关键字__stdcall、__cdecl或__fastcall等标识确定函数的调用方式,如int __stdcall func()。Linux下可借用函数attribute机制,如int __attribute__((__stdcall__))func()。例如:
1 | |
被调函数CalleeFunc分别声明为cdecl、stdcall和fastcall约定时,其汇编代码比较如下表所示:
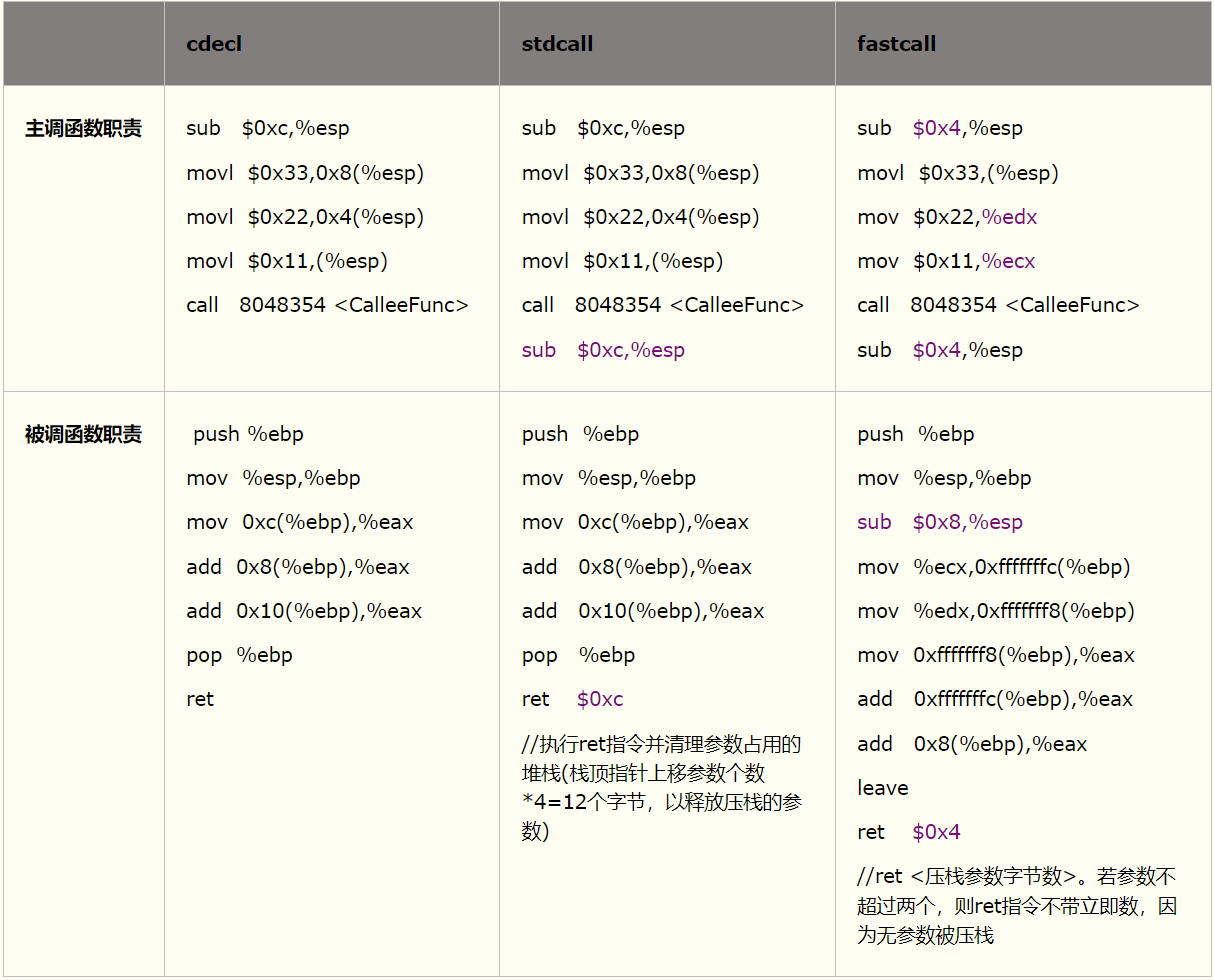
5.2 调用约定影响
当函数导出被其他程序员所使用(如库函数)时,该函数应遵循主要的调用约定,以便于程序员使用。若函数仅供内部使用,则其调用约定可只被使用该函数的程序所了解。
在多语言混合变成时,若函数的原型声明和函数体定义不一致或调用函数时声明了不同的函数约定,将可能导致严重的问题。
以Delphi调用C函数为例。Delphi函数缺省采用stdcall调用约定,而C函数缺省采用cdecl调用约定。一般将C函数声明为stdcall约定,如:int __stdcall add(int a, int b);
在Delphi中调用该函数时也应声明为stdcall约定:
1 | |
不同编译器产生栈帧的方式不尽相同,主调函数不一定能正常完成清栈工作;而被调函数必然能自己完成正常清栈,因此,在跨平台调用中,通常使用stdcall调用约定。
此外,主调函数和被调函数所在模块采用相同的调用约定,但分别使用C++和C语法编译时,会出现链接错误(报告被调函数未定义)。这是因为两种语言的函数名字修饰规则不同,解决方式是使用extern “C”告知主调函数所在模块:被调函数是C语言编译的。采用C语言编译的库应考虑到使用该库的程序可能是C++程序(使用C++编译器),通常应这样声明头文件:
1 | |
这样C++编译器就会按照C语言修饰策略链接Func函数名,而不会出现找不到函数的链接错误。
5.3 x86函数参数传递方法
x86处理器ABI规范中规定,所有传递给被调函数的参数都通过堆栈来完成,其压栈顺序是以函数参数从右到左的顺序。当向被调函数传递参数时,所有参数最后形成一个数组。由于采用从右到左的压栈顺序,数组中参数的顺序与函数参数声明顺序一致。因此,在函数中若知道第一个参数地址和各参数占用字节数,就可通过访问数组的方式去访问每个参数。
5.3.1 整型和指针参数的传递
整型参数与指针参数的传递方式相同,因为在32位x86处理器上整型与指针大小相同(均为四字节)。下表给出这两种类型的参数在栈帧中的位置关系。注意,该表基于tail函数的栈帧。
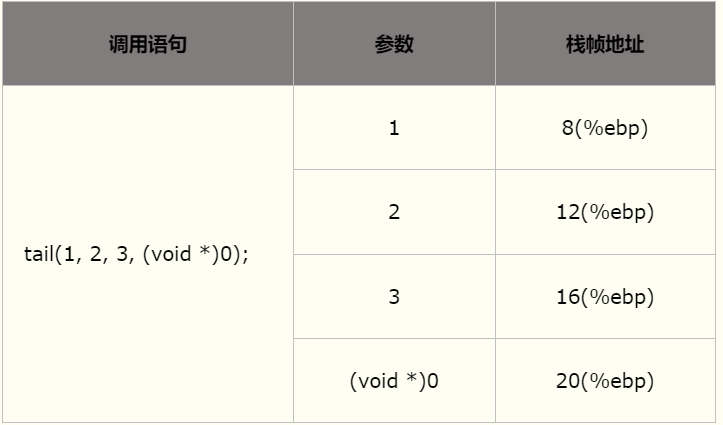
5.3.2 浮点参数的传递
浮点参数的传递与整型类似,区别在于参数大小。x86处理器中浮点类型占8个字节,因此在栈中也需要占用8个字节。下表给出浮点参数在栈帧中的位置关系。图中,调用tail函数的第一个和第三个参数均为浮点类型,因此需各占用8个字节,三个参数共占用20个字节。表中word类型的大小是4个字节。
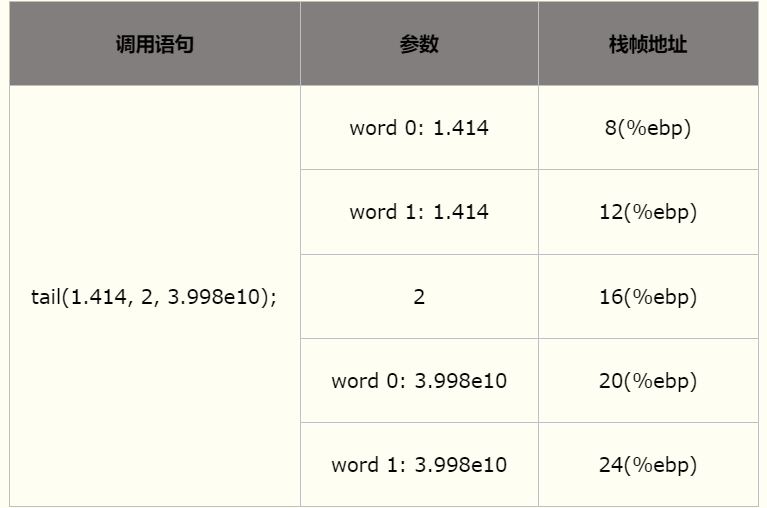
5.3.3 结构体和联合体参数的传递
结构体和联合体参数的传递与整型、浮点参数类似,只是其占用字节大小视数据结构的定义不同而异。x86处理器上栈宽是4字节,故结构体在栈上所占用的字节数为4的倍数。编译器会对结构体进行适当的填充以使得结构体大小满足4字节对齐的要求。
对于一些RISC处理器(如PowerPC),其参数传递并不是全部通过栈来实现。PowerPC处理器寄存器中,R3~R10共8个寄存器用于传递整型或指针参数,F1~F8共8个寄存器用于传递浮点参数。当所需传递的参数少于8个时,不需要用到栈。结构体和long_double参数的传递通过指针来完成,这与x86处理器完全不同。PowerPC的ABI规范中规定,结构体的传递采用指针方式,而不是像x86处理器那样将结构从一个函数栈帧中拷贝到另一个函数栈帧中,显然x86处理器的发昂是更低效。可见,PowerPC程序中,函数参数采用指针结构体的指针并不能提高效率,不过通常这是良好的编程习惯。
5.4 x86函数返回值传递方法
函数返回值可通过寄存器传递。当被调用函数需要返回结果给调用函数时:
若返回值不超过4字节(如int、short、char、指针等类型),通常将其保存在EAX寄存器中,调用方式通过读取EAX获取返回值。
若返回值大于4字节而小于8字节(如long long或_int64类型),则通过EAX+EDX寄存器联合返回,其中EDX保存返回值高4字节,EAX保存返回值低4字节。
若返回值为浮点类型,则通过专用的协处理器浮点数寄存器栈的栈顶返回。
若返回值为结构体或联合体,则主调函数向被调函数传递一个额外参数,该参数指向将要保存返回值的地址。即函数调用foo(p1, p2)被转化成foo(&p0, p1, p2),以引用型参数形式传回返回值。
不要返回指向栈内存的指针,如返回被调函数内局部变量地址(包括局部数组名)。因为函数返回后,其栈帧空间被”释放“,原栈帧内分配的局部变量空间的内容是不稳定和不被保证的。
函数返回值通过寄存器传递,无需空间分配等操作,故返回值的代价很低。基于此原因,C89规范中约定,不写明返回值类型的函数,返回值类型默认为int。但这会带来类型安全隐患,如函数定义时返回值为浮点数,而函数未声明或声明时未指明返回值类型,则调用时默认从寄存器EAX中获取返回值,导致错误!因此在C++中,不写明返回值类型的函数返回值类型为void。
64位寄存器的图:

需要注意的是,32位和64位程序有以下简单的区别
- x86
- 函数参数在函数返回地址的上方
- x64
- System V AMD64 ABI(Linux、FreeBSD、macOS等采用)中前六个整型或指针参数依次保存在RDI,RSI,RDX,RCX,R8和R9寄存器中,如果还有更多的参数的花,才会保存在栈上。
- 内存地址不饿能大于0x00007FFFFFFFFFFF,6个字节长度,否则会抛出异常。
栈溢出原理
介绍
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是:
- 程序必须向栈上写入数据
- 写入的数据大小没有被良好地控制
基本示例
最典型的栈溢出利用是覆盖程序的返回地址为攻击者所控制的地址,**当然需要确保这个地址所在的段具有可执行权限。**下面,简单示例:
1 | |
这个程序的主要目的读取一个字符串,并将其输出。我们希望可以控制程序执行success函数。
正常使用gcc对上述程序进行编译

gets本身是一个危险函数。它从不检查输入字符串的长度,而是以回车来判断输入是否结束,所以很容易可以导致栈溢出,gcc编译指令中,-m32指的是生成32位程序;-fno-stack-protector指的是不开启堆栈溢出保护,即不生产canary。此外,为了更加方便地介绍栈溢出的基本利用方式,这里还需要关闭PIE(Position Independent Executable),避免加载基址被打乱。不同gcc版本对于PIE的默认配置不同,可以使用命令gcc -v查看gcc默认的开关情况。如果含有–enable-default-pie参数则代表PIE默认已开启,需要在编译指令中添加参数-no-pie
使用如下指令进行编译:
1 | |

编译成功后,可以使用checksec工具检查编译出的文件:
1 | |

编译时的PIE保护,Linux平台下还有地址空间分布随机化(ASLR)的机制。简单来说即使可执行文件开启了PIE保护,还需要系统开启ASLR才会真正打乱基址,否则程序运行时依旧会加载一个固定的基址上(不过和No PIE时基址不同)。可以通过修改/proc/sys/kernel/randomize_va_space来控制ASLR启动与否,具体的选项有:
- 0,关闭ASLR,没有随机化。栈、堆、.so的基地址每次都相同。
- 1,普通的ASLR。栈基地址、mmap基地址、.so加载基地址都将被随机化,但是堆基地址没有随机化。
- 2,增强的ASLR,在1的基础上,增加了堆基地址随机化。
我们可以使用echo 0 > /proc/sys/kernel/randomize_va_space关闭Linux系统的ASLR,类似的,也可以配置相应的参数。
为了降低后续漏洞利用复杂度,此次演示关闭ASLR,在编译时关闭PIE。也可以尝试ASLR、PIE开关的不同组合,配合IDA及动态调试功能观察程序地址变化情况(在ASLR关闭、PIE开启时也可以攻击成功)。
确认栈溢出和PIE保护关闭后,利用IDA来反编译一下二进制程序并查看vulnerable函数。可以看到

该字符串距离ebp的长度为0x14,那么相应的栈结构为
1 | |
通过IDA View-A窗口可以看到success的地址,其地址为0x08049186

由于gets会读到回车才算结束,所以我们可以直接读取所有的字符串,并将saved ebp覆盖为bbbb,将retaddr覆盖为success_addr,即,此时的栈结构为:
1 | |
但是需要注意的是,由于在计算机内存中,每个值都是按照字节存储的。一般情况下都是采用小端存储,即0x000011AD在内存中的形式是
1 | |
但是,无法做到直接在终端将这些字符给输入进去,在终端输入的时候\,x等也算一个单独的字符。所以需要想办法将\x3b作为一个字符输入进去。那么此时,就需要使用一波pwntools,这里利用pwntools的代码如下:
1 | |
执行代码,获得结果

发现,已经成功执行success函数。
总结
示例展示栈溢出中比较重要的几个步骤。
寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有栈溢出,以及有的话,栈溢出的位置在哪里。常见的危险函数如下
- 输入
- gets,直接读取一行,忽略’\x00’
- scanf
- vscanf
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到’\x00’停止
- strcat,字符串拼接,遇到’\x00’停止
- bcopy
确定填充长度
这一部分主要是计算所要操作的地址与所要覆盖的地址的距离。常见的操作方法就是打开IDA,根据其给定的地址计算偏移。一般变量会有以下几种索引模式
- 相对于栈基地址的索引,可以直接通过查看EBP相对偏移获得
- 相对应栈顶指针的索引,一般需要进行调试,之后还是会转换到第一种类型。
- 直接地址索引,就相当于直接给定了地址。
一般来说,会有如下的覆盖需求
- 覆盖函数返回地址,这时候就是直接看EBP即可。
- 覆盖栈上某个变量的内容,这时候需要更加精细的计算。
- 覆盖bbs段某个变量的内容
- 根据现实执行情况,覆盖特定的变量或地址内容。
之所以想要覆盖某个地址,是因为我们想通过覆盖地址的方法来直接或间接地控制程序执行流程。
Linux下ASLR与PIE
首先,ASLR是操作系统的功能选项,作用于executable(ELF,可执行文件)装入内存运行时,因而只能随机化stack、heap、libraries的基址;而PIE(Position Independent Executables)是编译器(gcc,….)功能选项,作用于executable编译过程,可将其理解为特殊的PIC,加了PIE选项编译出来的ELF用file命令查看会显示其为so,其随机化了ELF装载内存的基址(代码段、plt、got、data等共同的基址)。
其次,ASLR早于PIE出现,所以有return-to-plt、got hijack、stack-pivot(bypass stack ransomize)等绕过ASLR的技术;而在ASLR+PIE之后,这些bypass技术就都失效了,只能借助其他的信息泄露漏洞泄露基址(常用libc基址)。
基本ROP
随着NX(Non-eXecutable)保护的开启,传统的直接向栈或者堆上直接注入代码的方式难以继续发挥效果,由此攻击者们也提出来相应的方法来绕过保护。
NX保护是一种重要的安全机制,它通过将数据段标记为不可执行来阻止攻击者在内存中执行恶意代码。
传统的内存布局中,代码段和数据段通常位于同一内存空间。攻击者可以利用缓冲区溢出漏洞,将恶意代码覆盖到数据段,并通过修改程序流程指针,让程序跳转到数据段执行恶意代码。
NX保护通过将数据段标记为不可执行,使得攻击者无法在数据段中执行代码。即使攻击者成功覆盖了数据段,程序也不会执行恶意代码。
启用的方法:
- 使用支持NX保护的编译器编译程序,例如GCC编译器可以添加
-fstack-protector选项来启用栈保护。- 在操作系统中启用NX保护,例如在Linux系统中,可以使用sysctl命令启用
kernel.exec-shield选项。
目前被广泛使用的攻击手法是返回导向编程(Return Oriented Programming),其主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段来改变某些寄存器或者变量的值,从而控制程序的执行流程。
gadgets通常是以ret结尾的指令序列,通过这样的指令序列,可以多次劫持程序控制流,从而运行特定的指令序列,以完成攻击的目的。
返回导向编程这一名称的由来是因为其核心在于利用了指令集的ret指令,从而改变了指令流的执行顺序,并通过数条gadget“执行”了一个新的程序。
使用ROP攻击一般得满足如下条件:
- 程序漏洞允许我们劫持控制流,并控制后续的返回地址。
- 可以找到满足条件的gadgets以及相应gadgets的地址。
作为一项基本的攻击手段,ROP攻击并不局限于栈溢出漏洞,也被广泛应用在堆溢出等各类漏洞的利用当中。
需要注意的是,现代操作系统通常会开启地址随机化保护(ASLR),这意味着gadgets在内存中的位置往往是不固定的。但幸运的是其对于对应段基址的偏移通常是固定的,因此我们在寻找到了合适的gadgets之后可以通过其他方式泄露程序运行环境信息,从而计算出gadgets在内存中的真正地址。
ret2text
原理
ret2text即控制程序执行程序本身已有的代码(即,.text段中的代码)。其实,这种攻击方法是一种笼统的描述。我们控制执行程序已有的代码的时候也可以控制程序执行好几段不相邻的程序已有的代码(也就是gadgets),这就是所要说的ROP。
这是,需要知道对应返回的代码的位置。当然程序也可能会开启某些保护,需要想办法去绕过这些保护。
Example
其实,在栈溢出的基本原理中,已经介绍了这一简单的攻击。在这里,再给出另外一个例子,bamboofox中介绍ROP时使用的ret2text的例子。
首先查看一下程序的保护机制:

可以看出程序是32位程序,且仅开启了栈不可执行(NX)保护。接下来使用IDA反编译该程序。

程序在主函数中使用了gets函数,显然存在栈溢出漏洞。接下来查看反汇编代码:
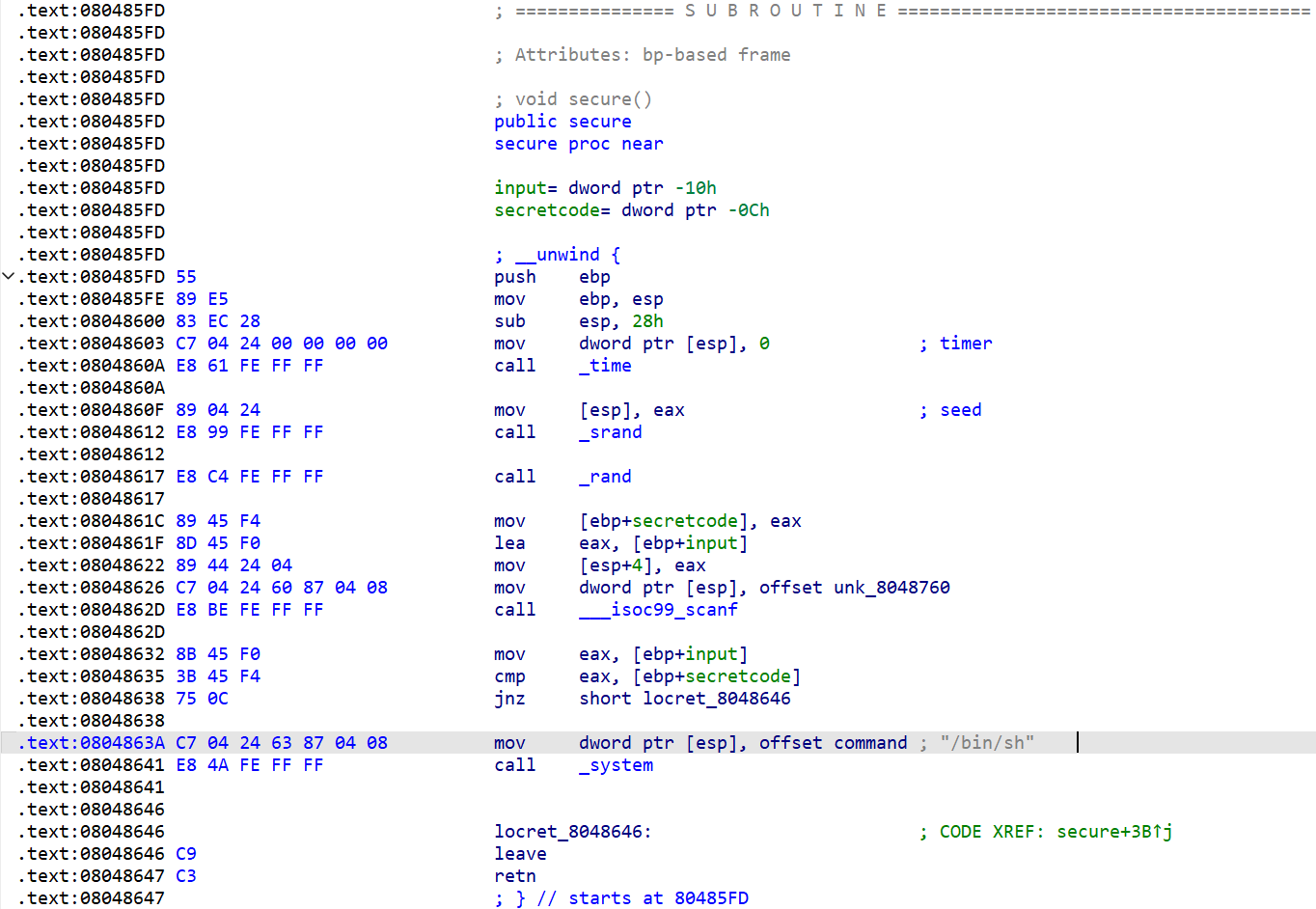
在secure函数又发现了存在调用system("/bin/sh")的代码,那么如果直接控制程序返回至0x0804863A,那么就可以得到系统的shell了。
下面就是如何构造payload,首先需要确定的是我们能够控制的s变量距离main函数的返回地址的字节数。
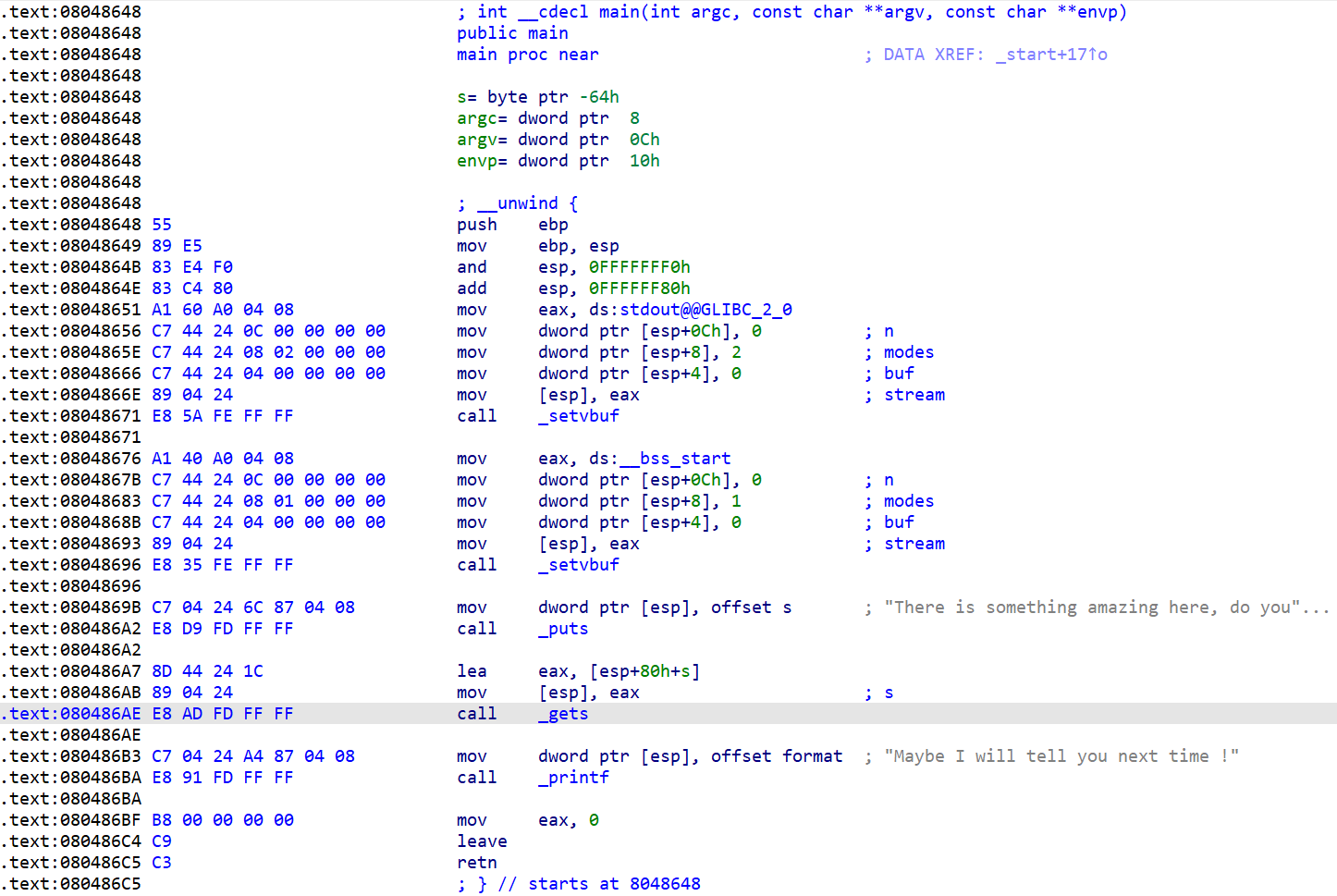
可以看到该字符串是通过相对于esp的索引,所以需要进行调试,将断点下在call处,查看esp,ebp,如下:

可以看到esp为0xff9bd220,ebp为0xff9bd2a8,s相对于esp的索引为esp+0x1c,因此,我们可以推断:
- s的地址为0xff9bd23c
- s相对于ebp的偏移为0x6c
- s相对于返回地址的偏移为0x6c+4(+4是因为ret_addr占四个字节)
因此,最后的payload如下:
1 | |
re2shellcode
原理
ret2shellcode,即控制程序执行shellcode代码。shellcode指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的shell。通常情况下,shellcode需要我们自行编写,即此时我们需要自行向内存中填充一些可执行的代码。
在栈溢出的基础上,要想执行shellcode,需要对应的binary在运行时,shellcode所在的区域具有可执行权限。需要注意的是,在新版内核当中引入了较为激进的保护策略,程序中通常不再默认有同时具有可写与可执行的段,这使得传统的ret2shellcode手法不再能直接完成利用。
example
检测程序开启的保护:

几乎没有开启任何保护,并且有可读,可写,可执行段。接下来再使用IDA对程序进行反编译:

程序仍然是基本的栈溢出漏洞,不过还同时将对应的字符串复制到buf2处。简单查看可知buf2在bss段。

这时,简单的调试下程序,看看这个bbs段是否可执行。

图中可以看出0x804a000 ~ 0x804b000没有可执行权限,因为环境是ubuntu22.04,内核的保护策略,使得程序中不再默认有同时具有可写可执行的段。
倘若有可执行权限,那么就控制程序执行shellcode,也就是读入shellcode,然后控制程序执行bbs段处的shellcode。其中,相应的偏移计算类似于ret2text中的例子。
最后的payload如下:
1 | |
ret2syscall
原理
ret2syscall,即控制程序执行系统调用,获取shell。
example
继续以bamboofox中的ret2syscall为例。
首先检测程序开启的保护:

可以看出,源程序为32位,开启了NX保护。接下来利用IDA进行反编译:

可以看出,这依然是一个栈溢出。类似于之前的做法,我们可以获得v4相对于ebp的偏移为108。所以需要覆盖的返回地址相对于v4的偏移为112.此次,由于不能直接利用程序中的某一段代码或者自己填写代码来获得shell,所以利用程序中的gadgets来获得shell,而对应的shell获取则是利用系统调用。
系统调用
在电脑中,系统调用(system call),指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态执行。如设备IO操作或者进程间通信。
操作系统的进程空间可分为用户空间和内核空间,它们需要不同的执行权限。其中系统调用运行在内核空间。
典型实现(Linux)
Linux在x86上的系统调用通过
int 80h实现,用系统调用号来区分入口函数。操作系统实现系统调用的基本过程是:
- 应用程序调用库函数(API);
- API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
- 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
- 系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
- 中断处理函数返回到API中;
- API将EAX返回给应用程序。
应用程序调用系统调用的过程是:
- 把系统调用的编号存入EAX;
- 把函数参数存入其它通用寄存器;
- 触发0x80号中断(int 0x80)。
简单地说,只要把对应获取shell的系统调用的参数放到对应的寄存器中,那么在执行int 0x80就可以执行对应的系统调用。比如这里我们利用如下系统调用来获取shell:
1 | |
其中,该程序是32位,所以我们需要使得
- 系统调用号,即eax应该为0xb。(execve的系统调用号为11)
- 第一个参数,即ebx应该指向/bin/sh的地址,其实执行sh的地址也可以。
- 第二个参数,即ecx应该为0
- 第三个参数,即edx应该为0
那么该如何控制这些寄存器的值呢?这里就需要使用gadgets。比如说,现在栈顶是10,那么如果此时执行了pop eax,那么现在eax的值就为10。但是我们并不能期待有一段连续的代码可以同时控制对应的寄存器,所以我们需要一段一段控制。这也是我们在gadgets最后使用ret来在此控制程序执行流程的原因。具体寻找gadgets的方法,我们可以使用ropgadgets这个工具。
1 | |
可以看到有上述几个都可以控制eax,选取第二个作为gadgets
类似的,可以得到控制其他寄存器的gadgets
1 | |
这里,选择
1 | |
这条指令可以直接控制其他三个寄存器。
此外,我们需要获得/bin/sh 字符串对应的地址。
1 | |
可以找到对应的地址,此外,还有int 0x80的地址,如下
1 | |
Payload如下:
1 | |
ret2libc
原理
ret2libc即控制函数执行libc中的函数,通常是返回至某个函数的plt处或者函数的具体位置(即函数对应的got表项的内容)。一般情况下,选择执行system(“/bin/sh”),故而此时我们需要知道system函数的地址。
example1
以bamboofox中ret2libc1为例。
首先,依然check下安全保护:
1 | |
源程序为32位,开启NX保护。随后对其进行反编译,以确定漏洞位置。反编译结果如下:
1 | |
使用gets函数,即栈溢出。可以利用ropgadget,查看是否有/bin/sh存在:
1 | |
确实存在,再次查找下是否有system函数存在。

存在,那么直接返回这个地址,即执行system函数。相应的payload如下:
1 | |
注意的是,为什么system的入口地址覆盖ret地址后,需要一个
b'b'*4的填充,因为在执行函数体指令前,会push一个当前的地址,以便函数调用结束后能返回。根据栈帧结构可以看出,被调函数的ret_addr上面紧接着是函数
example2
该题目与retlibc基本一致,只不过不再出现/bin/sh字符串,所以我们需要两个gadgets,第一个控制程序读取字符串,第二个控制程序执行”system(“/bin/sh”)。漏洞与上述一致。
老规矩,查看保护措施:
1 | |
ida反编译:

例题的函数就是简单哈。gets栈溢出,覆盖返回地址。查看函数列表:
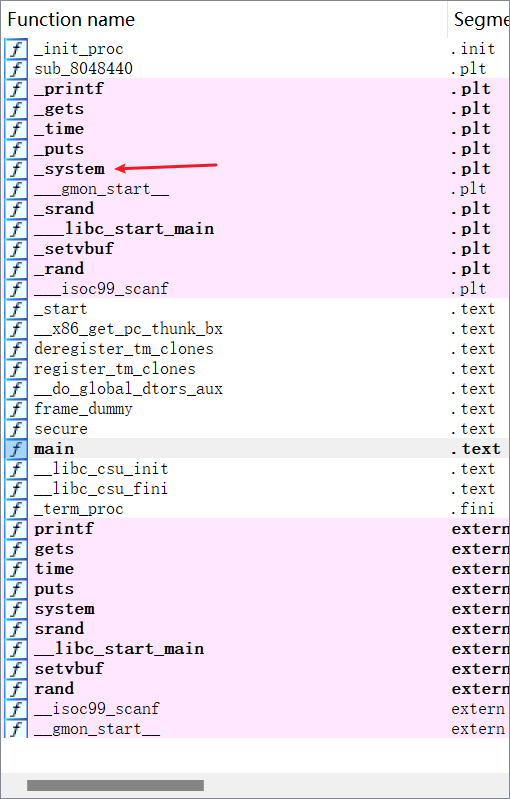
具有_system()函数,查找一下有没有”/bin/sh”字符串。

没有。那我也不知道咋办了。看看exp吧
1 | |
计算填充:


那么,32位程序的填充就是108+4就是112。而返回地址是gets_plt,不理解。ida看看这个地址。

居然是gets函数的地址。返回地址又重新进入的gets函数。
buf2是在.bss段定义的变量。

这个.bss段具有写的权限吗?因为我们需要在这个变量中写入数据。

可以看到,s变量所在的区间没有可写的权限,有可读可执行。再者,因为s变量是局部变量,而.bss段的是全局变量,且具有可写权限,因此作为我们ROP的第一跳。
gets函数执行完后,会返回到pop_ebx指令的地址。pop_ebx指令会弹出栈顶的 4 个字节,并将该值写入ebx寄存器,此时ebx寄存器存放的是buf2地址。- 程序执行下一条指令,即
system_plt地址。- 程序执行
system_plt地址,会跳转到system函数的.plt段条目,最终执行system函数。- 此时
system函数的第一个参数是buf2地址,因为之前pop_ebx指令将buf2地址写入ebx寄存器,而system函数会将ebx寄存器的值作为第一个参数。system函数的第二个参数是buf2地址,因为你之前在构造 payload 时已经将buf2地址写入到栈中,作为第二个参数。
一切是那样好~
example3
题目类似,我们查看源码:

查看保护机制:
1 | |
只有NX保护,即开启了堆栈不可执行保护。
其漏洞利用点依然是gets函数的栈溢出。再查看函数列表:
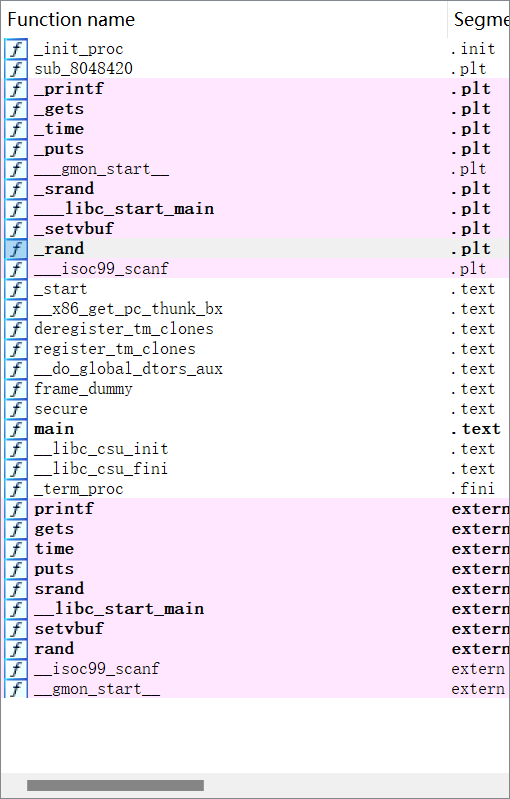
发现并没有system函数。也没有/bin/sh字符串的地址。重要的是如何获得system函数的地址。
- system函数属于libc,而libc.so动态链接库中的函数之间相对偏移是固定的。
- 即使程序有ASLR保护,也只是针对地址中间位进行随机的,最低的12位并不会发生改变。而libc在github上有人进行收集,如下
- https://github.com/niklasb/libc-database
所以,如果能够知道libc中的某个函数的地址,那么可以确定该程序调用的libc地址。进而就可以知道system函数的地址。那么该如何得到libc中的某个函数的地址呢?一般常用的方法是采用got表泄露,即输出某个函数对应的got表现内容。当然,由于libc的延迟绑定机制,需要泄露已经执行过的函数的地址。
libc的延迟绑定机制是指在程序运行时,动态链接库的函数地址并非在程序加载时就确定,而是第一次调用该函数时才进行地址绑定。
延迟绑定机制的步骤如下:
程序加载
当程序加载时,libc库的函数地址并不被解析,而是被设置为一个特殊的地址,例如
0x8048270。第一次调用
当程序第一次调用一个动态链接库函数时,例如
printf,程序会执行plt中的跳转指令。解析地址
plt指令会跳转到got中的地址。由于该地址尚未解析,所以程序会进入一个称为
lazy binding的过程,该过程会查找动态链接库的符号表,找到printf函数的地址,并将地址写入got中。后续调用
在后续的调用中,程序会直接跳转到got中的地址,不再需要进行地址解析。
因此,可以根据上面的步骤先得到libc库基地址,之后在程序中查询偏移,然后获取system函数地址。
这里选择泄露__libc_start_main的地址,这是因为它是程序最初被执行的地方。基本利用思路如下
- 泄露
__libc_start_main地址 - 获取libc版本
- 获取system地址与/bin/sh地址
- 再次执行源程序
- 出发栈溢出执行system(‘/bin/sh’)
exp如下:
1 | |
泄露libc库的原理
- 利用GOT(Global Offset Table,全局偏移表)和 PLT(Procedure Linkage Table,过程链接表)
- GOT:存储着动态链接库的地址。程序第一次调用某个动态链接库函数时,该函数的地址会从GOT中获取。
- PLT:存储着调用动态链接库函数的跳转指令。程序调用函数时,会先执行PLT中的跳转指令,跳转指令会执行GOT中的函数地址。
- 原理:攻击者通过程序漏洞(如缓冲区溢出)覆盖某个函数的GOT地址,例如puts函数,使其指向另一个已知函数,如
printf。然后再次调用该函数(puts),实际上会执行printf函数,并利用printf函数输出一些信息,例如GOT中存储的__libc_start_main函数的地址。- 获取版本和基地址:攻击者可以使用
LibcSearcher库,根据泄露的__libc_start_main函数地址,找到libc库的版本和基地址。- 利用
__libc_start_main函数的特性:
__libc_start_main函数在程序启动时被调用,用于初始化libc库。- 这个函数的地址在不同版本的libc库中是不同的,且通常在程序中可以访问到。
- 原理:攻击者通过程序漏洞泄露
__libc_start_main函数的地址,然后使用LibcSearcher库根据该地址推断出libc库的版本,并计算出libc库的基地址。- 利用libc库中的特定结构体或函数:
- 一些版本的libc库中,某些特定的结构体或函数地址是固定的,或者具有可预测的偏移地址。
- 原理:攻击者可以利用这些结构体或函数地址,推断出libc库的基地址或版本。
用这个脚本有点问题。咱们靠自己,找到__libc_start_main函数的got表地址如下:
puts函数的plt表地址如下:

main函数的地址如下:

1 | |
首先, 能够找到main函数的地址为0x08048618,这个函数作为调用完函数后的返回地址,为了能够发送第二次payload。其次,使用puts函数来打印libc库中的__libc_start_main函数实际地址。因此,栈溢出覆盖的返回地址为puts函数的地址。调用函数前会将当前地址压栈,因此再写入main函数的地址,puts函数接收的参数即为libc_start_main地址。即会将libc_start_main函数在libc库中的实际地址打印出来,实现地址泄露。
这里解释两个问题:
为什么不能将puts函数的GOT表地址作为返回地址?
GOT表是用来存储函数地址的,而不是代码指令。如果把puts函数的got表地址作为返回地址,程序会尝试跳转到该地址,而GOT表中存储的只是puts函数在libc库中的实际地址,而不是可执行的代码指令。因此程序会崩溃或出现无法预料的行为。
为什么给puts函数传入的参数为libc_start_main函数的got表地址,其能打印出实际地址?
puts函数的功能是将字符串输出到标准输出。将
__libc_start_main函数的GOT地址作为参数传递给puts函数时,puts函数会将这个地址解析为一个内存地址,并尝试从这个地址开始读取内容,将其作为字符串输出。而这个got表地址指向__libc_start_main函数在libc库中的实际地址。这个实际地址会随着程序运行时的libc库基地址变化而变化。
因此,通过puts函数造成的地址泄露,能获得程序实际运行时libc库中的__libc_start_main函数地址,但是因为每次执行其都会变化,因为程序的基地址在变化。但是相对偏移地址是不会变的。因此,在反复执行exp,打印出__libc_start_main函数在libc库中的地址时,会发现其后三位是不会改变的。这里的后三位为560,那么我们可以通过这个560找到其他函数的偏移地址。这里会借助libc-database这个工具。
1 | |
可以发现,system的偏移地址为0x00048170,以及bin/sh字符串的偏移地址为0x00048170。而__libc_start_main的偏移地址为0x21560。因此我们可以通过得到的libc库中的地址,减去这个偏移地址来获得libc库的基地址。随后,第二个payload覆盖返回地址为libc库中的system地址,参数为bin/sh地址。即可获得shell。
这里存在一个问题,为什么padding为104,而不是112呢?
因为,main()函数是用户代码的入口,针对用户而言;
_start函数是系统代码的入口,是程序的真正入口。实际执行过程,会先进入_start函数。如下图:
在上述,可以看到一个堆栈平衡(栈对齐)的操作,
and esp,0FFFFFFF0h进行堆栈平衡。这个操作即将原本的值变为0,而进入这个函数时其最后一位的值为8,后面变成了0。因此在不进行_start函数而直接进入main函数时,esp的值就比原先大了8,因此栈空间就少了8。所以padding也随之修改成为104
ok~
中级ROP
主要使用一些比较巧妙的Gadgets
ret2csu
原理
在64位程序中,函数的前6个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的gadgets。这时候,我们可以利用x64下的__libc_csu_init中的gadgets。这个函数是用来对libc进行初始化操作的,而一般的程序都会调用libc函数,所以这个函数一定会存在。先来看一下这个函数(当然,不同版本的有一定的区别)
1 | |
发现一个问题,
整数溢出
介绍
在C语言中,整数的基本数据类型分为short,int,long,这三个数据类型还分为有符号和无符号,每种数据类型都有各自的大小范围,(因为数据类型的大小范围是编译器决定的,下述默认64位)
| 类型 | 字节 | 范围 |
|---|---|---|
| short int | 2bytes (word) | [0,32767]和[-32768,-1]即[0,0x7fff]和[0x8000,0xffff] |
| unsigned short int | 2bytes (word) | [0,65535] 即 [0,0xffff] |
| int | 4bytes (dword) | [0,2147483647]和[-2147483648,-1]即[0,0x7fffffff]和[0x80000000,0xffffffff] |
| unsigned int | 4bytes(dword) | [0,4294967295]即[0,0xffffffff] |
| long int | 8bytes(qword) | [0,0x7ffffffffffffffff]和[0x8000000000000000,0xffffffffffffffff] |
| unsigned long int | 8bytes(qword) | [0,0xffffffffffffffff] |
当程序中的数据超过其数据类型的范围,则会造成溢出,整数类型的溢出被称为整数溢出。
原理
上界溢出
1 | |
上界溢出有两种情况,一种是0x7fff + 1,另一种是0xffff + 1
因为计算机底层指令是不区分有符号和无符号的,数据都以二进制形式存在,编译器层面才对有符号和无符号进行区分,产生不同的汇编指令。
所以add 0x7fff, 1变成0x8000,这种上界溢出对无符号整型就没有影响,但是在有符号短整型中,0x7fff表示的是32767,但是0x8000表示的是-32768,用数学表达式来表示就是在有符号短整型中32767 + 1 -> -32768。
第二种情况是add 0xffff, 1,这种情况需要考虑的是第一个操作数。
比如上面的有符号型加法的汇编代码是add eax, 1,因为eax=0xffff,所以add eax, 1会变成0x10000,但是无符号的汇编代码是对内存进行加法运算add word ptr [rbp - 0x1a], 1会变成0x0000。
有符号的加法中,虽然eax的结果位0x10000,但是只把ax=0x0000的值存储到了内存中,从结果看和无符号是一样的。
再从数字层面看看溢出的效果,再有符号的短整型中,oxffff == -1, -1 + 1 == 0,从有符号看这种计算没问题,但是再无符号短整型中,0xffff == 65535,65535+1 == 0。
下界溢出
下界溢出的道理和上界溢出一样,在汇编代码中,只是把add替换成了sub。
第一种是sub 0x0000, 1会变成0xffff,对于有符号来说0 - 1 == -1没问题,但是对于无符号来说就成了0 - 1 == 65535。
第二种是sub 0x8000,1会变成0x7fff,对于无符号来说是32768 -1 == 32767没问题,但是对于有符号来说就成了-32768 - 1 = 32767
基本示例
未限制范围
1 | |
shell如下:
1 | |
使用gdb调试
1 | |
由于,环境不同,gcc也不同。因此可能不会出现上述size被覆盖为0xffffffffff
错误的类型转换
即使正确的对变量进行约束,也仍然有可能出现整数溢出漏洞,我认为可以概括为错误的类型转换,如果继续细分下去,可以分为:
范围大的变量赋值给范围小的变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void check(int n)
{
if (!n)
printf("vuln");
else
printf("OK");
}
int main(void)
{
long int a;
scanf("%ld", &a);
if (a == 0)
printf("Bad");
else
check(a);
return 0;
}
上述代码是一个范围大的变量(长整型a),传入check函数后变为范围小的变量(整型变量n),造成整数溢出的例子。
已经长整型的占有8byte的内存空间,而整型只有4byte的内存空间,所以当long 转换成 int,将会造成截断,只把长整型的低4 byte的值传给整型变量。
在上述例子中就是把
long:0x100000000 -> int: 0x00000000但是当范围更小的变量就能完全的把值传递给范围更大的变量,而不会造成数据丢失。
格式化字符串
原理
格式化字符串函数介绍
格式化字符串函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后的参数。通俗来说,格式化字符串函数就是将计算机内存中表示的数据转化为人类可读的字符串格式。几乎所有的C/C++程序都会利用格式化字符串函数来**输出信息,调试信息,或者处理字符串。**一般来说,格式化字符串在利用的时候主要分为三个部分
- 格式化字符串函数
- 格式化字符串
- 后续参数,可选
printf函数如下图所示:

格式化字符串函数
常见的格式化字符串函数:
- 输入
- scanf
- 输出
- printf
- fprintf
- vprintf
- vfprintf
- sprintf
- snprintf
- vsprintf
- vsnprintf
- setproctitle
- syslog
- err,verr,warn,vwarn等
格式化字符串
格式化字符串的格式,其基本格式如下:
1 | |
以下几个pattern中的对应选择需要重点关注
- parameter
- n$,获取格式化字符串中的指定参数
- flag
- field width
- 输出的最小宽度
- precision
- 输出的最大长度4
- length,输出的长度
- hh,输出一个字节
- h,输出一个双字节(word)
- type
- d/i,有符号整数
- u,无符号整数
- x/X, 16进制unsigned int。 x使用小写字母;X使用大写字母。 如果指定了精度,则输出的数字不足时在左侧补0。默认精度位1。
- o,8进制unsigned int。
- s,输出null结尾字符串,知道精度规定的上限;未指定精度则输出所有字节。
- p, void*型,输出对应变量的值。printf(“%p”,a)用地址的格式打印变量a的值,printf(“%p”,&a)打印变量a所在的地址。
- n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
- %,’%’字面值,不接受仍和flags,width
参数,就是要输出的变量。
格式化字符串漏洞原理
格式化字符串函数是根据格式化字符串来进行解析的。那么相应的要被解析的参数的个数也自然是由这个格式化字符串所控制。比如说%s表明我们会输出一个字符串参数。
以下图为例介绍

在进入printf函数的之前(即还没有调用printf),栈上的布局由高地址到低地址依次如下
1 | |
在进入printf之后,函数首先获取第一个参数,一个一个读取其字符会遇到两种情况
- 当前字符不是%,直接输出到相应标准输出
- 当前字符是%,继续读取下一个字符
- 如果没有字符,报错
- 如果下一个字符是%,输出%
- 否则根据相应的字符,获取相应的参数,对其进行解析并输出
那么printf函数写成如下:
1 | |
此时,可以发现没有给printf提供参数,程序照样会运行,会将栈上存储格式化字符串地址上面的三个变量分别解析为:
- 解析其地址对应的字符串
- 解析其内容对应的整型值
- 解析其内容对应的浮点值
利用
格式化字符串漏洞的两个利用手段
- 使程序崩溃,因为%s对应的参数地址不合法的概率比较大。
- 查看进程内容,根据%d, %f输出栈上的内容。
程序崩溃
通常来说,利用格式化字符串漏洞使得程序崩溃是最为简单的利用方式,因为我们只需要输入若干个%s即可
1 | |
这是因为栈上不可能每个值都对应了合法的地址,所以总是会有某个地址可以使得程序崩溃。这一利用,虽然攻击者本身似乎不能控制程序,但是这样可以造成程序不可用。比如说,如果远程服务有一个格式化字符串漏洞,那么可以攻击其可用性,使服务崩溃,进而使得用户不能够访问。
泄露内存
利用格式化字符串漏洞,可以获取所想要输出的内容。一般会有如下几种操作
- 泄露栈内存
- 获取某个变量的值
- 获取某个变量对应地址的内存
- 泄露任意地址内存
- 利用GOT表得到libc函数地址,进而获取libc,进而获取其他libc函数地址
- 盲打,dump整个程序,获取有用信息
泄露栈内存
例如,给定如下程序
1 | |
简单编译一下
1 | |

可以看出,编译器给了警告信息,说程序中没有给出格式化字符串的参数。接下来看一下如何获取对应的栈内存。根据C语言的调用规则,格式化字符串函数会根据格式化字符串直接使用栈上自顶向上的变量作为其参数(64位会根据其传参的规则进行获取)。这里主要介绍32位。
获取栈变量数值
首先,可以利用格式化字符串来获取栈上变量的数值。运行结果如下:

可以看到,确实得到了一些内容。为了更加细致的观察,利用GDB调试一下,验证猜想。

启动程序后,断点下在printf函数处

输入%08x.%08x.%08x

停在了第一次调用printf函数的位置。此时进入了printf函数中,栈中的第一个变量为返回地址,第二个变量为格式化字符串的地址,第三个变量为a的值,第四个变量为b的值,第五个变量为c的值,第六个变量为我们输入的格式化字符串对应的地址。继续运行程序

程序的确输出了每一个变量对应的数值,并且断在了下一个printf处

此时,由于格式化字符串为%x%x%x,所以,程序会将栈上的0xffffd070及其之后的数值分别以第一,第二,第三个参数按照int类型进行解析,分别输出。继续运行,查看结果。

确实会将栈顶的内存数据以预定的形式输出出来。
但是需要注意的是,并不是每次得到的结果都一样,因为栈上的数据会应为每次分配的内存页不同而有所不同,这是因为栈不是对内存页做初始化的。
**根据上面的方法,可以依次获得栈中的每个参数,有没有办法直接获取栈中被视为第n+1个参数的值呢?**方法如下:
1 | |
利用如下字符串,可以获取到对应的第n+1个参数的数值。为什么是第n+1个参数?因为格式化参数里面的n指的是该格式化字符串对应的第n个输出参数,那相对于输出函数来说,就是第n+1个参数。
再次以gdb调试一下。

输入换成%3$x

可以看到,获得了printf的第四个参数所对应的值.
获取栈变量对应字符串
此外,我们还可以获得栈变量对应的字符串,需要用到%s
利用%x来获取对应栈的内存,但建议使用%p,可以不用考虑位数的区别。
利用%s来获取变量所对应地址的内容,只不过有零截断
利用
%order$x来获取指定第order+1参数的值,利用%order$s来获取指定第order+1参数的对应地址的内容。
泄露任意地址内存
可以看出,上面无论是泄露栈上连续的变量,还是说泄露指定的变量值,都没能完全控制所要泄露的变量的地址。这样的泄露固然有用,可是却不够强力有效。有时候,可能想要泄露某一个libc函数的got表内容,从而得到其地址,进而获取libc版本以及其他函数的地址,这时候,能够完全控制泄露某个地址的内存就显得很重要了。
一般来说,在格式化字符串漏洞中,所读取的格式化字符串都是在栈上的(因为是某个函数的局部变量,本例中s是main函数的局部变量)。那么也就是说,在调用输出函数的时候,其实,第一个参数的值其实就是该格式化字符串的地址。
在先前的实验中,栈上的第二个变量就是格式化字符串的地址,同时该地址存储的也是”%s”格式化字符串内容。
由于可以控制该格式化字符串,如果知道该格式化字符串在输出函数调用时时第几个参数,那么就可以通过如下方式来获取某个指定地址addr的内容。
1 | |
在这里,如果格式化字符串在栈上,那么就一定确定格式化字符串的相对偏移,这是因为在函数调用的时候栈指针至少低于格式化字符串地址8字节或者16字节。
下面就是如何确定该格式化字符串为第几个参数的问题了,可以通过如下方式确定
1 | |
一般来说,重复某个字符的机器字长来作为tag,而后面会跟上若干个%p来输出栈上的内容,如果内容与前面的tag重复了,那么就有很大把握说明该地址就是格式化字符串的地址,之所以说很大把我,这是因为不排除栈上有一些临时变量也是该数值。一般情况下,极其少见,可以更换其他字符进行尝试,进行再次确认。这里利用字符’A’作为tag,程序依然是先前的示例程序。


由41414141处所在的位置可以看出格式化字符串的起始地址正好是输出函数的第5个参数,那么它是格式化字符串的第4个参数。可以测试一下

程序崩溃了,因为试图将该格式化字符串所对应的值作为地址进行解析(这是%s的作用),但是显然该值无法作为一个合法的地址被解析,所以崩溃了。
这是因为变量值不能够该程序访问,所以程序自然崩溃。如果设置一个可访问的地址呢?比如果scanf@got,结果会怎么样呢?应该自然是输出scanf对应的地址。
首先,获取scanf@got的地址,如下

利用pwntools构造payload如下:
1 | |
使用该payload确实获得的scanf的地址。发送的payload为0x804c014%4$s,格式化字符串在输出函数调用时是第5个参数,因此将这个参数换成%4$s,前面加地址就能获取指定地址的内容。
加上指定地址,需要使用pwn脚本,因为输入的地址不会被解析成地址,而是字符串。pwn脚本会将其以字节串的形式传输,那么程序会将地址保存在栈中。
覆盖内存
上面已经展示了如何利用格式化字符串来泄露内存以及任意地址内存,那么有没有可能修改栈上变量的值呢,甚至修改任意地址变量的内存?这是可行的,只要变量对应的地址可写,就可以利用格式化字符串来修改其对应的数值。这里可以想一下格式化字符串中的类型
1 | |
通过这个类型参数,再加上一些小技巧,可以达成目的。这里仍然分为两部分,一部分为覆盖栈上的变量,第二部分为覆盖指定地址的变量。
这里给出如下程序来介绍
1 | |
无论覆盖哪个地址的变量,基本上都是构造类似如下的payload
1 | |
其中…表示我们填充的内容,overwrite addr表示我们所要覆盖的地址,overwrite offset地址表示所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。所以一般来说,也是如下步骤
- 确定覆盖地址
- 确定相对偏移
- 进行覆盖
覆盖栈内存
确定覆盖地址
首先,自然是想办法知道栈变量c的地址。由于目前几乎上所有的程序都开启了ASLR保护,所以栈的地址一直在变,所以我们这里故意输出c变量的地址。
确定相对偏移
其次,我们来确定一下存储格式化字符串的地址是printf将要输出的第几个参数。这里通过之前的泄露栈变量数值的方法来进行操作。通过调试
CTF权威指南-Pwn
从源代码到可执行文件
编译原理
编译器的作用是读入以某种语言编写的程序,输出等价的用另一种语言编写的程序。编译器的结构可分为前端和后端两部分。前端是机器无关的,其功能是把源程序分解成组成要素和相应的语法结构,通过这个结构创建源程序的中间表示,同时收集和源程序相关的信息,存放到符号表中;后端则是机器相关的,其功能是根据中间表示和符号表信息构造目标程序。
编译过程可大致分5个步骤。
词法分析(Lexical analysis):读入源程序的字符流,输出为有意义的词素(Lexeme);
语法分析(Syntax analysis):根据各个词法单元的第一个分量来创建树型的中间表示形式,通常是语法树;
语义分析(Semantic analysis):使用语法树和符号表中的信息,检测源程序是否满足语言定义的语义约束,同时收集类型信息,用于代码生成、类型检查和类型转换。
中间代码生成和优化:根据语义分析输出,生成类机器语言的中间表示,如三地址码。然后对生成的中间代码进行分析和优化;
Reverse
怎么快速入门逆向工程
逆向工程是从比较底层的观点对程序运行过程进行分析的过程,我们平时遇到的C语言、Python、Java都是高级语言,它们可以被编译/解释为CPU能”看懂“的二进制汇编代码(低级语言),从而CPU可以直接执行它们,并修改CPU内部的一些变量或者是内存中的一些值,使得程序进行正常的逻辑,从而正常和用户进行交互。而我们要做的就是从这些二进制汇编中,恢复原来的加密算法或者分析程序逻辑。
CTF比赛中的逆向题是什么
CTF比赛中一般会给你一个可执行文件或其他文件,可能是C/C++写的,可能是Python写的,Java写的,C#写的….不管出什么,都得硬着头皮看下去,不懂的东西直接查,以一个简单例子介绍逆向题。
一般CTF,主办方会给一个输入东西的程序,输入东西后,程序会进行一系列加密或者取数据摘要,然后把面目全非的结果和一个常量(正确的flag进行加密或者取数据摘要后的结果)进行比较,如果两个值一样,则拿到 正确的flag,否则就是flag错误。
对于简单题,喜欢使用strcmp(input_flag, “real_flag”);这样的C语言函数进行字符串比较,注意这里并没有进行加密,所以非常简单,只要在IDA中看到了这样的代码就可以很容易察觉它进行了比较,就可以获取flag。进阶一点的题,会使用位运算中的异或(xor)!
例题:
1 | |
由于异或运算的性质,a^b=c的时候,c^b=a,是一个可逆操作,加密的时候可以异或22,解密的时候也是异或22,这是一个最基础的”对称加密算法“,因为加解密的”密钥“都是22。做题时需要分析如下情况:
- 加密是如何实现的,是否可以把加密算法搬到自己的代码上正确运行?
- 加密是否对称?加密的密钥和解密的密钥是否一样?
- 如何逆向进行加密算法,或者对ASCII码进行爆破(如果一个字节变换不会引起其他很多字节的变换,这种情况下暴力往往是非常块的)。
显然,上述对称加密算法,直接将password_enc与22按位异或即可。
1 | |